
Para que haja uma conversa de qualidade entre um humano e uma máquina, as respostas precisam ser rápidas, inteligentes e naturais.
Porém, até hoje, os desenvolvedores de redes neurais de processamento de linguagem usadas em aplicações de fala em tempo real enfrentam um triste dilema: garantir rapidez e sacrificar a qualidade da resposta ou criar uma resposta inteligente, mas com um processo muito lento.
Isso se deve ao fato de que a conversa humana é extremamente complexa. As afirmações se baseiam no contexto compartilhado e em interações anteriores. De piadas internas a referências culturais e trocadilhos, os seres humanos falam de maneira muito detalhada e sem pausa. Uma resposta segue a outra quase imediatamente. Amigos adivinham o que o outro dirá antes mesmo de as palavras serem pronunciadas.
O Que é AI Conversacional?
A verdadeira AI conversacional é um assistente de voz que pode se envolver em diálogos humanos, capturando contexto e fornecendo respostas inteligentes. Esses modelos de AI devem ser enormes e altamente complexos.
Mas quanto maior é o modelo, maior é o intervalo entre a pergunta do usuário e a resposta da AI. Intervalos maiores do que apenas três décimos de segundo podem parecer artificiais.
Com as GPUs NVIDIA, o software de conversação de AI e as bibliotecas CUDA-X de AI, modelos de linguagem massivos e de última geração podem ser rapidamente treinados e otimizados para executar inferência em apenas alguns milissegundos (milésimos de segundo) que é um grande passo para encerrar o trade-off entre um modelo de AI que é rápido e um que é grande e complexo.
Essas descobertas ajudam os desenvolvedores a construir e implantar as redes neurais mais avançadas já existentes e nos aproximar do objetivo de alcançar uma AI verdadeiramente conversacional.
Modelos de compreensão de linguagem otimizados para GPU podem ser integrados em aplicações de AI para setores como saúde, varejo e serviços financeiros, alimentando assistentes de voz digital avançados em alto-falantes inteligentes e linhas de atendimento ao cliente. Essas ferramentas de AI conversacional de alta qualidade podem permitir que empresas em todos os setores forneçam um padrão anteriormente inatingível de serviço personalizado ao interagir com os clientes.
Que Velocidade a AI Conversacional Precisa Ter?
Geralmente, a pausa entre respostas em uma conversa natural é de cerca de 300 milissegundos. Para uma AI reproduzir a interação humana, ela pode precisar executar uma dezena ou até mais redes neurais em sequência em uma tarefa com várias camadas, tudo dentro desses 300 milissegundos ou menos que isso.
Responder a uma pergunta exige várias etapas: converter a fala do usuário em um texto, entender o significado do texto, procurar a melhor resposta para oferecer no contexto e dar essa resposta com uma ferramenta de conversão de texto em fala. Cada etapa requer a execução de vários modelos de AI. Por isso, o tempo disponível para a execução de cada rede individual é de cerca de 10 milissegundos ou até menos.
Se essa execução levar mais tempo, a resposta será muito lenta, e a conversa ficará maçante e não parecerá natural.
Por causa dessa restrição tão rígida quanto à latência, os desenvolvedores das ferramentas atuais de compreensão de linguagem precisam fazer escolhas. Um modelo complexo e de alta qualidade pode ser usado como um chatbot, em que a latência não é tão essencial quanto em uma interface de voz. Os desenvolvedores também podem criar um modelo de processamento de linguagem menos volumoso que oferece resultados mais rapidamente, mas sem respostas muito variadas.
O NVIDIA Riva é um framework para desenvolvedores que criam aplicações de AI conversacional extremamente precisas que podem ser executadas muito abaixo do limite de 300 milissegundos exigido para aplicações interativas. Os desenvolvedores das empresas podem começar com modelos de última geração treinados por mais de 100 mil horas em sistemas NVIDIA DGX.
As empresas podem aplicar o transfer learning com o Kit de Ferramentas de Transfer Learning para ajustar os modelos a seus dados personalizados. Esses modelos são mais adequados para entender os termos específicos da empresa, o que aumenta a satisfação do usuário. Eles podem ser otimizados com o TensorRT, o SDK de inferência de alto desempenho da NVIDIA, e implementados como serviços que podem ser executados e dimensionados no data center. A fala e a visão podem ser usadas juntas para criar aplicações que deixam as interações com dispositivos mais naturais e parecidas com as de humanos. O Riva possibilita que todas as empresas usem uma tecnologia de AI conversacional de nível internacional que antes só especialistas em AI podiam testar.
Como Será o Futuro da AI Conversacional?
As interfaces de voz básicas, como algoritmos de interações automáticas em chamadas telefônicas (por exemplo, “Para reservar um novo voo, diga ‘reservas'”), são transacionais, exigindo uma série de etapas e respostas que conduzem os usuários em um processo pré-programado. Às vezes, só o agente humano no final da chamada consegue entender uma pergunta específica e resolver o problema do usuário de modo inteligente.
Os assistentes de voz disponíveis no mercado atualmente fazem muito mais, mas são baseados em modelos de linguagem que não são tão complexos quanto poderiam ser, com milhões em vez de bilhões de parâmetros. Essas ferramentas de AI podem gerar pausas durante a conversa, dando respostas como “Vou verificar para você” antes de responder a uma pergunta. Elas também podem exibir uma lista de resultados de uma pesquisa na Web em vez de responder a uma consulta com a linguagem de uma conversa.
Uma AI conversacional de verdade iria além disso. O modelo ideal é complexo o suficiente para entender com precisão as consultas de uma pessoa sobre os resultados de um exame médico ou extrato bancário e rápido o suficiente para responder quase que imediatamente em uma linguagem natural perfeita.
As aplicações para essa tecnologia vão desde um assistente de voz no consultório de um médico que ajuda um paciente a agendar consultas e fazer exames de sangue de acompanhamento até uma AI com voz para o varejo que explica a usuários descontentes por que uma entrega está atrasada e oferece créditos na loja.
A demanda por ferramentas avançadas de AI conversacional está aumentando: estima-se que 50% das pesquisas serão conduzidas com voz até 2020 e, até 2023, haverá 8 bilhões de assistentes de voz digitais em uso.
O Que é BERT?
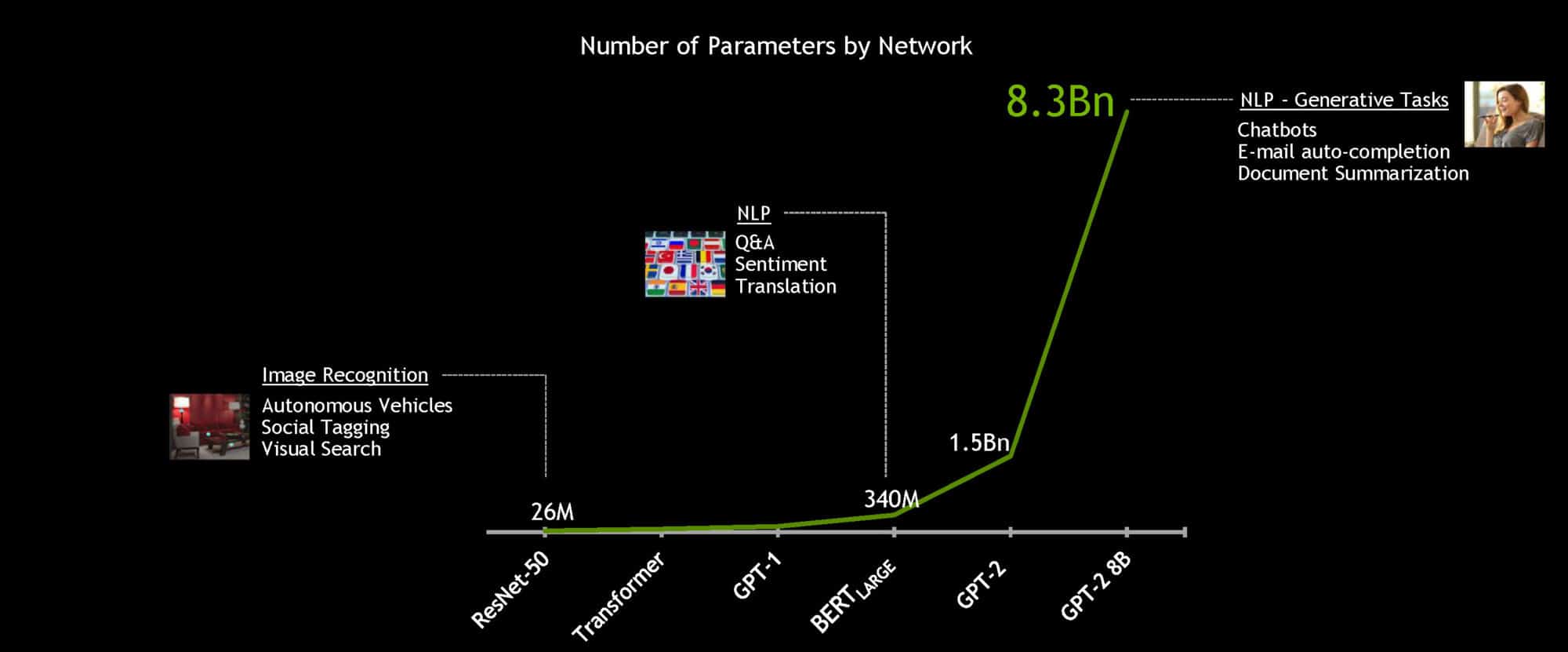
O BERT (Bidirectional Encoder Representations from Transformers) é um modelo grande e com uso intensivo de computação que definiu o cenário da compreensão de linguagem natural quando foi lançado em 2020. Com alguns ajustes, ele pode ser aplicado a várias tarefas de linguagem, como compreensão de leitura, análise de sentimentos ou perguntas e respostas.
Treinado com um corpus enorme de 3,3 bilhões de palavras em inglês, o BERT tem um desempenho excelente na compreensão de linguagem, melhor do que o de um ser humano comum em alguns casos. Seu forte é a capacidade de ser treinado com conjuntos de dados não identificados e, com poucas mudanças, fazer generalizações para diversas aplicações.
O BERT pode ser usado para entender vários idiomas e ser ajustado para realizar tarefas específicas, como tradução, preenchimento automático ou classificação de resultados de pesquisas. Essa versatilidade faz dele uma ótima opção para o desenvolvimento de compreensão da linguagem natural complexa.
Esse modelo tem como base a camada Transformer, uma alternativa às redes neurais recorrentes que aplica uma técnica de atenção, dedicando atenção às palavras mais relevantes que vêm antes e depois de uma frase em análise.
A afirmação “Há uma bomba”, por exemplo, pode referir-se a um explosivo ou a uma ferramenta de construção civil, dependendo do fim da frase: “no arsenal” ou “no canteiro de obras”. Com um método conhecido como codificação bidirecional ou não direcional, modelos de linguagem como o BERT podem usar indicações do contexto para entender melhor o significado pretendido em cada caso.
Os principais modelos de processamento de linguagem em diversos domínios no momento são baseados no BERT, como o BioBERT (para documentos biomédicos) e o SciBERT (para publicações científicas).
Como a Tecnologia da NVIDIA Otimiza Modelos Baseados no Transformer?
Os recursos de processamento paralelo e a arquitetura Tensor Core das GPUs NVIDIA proporcionam maior rendimento e escalabilidade ao usar modelos de linguagem complexos, garantindo um desempenho recorde no treinamento e na inferência do BERT.
Com o poderoso sistema NVIDIA DGX SuperPOD, o modelo BERT-Large de 340 milhões de parâmetros pode ser treinado em menos de 1 hora em vez de vários dias, que é o tempo de treinamento comum. Porém, para a AI conversacional em tempo real, a aceleração é essencial para a inferência.
Os desenvolvedores da NVIDIA otimizaram o modelo BERT-Base de 110 milhões de parâmetros para inferência usando o software TensorRT. Executado em GPUs NVIDIA T4, o modelo conseguiu calcular respostas em apenas 2,2 milissegundos quando testado com o Stanford Question Answering Dataset. Conhecido como SQuAD, o conjunto de dados é um benchmark popular usado para avaliar a capacidade do modelo de entender o contexto.
O limite de latência para muitas aplicações em tempo real é de 10 milissegundos. Até códigos de CPU extremamente otimizados geram um tempo de processamento de mais de 40 milissegundos.
Com a redução do tempo de inferência para milissegundos, pela primeira vez, é prático implementar o BERT na produção. Não é só o BERT: os mesmos métodos podem ser usados para acelerar outros modelos de linguagem natural grandes baseados no Transformer, como o GPT-2, o XLNet e o RoBERTa.
Para cumprir o objetivo de oferecer AI conversacional de verdade, é preciso aumentar o tamanho dos modelos de linguagem ao longo do tempo. Os modelos futuros serão muito maiores que os usados hoje. Por isso, a NVIDIA criou e disponibilizou a maior AI baseada no Transformer até hoje: GPT-2 8B, um modelo de processamento de linguagem de 8,3 bilhões de parâmetros que é 24 vezes maior que o BERT-Large.
Saiba Como Criar Suas Próprias Aplicações de Processamento de Linguagem Natural Baseadas no Transformer
O Deep Learning Institute da NVIDIA oferece treinamentos ministrados por instrutores sobre as ferramentas e técnicas fundamentais para a criação de modelos de processamento de linguagem natural (PLN) baseados no Transformer para tarefas de classificação de texto, como categorização de documentos. Nesse workshop detalhado de 8 horas ministrado por um especialista, os participantes poderão:
- Entender como os word embeddings evoluíram rapidamente em tarefas de PLN, desde o Word2Vec e embeddings baseados em RNNs até embeddings contextualizados baseados no Transformer.
- Ver como os recursos da arquitetura Transformer, principalmente os de autoatenção, são usados para criar modelos de linguagem sem RNNs.
- Usar a autossupervisão para melhorar a arquitetura Transformer do BERT, do Megatron e de outras variantes para resultados superiores de PLN.
- Aproveitar modelos modernos e pré-treinados de PLN para realizar várias tarefas, como classificação de texto, NER e respostas a perguntas.
- Superar os desafios da inferência e implementar modelos refinados para aplicações ativas.
Ganhe um certificado do DLI de competência no assunto para desenvolver sua carreira. Solicite um workshop para sua empresa.
Para obter mais informações sobre AI conversacional, treinamento do BERT em GPUs, otimização do BERT para inferência e outros projetos de PLN, confira o blog de Desenvolvedores NVIDIA.