Para entender o mais recente avanço na IA generativa, imagine um tribunal.
Os juízes ouvem e decidem os casos com base em sua compreensão geral da lei. Às vezes, um caso, como um processo por negligência ou uma disputa trabalhista, requer perícia especial, então os juízes enviam os funcionários do tribunal a uma biblioteca de direito, procurando precedentes e casos específicos que possam citar.
Como um bom juiz, os grandes modelos de linguagem (LLMs) podem responder a uma ampla variedade de consultas humanas. Mas para entregar respostas confiáveis que citem fontes, o modelo precisa de um assistente para fazer alguma pesquisa.
O oficial de justiça da IA é um processo chamado geração aumentada de recuperação, ou RAG para abreviar.
A História do Nome
Patrick Lewis, principal autor do artigo de 2020 que cunhou o termo, pediu desculpas pela sigla pouco lisonjeira que agora descreve uma família crescente de métodos em centenas de artigos e dezenas de serviços comerciais que ele acredita representar o futuro da IA generativa.
“Definitivamente, teríamos pensado mais no nome se soubéssemos que nosso trabalho se tornaria tão difundido”, disse Lewis em uma entrevista de Cingapura, onde estava compartilhando suas ideias com uma conferência regional de desenvolvedores de banco de dados.
“Sempre planejamos ter um nome mais bonito, mas na hora de escrever o artigo, ninguém teve uma ideia melhor”, disse Lewis, que agora lidera uma equipe de RAG na startup de IA Cohere.
Então, O Que É Geração Aumentada de Recuperação?
A geração aumentada de recuperação é uma técnica para melhorar a precisão e a confiabilidade de modelos de IA generativa com fatos obtidos de fontes externas.
Em outras palavras, preenche uma lacuna em como os LLMs funcionam. Sob o capô, LLMs são redes neurais, normalmente medidas por quantos parâmetros contêm. Os parâmetros de um LLM representam essencialmente os padrões gerais de como os seres humanos usam palavras para formar frases.
Essa compreensão profunda, às vezes chamada de conhecimento parametrizado, torna os LLMs úteis para responder a prompts gerais na velocidade da luz. No entanto, ele não atende aos usuários que desejam um mergulho mais profundo em um tópico atual ou mais específico.
Combinando Recursos Internos e Externos
Lewis e seus colegas desenvolveram a geração aumentada de recuperação para vincular serviços de IA generativa a recursos externos, especialmente aqueles ricos em detalhes técnicos mais recentes.
O artigo, com coautores da antiga Facebook AI Research (agora Meta AI), University College London e Universidade de Nova York, chamou o RAG de “uma receita de ajuste fino de propósito geral” porque pode ser usado por quase qualquer LLM para se conectar com praticamente qualquer recurso externo.
Construindo a Confiança do Usuário
A geração aumentada de recuperação fornece aos modelos fontes que eles podem citar, como notas de rodapé em um artigo de pesquisa, para que os usuários possam verificar quaisquer reivindicações. Isso gera confiança.
Além disso, a técnica pode ajudar os modelos a esclarecer a ambiguidade em uma consulta do usuário. Também reduz a possibilidade de um modelo fazer um palpite errado, um fenômeno às vezes chamado de alucinação.
Outra grande vantagem do RAG é que é relativamente fácil. Um blog de Lewis e três dos coautores do artigo disse que os desenvolvedores podem implementar o processo com apenas cinco linhas de código.
Isso torna o método mais rápido e menos dispendioso do que retreinar um modelo com conjuntos de dados adicionais. E permite que os usuários troquem novas fontes em tempo real.
Como as Pessoas Estão Usando a Geração Aumentada de Recuperação
Com a geração aumentada de recuperação, os usuários podem essencialmente ter conversas com repositórios de dados, abrindo novos tipos de experiências. Isso significa que as aplicações para RAG podem ser várias vezes o número de conjuntos de dados disponíveis.
Por exemplo, um modelo de IA generativa complementado com um índice médico pode ser um ótimo assistente para um médico ou enfermeiro. Os analistas financeiros se beneficiariam de um assistente ligado a dados de mercado.
Na verdade, quase qualquer empresa pode transformar seus manuais técnicos ou de políticas, vídeos ou logs em recursos chamados bases de conhecimento que podem aprimorar os LLMs. Essas fontes podem habilitar casos de uso, como suporte ao cliente ou de campo, treinamento de funcionários e produtividade do desenvolvedor.
O amplo potencial é o motivo pelo qual empresas como AWS, IBM, Glean, Google, Microsoft, NVIDIA, Oracle e Pinecone estão adotando o RAG.
Introdução à Geração Aumentada de Recuperação
Para ajudar os usuários a começar, a NVIDIA desenvolveu uma arquitetura de referência para geração aumentada de recuperação. Ela inclui um chatbot de exemplo e os elementos que os usuários precisam para criar suas próprias aplicações com esse novo método.
O workflow usa o NVIDIA NeMo, um framework para desenvolver e personalizar modelos de IA generativa, bem como softwares como o Servidor de Inferência NVIDIA Triton e o NVIDIA TensorRT-LLM para executar modelos de IA generativa em produção. Os usuários podem adicionar o NVIDIA Riva para criar aplicações que permitem comunicação rápida e mãos-livres.
Os componentes de software fazem parte da NVIDIA AI Enterprise, uma plataforma de software que acelera o desenvolvimento e a implantação de IA pronta para produção com a segurança, o suporte e a estabilidade de que as empresas precisam.
Obter o melhor desempenho para workflows RAG requer grandes quantidades de memória e computação para mover e processar dados. O Superchip NVIDIA GH200 Grace Hopper, com seus 288 GB de memória HBM3e rápida e 8 petaflops de computação, é ideal (ele pode oferecer uma aceleração de 150 vezes usando uma CPU).
Uma vez que as empresas se familiarizam com o RAG, elas podem combinar uma variedade de LLMs prontos ou personalizados com bases de conhecimento internas ou externas para criar uma ampla gama de assistentes que ajudam seus funcionários e clientes.
O RAG não requer um data center. Os LLMs estão estreando em PCs com Windows, graças ao software NVIDIA que permite que todos os tipos de aplicações os usuários possam acessar até mesmo em seus laptops.
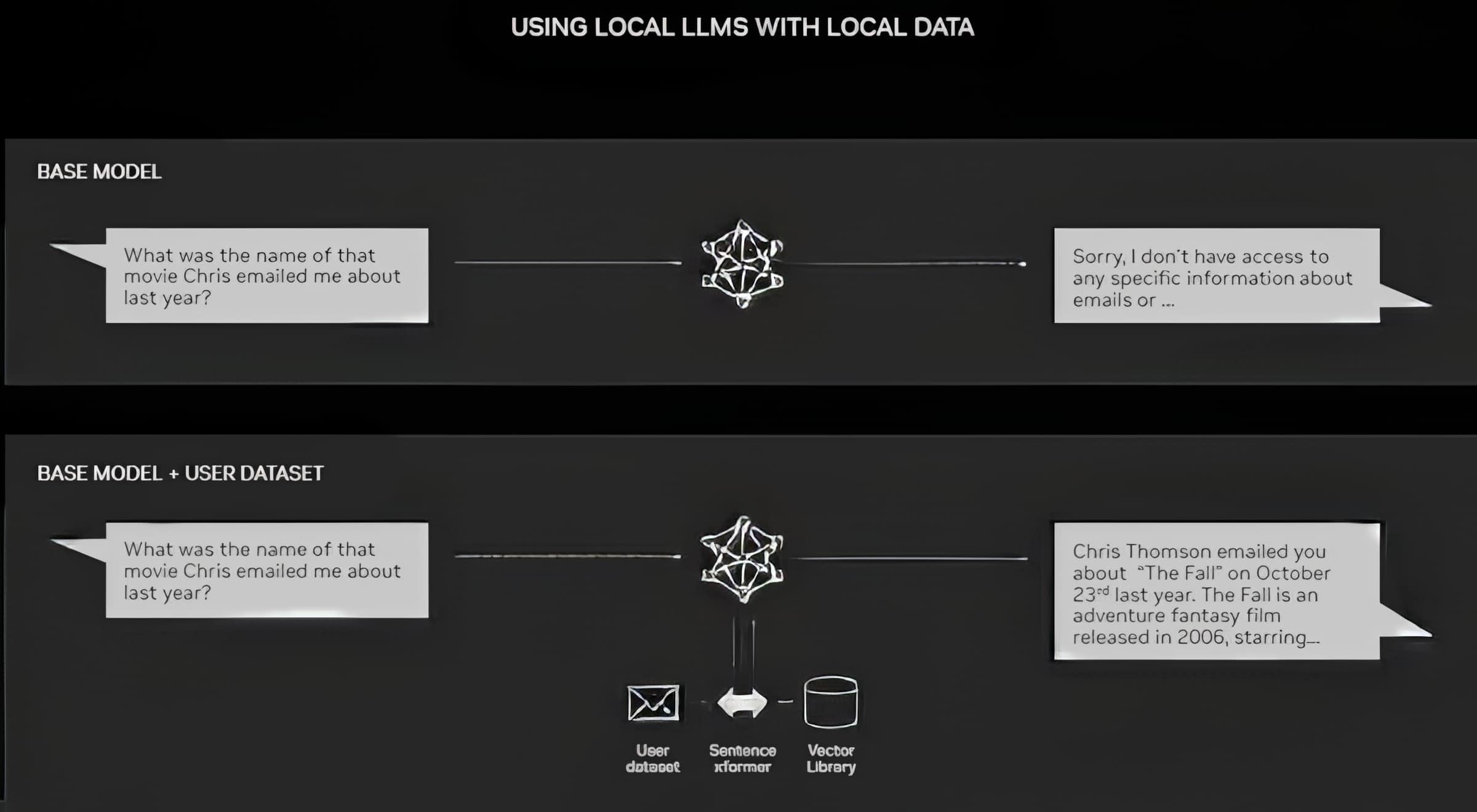
Os PCs equipados com GPUs NVIDIA RTX agora podem executar alguns modelos de IA localmente. Ao usar o RAG em um PC, os usuários podem vincular a uma fonte de conhecimento privada, sejam e-mails, notas ou artigos, para melhorar as respostas. O usuário pode então se sentir confiante de que sua fonte de dados, prompts e resposta permanecem privados e seguros.
Um blog recente fornece um exemplo de RAG acelerado pelo TensorRT-LLM para Windows para obter melhores resultados rapidamente.
A História da Geração Aumentada de Recuperação
As raízes da técnica remontam, pelo menos, ao início dos anos 1970. Foi quando pesquisadores em recuperação de informações prototiparam o que chamaram de sistemas de resposta a perguntas, aplicações que usam processamento de linguagem natural (NLP) para acessar texto, inicialmente em tópicos restritos, como beisebol.
Os conceitos por trás desse tipo de mineração de texto permaneceram bastante constantes ao longo dos anos. Mas os motores de machine learning que os impulsionam cresceram significativamente, aumentando sua utilidade e popularidade.
Em meados da década de 1990, o serviço Ask Jeeves, hoje Ask.com, popularizou a resposta a perguntas com sua mascote de um manobrista bem vestido. O Watson da IBM se tornou uma celebridade da TV em 2011, quando venceu com folga dois campeões humanos no Jeopardy! game show.
Hoje, os LLMs estão levando os sistemas de resposta a perguntas a um nível totalmente novo.
Insights de um Laboratório de Londres
O artigo seminal de 2020 chegou quando Lewis estava cursando doutorado em PNL na University College London e trabalhando para a Meta em um novo laboratório de IA de Londres. A equipe estava procurando maneiras de reunir mais conhecimento nos parâmetros de um LLM e usando um benchmark que desenvolveu para medir seu progresso.
Com base em métodos anteriores e inspirado em um artigo de pesquisadores do Google, o grupo “tinha essa visão convincente de um sistema treinado que tinha um índice de recuperação no meio dele, para que pudesse aprender e gerar qualquer saída de texto que você quisesse”, lembrou Lewis.

Quando Lewis conectou ao trabalho em andamento um promissor sistema de recuperação de outra equipe Meta, os primeiros resultados foram inesperadamente impressionantes.
“Eu mostrei ao meu supervisor e ele disse: ‘Uau, temos um vencedor. Esse tipo de coisa não acontece com muita frequência’, porque esses workflows podem ser difíceis de configurar corretamente na primeira vez”, disse ele.
Lewis também credita as principais contribuições dos membros da equipe Ethan Perez e Douwe Kiela, então da Universidade de Nova York e da Facebook AI Research, respectivamente.
Quando concluído, o trabalho, que foi executado em um cluster de GPUs NVIDIA, mostrou como tornar os modelos de IA generativa mais confiáveis. Desde então, foi citado por centenas de artigos que ampliaram e ampliaram os conceitos no que continua sendo uma área ativa de pesquisa.
Como Funciona a Geração Aumentada de Recuperação
Em alto nível, veja como um resumo técnico da NVIDIA descreve o processo RAG.
Quando os usuários fazem uma pergunta a um LLM, o modelo de IA envia a consulta para outro modelo que a converte em um formato numérico para que as máquinas possam lê-la. A versão numérica da consulta às vezes é chamada de incorporação ou vetor.
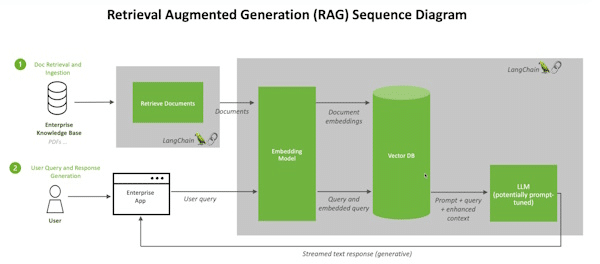
Em seguida, o modelo de incorporação compara esses valores numéricos com vetores em um índice legível por máquina de uma base de dados de conhecimento disponível. Quando ele encontra uma correspondência ou várias correspondências, ele recupera os dados relacionados, converte-os em palavras legíveis por humanos e os passa de volta para o LLM.
Finalmente, o LLM combina as palavras recuperadas e sua própria resposta à consulta em uma resposta final que apresenta ao usuário, potencialmente citando fontes que o modelo de incorporação encontrou.
Mantendo as Fontes Atualizadas
Em segundo plano, o modelo de incorporação cria e atualiza continuamente índices legíveis por máquina, às vezes chamados de bancos de dados vetoriais, para bases de conhecimento novas e atualizadas à medida que se tornam disponíveis.
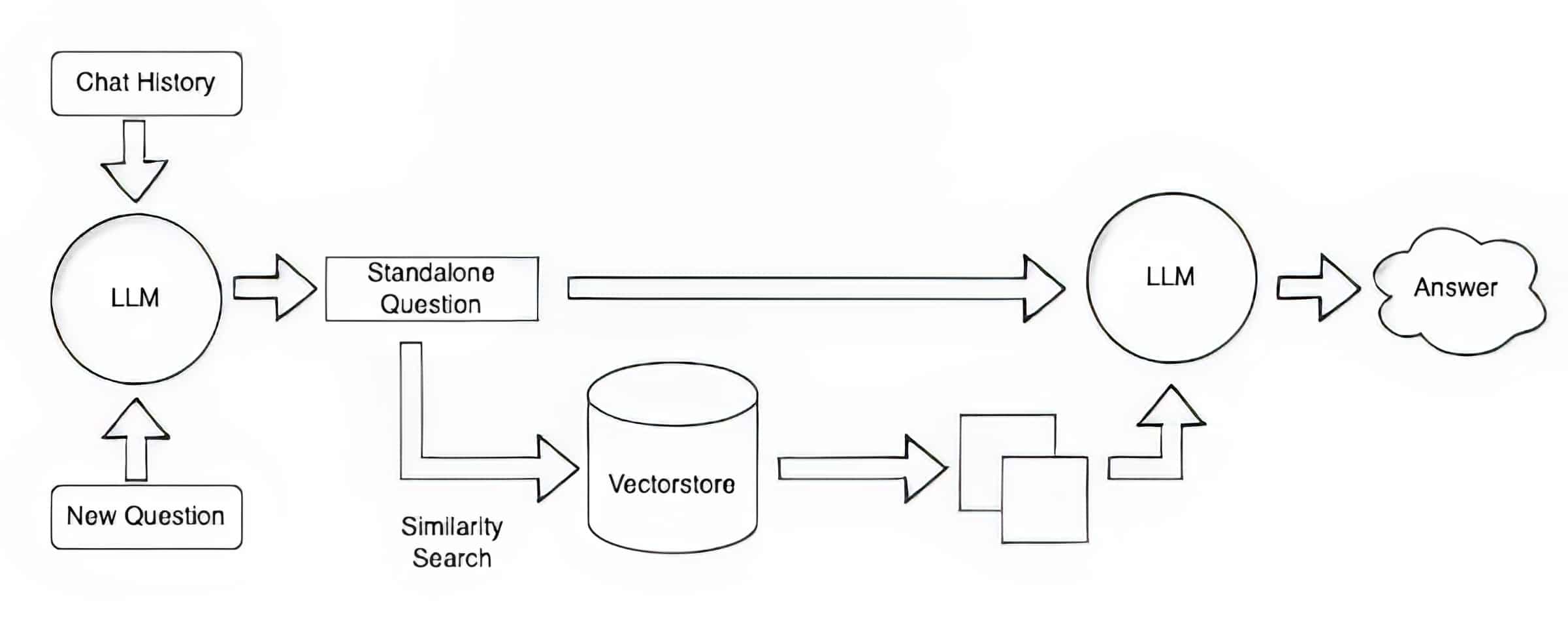
Muitos desenvolvedores acham que o LangChain, uma biblioteca de código aberto, pode ser particularmente útil para encadear LLMs, incorporar modelos e bases de conhecimento. A NVIDIA usa LangChain em sua arquitetura de referência para geração aumentada de recuperação.
A comunidade LangChain fornece sua própria descrição de um processo RAG.
Olhando para o futuro, a IA generativa está unindo criativamente todos os tipos de LLMs e bases de conhecimento para criar novos tipos de assistentes que forneçam resultados confiáveis que os usuários possam verificar.
Comece a usar a geração aumentada de recuperação com um chatbot de IA neste laboratório NVIDIA LaunchPad.