Os maiores modelos de IA podem levar meses para serem treinados nas plataformas de computação atuais. Isso é muito lento para as empresas.
AI, computação de alto desempenho e análise de dados estão crescendo em complexidade com alguns modelos, como os de linguagem grande, atingindo trilhões de parâmetros.
A arquitetura NVIDIA Hopper foi desenvolvida desde o início para acelerar essas cargas de trabalho de AI de última geração com enorme poder de computação e memória rápida para lidar com redes e conjuntos de dados em crescimento.
O Transformer Engine, parte da nova arquitetura Hopper, acelerará significativamente o desempenho e os recursos da IA e ajudará a treinar modelos grandes em dias ou horas.
Como Treinar Modelos de AI com o Transformer Engine
Modelos Transformers são a espinha dorsal dos modelos de linguagem amplamente utilizados hoje, como o BERT e o GPT-3. Inicialmente desenvolvido para casos de uso de processamento de linguagem natural, sua versatilidade está sendo cada vez mais aplicada à visão computacional, descoberta de medicamentos e muito mais.
No entanto, o tamanho do modelo continua a aumentar exponencialmente, atingindo agora trilhões de parâmetros. Isso está fazendo com que os tempos de treinamento se estendam para meses devido a grandes quantidades de computação, o que é impraticável para as necessidades de negócios.
O Transformer Engine usa precisão de ponto flutuante de 16 bits e um formato de dados de ponto flutuante de 8 bits recém-adicionado combinado com algoritmos de software avançados que acelerarão ainda mais o desempenho e os recursos da AI.
O treinamento de AI depende de números de ponto flutuante, que possuem componentes fracionários, como 3.14. Introduzido com a arquitetura NVIDIA Ampere, o formato de ponto flutuante TensorFloat32 (TF32) agora é o formato padrão de 32 bits nos frameworks TensorFlow e PyTorch.
A maioria da matemática de ponto flutuante de AI é feita usando precisão “meia” de 16 bits (FP16), precisão “única” de 32 bits (FP32) e, para operações especializadas, precisão “dupla” de 64 bits (FP64). Ao reduzir a matemática para apenas oito bits, o Transformer Engine torna possível treinar redes maiores mais rapidamente.
Quando combinado com outros novos recursos na arquitetura Hopper, como o sistema NVLink Switch, que fornece uma interconexão direta de alta velocidade entre nós, os clusters de servidores acelerados por H100 poderão treinar redes enormes que eram quase impossíveis de treinar na velocidade necessária para empresas.
Mergulhando Mais Fundo no Transformer Engine
O Transformer Engine usa software e tecnologia personalizada NVIDIA Hopper Tensor Core projetada para acelerar o treinamento de modelos construídos a partir do componente básico do modelo de AI predominante, o transformer. Esses Tensor Cores podem aplicar formatos FP8 e FP16 mistos para acelerar significativamente os cálculos de AI para transformer. As operações do Tensor Core no FP8 têm o dobro da taxa de transferência das operações de 16 bits.
O desafio para os modelos é gerenciar a precisão de forma inteligente para manter a precisão e, ao mesmo tempo, obter o desempenho de formatos numéricos menores e mais rápidos. O Transformer Engine permite isso com heurísticas personalizadas ajustadas à NVIDIA que escolhem dinamicamente entre cálculos de FP8 e FP16 e lidam automaticamente com redimensionamento e dimensionamento entre essas precisões em cada camada.
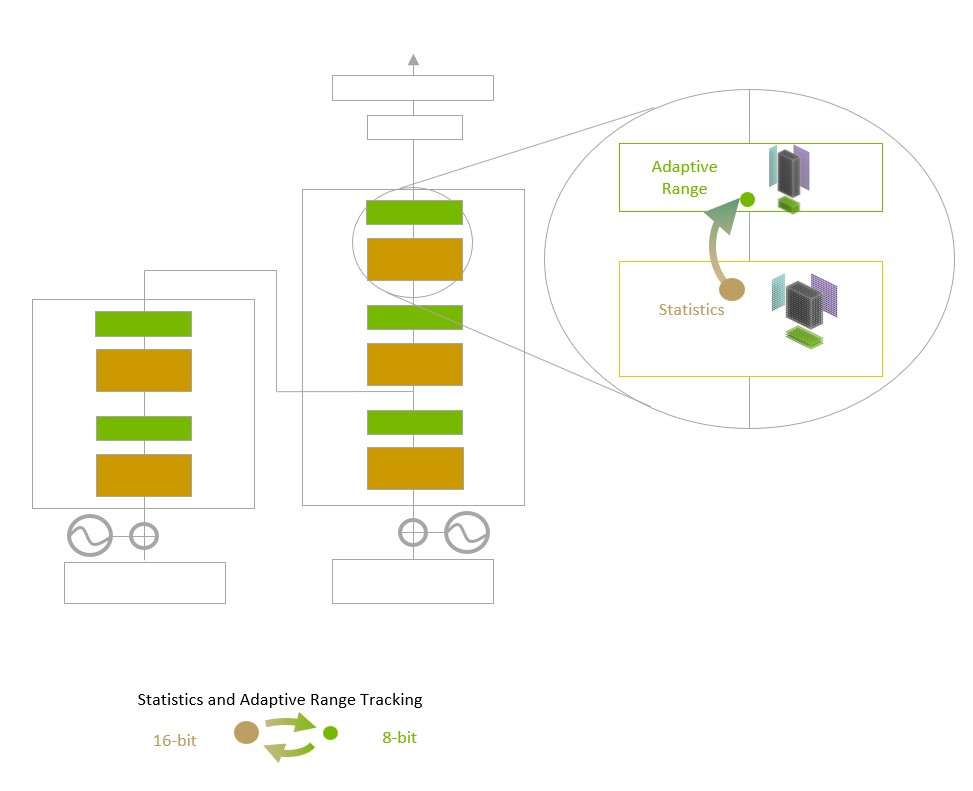
A arquitetura NVIDIA Hopper também avança os Tensor Cores de quarta geração ao triplicar as operações de ponto flutuante por segundo em comparação com as precisões TF32, FP64, FP16 e INT8 da geração anterior. Combinados com o Transformer Engine e o NVLink de quarta geração, os Hopper Tensor Cores permitem uma aceleração de ordem de magnitude para cargas de trabalho de HPC e AI.
Acelerando o Transformer Engine
Grande parte do trabalho de ponta em AI gira em torno de grandes modelos de linguagem como Megatron 530B. O gráfico abaixo mostra o crescimento do tamanho do modelo nos últimos anos, uma tendência que deve continuar. Muitos pesquisadores já estão trabalhando em mais de trilhões de modelos de parâmetros para compreensão de linguagem natural e outras aplicações, mostrando um apetite implacável pelo poder de computação da AI.
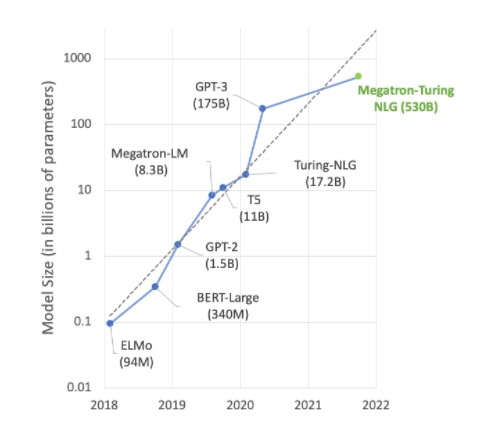
Atender à demanda desses modelos crescentes requer uma combinação de poder computacional e uma tonelada de memória de alta velocidade. A GPU NVIDIA H100 Tensor Core oferece as duas frentes, com as acelerações possibilitadas pelo Transformer Engine para levar o treinamento de AI para o próximo nível.
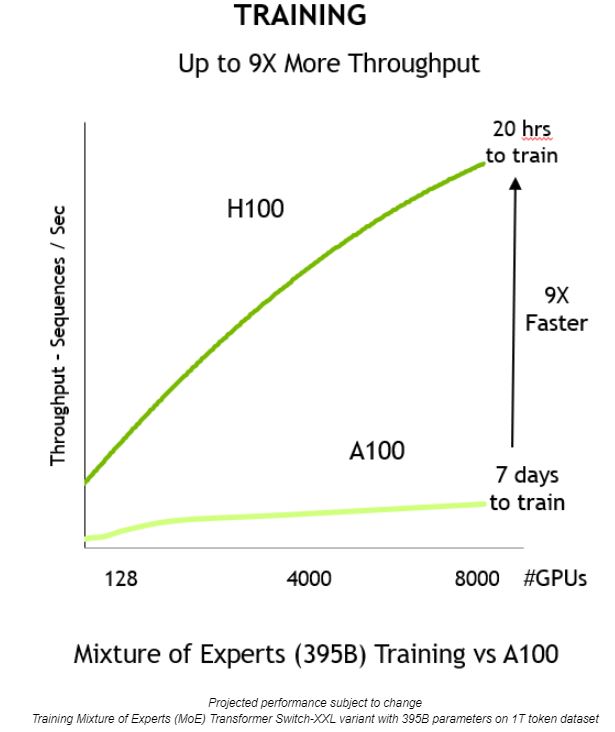
Quando combinadas, essas inovações proporcionam maior rendimento e uma redução de 9x no tempo de treinamento, de sete dias para apenas 20 horas:
O Transformer Engine também pode ser usado para inferência sem nenhuma conversão de formato de dados. Anteriormente, o INT8 era a precisão ideal para o desempenho ideal de inferência. No entanto, requer que as redes treinadas sejam convertidas para INT8 como parte do processo de otimização, algo que o otimizador de inferência NVIDIA TensorRT facilita.
O uso de modelos treinados com FP8 permitirá que os desenvolvedores ignorem essa etapa de conversão completamente e façam operações de inferência usando a mesma precisão. E, como as redes formatadas em INT8, as implantações que usam o Transformer Engine podem ser executadas em um espaço de memória muito menor.
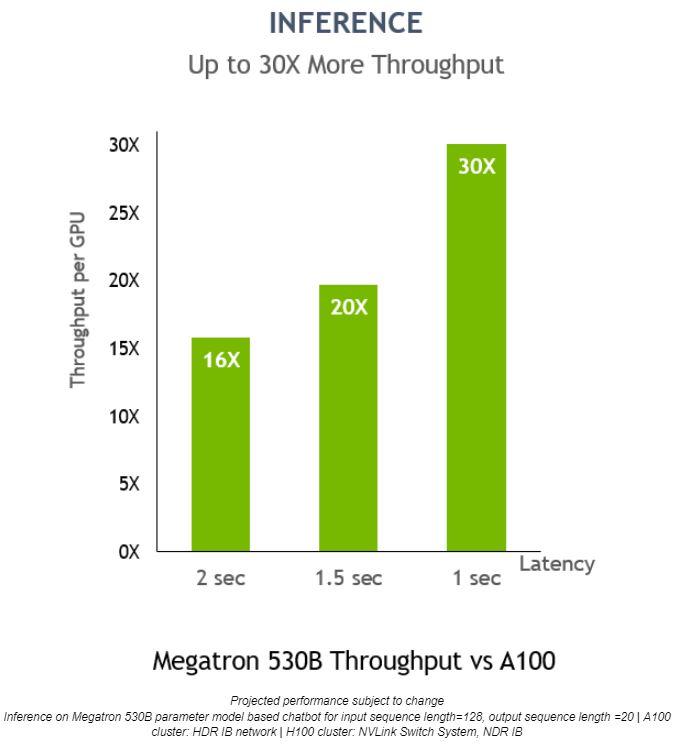
No Megatron 530B, a taxa de transferência por GPU da inferência NVIDIA H100 é até 30 vezes maior que a NVIDIA A100, com latência de resposta de 1 segundo, apresentando-a como a plataforma ideal para implementações de AI:
Para saber mais sobre a GPU NVIDIA H100 e a arquitetura Hopper, assista à apresentação de abertura do GTC 2022 de Jensen Huang. Registre-se gratuitamente no GTC 2022 para participar de sessões com a NVIDIA e líderes do setor.