
Os últimos anos testemunharam o aumento da popularidade da IA generativa e dos grandes modelos de linguagem (LLMs), como parte de uma ampla revolução da IA. À medida que as aplicações baseadas em LLM são implementadas nas empresas, é necessário determinar a eficiência de custos de diferentes soluções de atendimento de IA. O custo de uma implantação de aplicação LLM depende de quantas consultas ela pode processar por segundo, respondendo aos usuários finais e suportando um nível aceitável de precisão de resposta. Esta postagem se concentra especificamente na medição de taxa de transferência e latência do LLM como parte da avaliação dos custos da aplicação de LLM.
A NVIDIA capacita os desenvolvedores com inovações full-stack, abrangendo chips, sistemas e software. O stack de software de inferência da NVIDIA inclui os microsserviços NVIDIA Dynamo, NVIDIA TensorRT-LLM e NVIDIA NIM. Para oferecer suporte aos desenvolvedores com desempenho de inferência de benchmarking, a NVIDIA também oferece o GenAI-Perf, uma ferramenta de benchmarking de IA generativa de código aberto. Saiba mais sobre como usar o GenAI-Perf para benchmark.
A avaliação do desempenho dos LLMs pode ser realizada usando uma variedade de ferramentas. Essas ferramentas do lado do cliente oferecem métricas específicas para aplicações baseadas em LLM, mas diferem na forma como definem, medem e calculam diferentes métricas. Isso pode ser confuso e dificultar a comparação dos resultados de uma ferramenta com os resultados de outra.
Neste post, esclarecemos as métricas comuns e as diferenças sutis em como as ferramentas populares de benchmarking definem e medem essas métricas. Também discutimos os parâmetros importantes para benchmarking.
Teste de Carga e Benchmarking de Desempenho
O teste de carga e o benchmarking de desempenho são duas abordagens distintas para avaliar a implantação de um LLM. O teste de carga se concentra na simulação de um grande número de solicitações simultâneas para um modelo para avaliar sua capacidade de lidar com o tráfego do mundo real em escala. Esse tipo de teste ajuda a identificar problemas relacionados à capacidade do servidor, táticas de dimensionamento automático, latência de rede e utilização de recursos.
Por outro lado, o benchmarking de desempenho, conforme demonstrado pela ferramenta NVIDIA GenAI-Perf, se preocupa em medir o desempenho real do próprio modelo, como sua taxa de transferência, latência e métricas no nível do token. Esse tipo de teste ajuda a identificar problemas relacionados à eficiência, otimização e configuração do modelo.
Embora o teste de carga seja essencial para garantir que o modelo possa lidar com um grande volume de solicitações, o benchmarking de desempenho é crucial para entender a capacidade do modelo de processar solicitações com eficiência. Ao combinar as duas abordagens, os desenvolvedores podem obter uma compreensão abrangente de seus recursos de implantação de LLM e identificar áreas de melhoria.
Como Funciona a Inferência de LLM
Antes de examinar as métricas de benchmark, é importante entender como funciona a inferência de LLM e se familiarizar com a terminologia relacionada. Uma aplicação de LLM produz resultados por meio de estágios de inferência. Para uma determinada aplicação específica de LLM, esses estágios incluem:
- Prompt: o usuário fornece uma consulta
- Enfileiramento: a consulta ingressa na fila para processamento
- Preenchimento prévio: o modelo LLM processa o prompt
- Geração: o modelo LLM gera uma resposta, um token por vez
Um token de IA é um conceito específico para LLMs e é fundamental para as métricas de desempenho de inferência de LLM. É a unidade, ou menor entidade lingual, que os LLMs usam para decompor e processar a linguagem natural. A coleção de todos os tokens é conhecida como vocabulário. Cada LLM tem seu próprio tokenizer que é aprendido com os dados para representar o texto de entrada de forma eficiente. Como uma aproximação, para muitos LLMs populares, cada token tem ~0,75 palavras em inglês.
O comprimento da sequência é o comprimento da sequência de dados. O Comprimento da Sequência de Entrada (ISL) é quantos tokens o LLM recebe. Ele inclui a consulta do usuário, qualquer prompt do sistema (instruções para o modelo, por exemplo), histórico de bate-papo anterior, raciocínio da cadeia de pensamento (CoT) e documentos do pipeline de geração aumentada por recuperação (RAG). O Comprimento da Sequência de Saída (OSL) é quantos tokens o LLM gera. O comprimento do contexto é quantos tokens o LLM usa em cada etapa de geração, incluindo os tokens de entrada e saída gerados até esse ponto. Cada LLM tem um comprimento máximo de contexto que pode ser alocado para tokens de entrada e saída. Para um mergulho mais profundo na inferência de LLM, consulte Mastering LLM Techniques: Inference Optimization.
O streaming é uma opção que permite que saídas parciais do LLM sejam transmitidas de volta aos usuários na forma de blocos de tokens gerados de forma incremental. Isso é importante para aplicações de chatbot, onde é desejável receber uma resposta inicial rapidamente. Enquanto o usuário digere o conteúdo parcial, a próxima parte do resultado chega em segundo plano. Por outro lado, no modo sem streaming, a resposta completa é retornada de uma só vez.
Métricas de Inferência LLM
Esta seção explica algumas das métricas comuns usadas no setor, incluindo o tempo para o primeiro token e a latência entre tokens, conforme mostrado na Figura 1. Embora pareçam simples, existem algumas diferenças pequenas, mas significativas, entre as várias ferramentas de benchmarking.
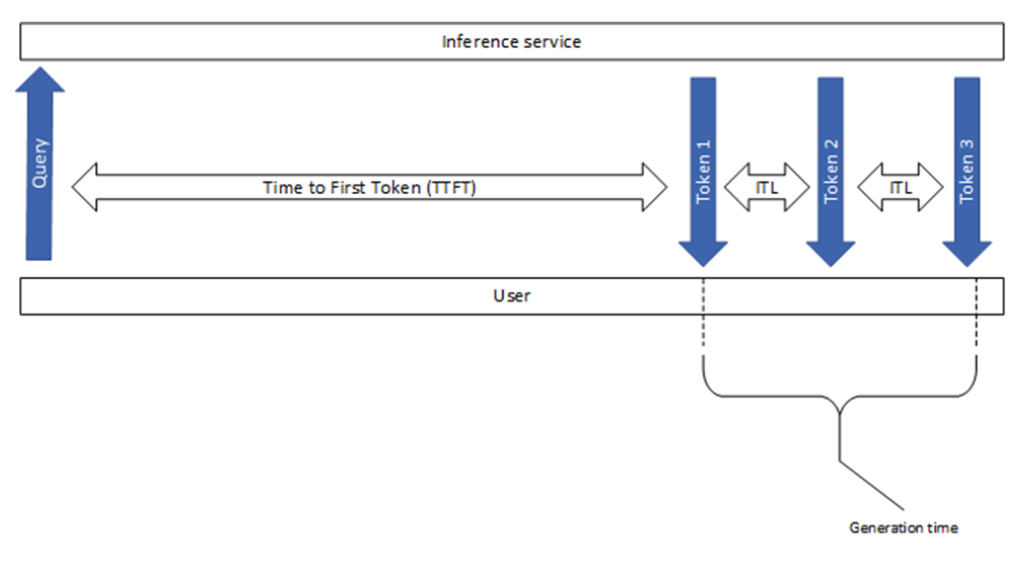
Tempo Para o Primeiro Token
O tempo para o primeiro token (TTFT) é o tempo necessário para processar o prompt e gerar o primeiro token (Figura 2). Em outras palavras, ele mede quanto tempo um usuário deve esperar antes de ver a saída do modelo.
Observe que as ferramentas de benchmarking GenAI-Perf e LLMPerf desconsideram as respostas iniciais que não têm conteúdo ou conteúdo com uma string vazia (nenhum token presente). Isso ocorre porque a medição TTFT não tem sentido quando a primeira resposta não contém nenhum token.
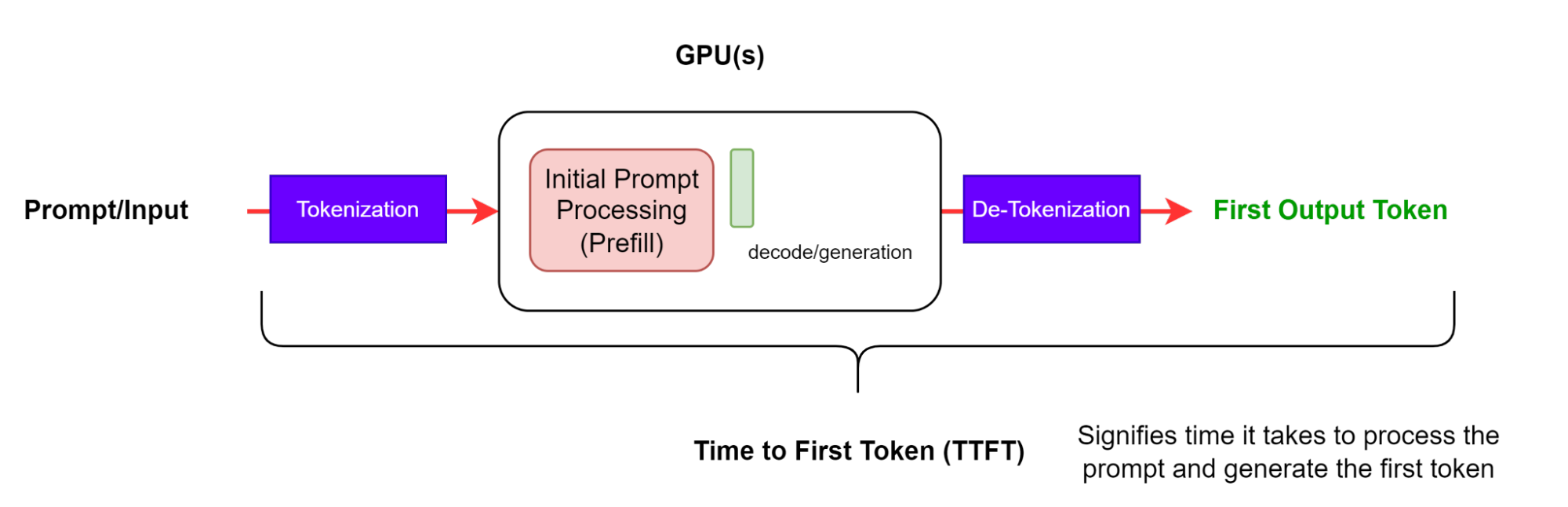
O TTFT geralmente inclui o tempo de enfileiramento de solicitações, o tempo de preenchimento prévio e a latência da rede. Quanto mais longo o prompt, maior o TTFT. Isso ocorre porque o mecanismo de atenção requer toda a sequência de entrada para calcular e criar o chamado cache de valor-chave (KV), a partir do qual o loop de geração iterativa pode começar. Além disso, uma aplicação de produção pode ter várias solicitações em andamento, portanto, a fase de preenchimento prévio de uma solicitação pode se sobrepor à fase de geração de outra solicitação.
Latência de Solicitação de Ponta a Ponta
A latência de solicitação de ponta a ponta (e2e_latency) indica o tempo que leva desde o envio de uma consulta até o recebimento da resposta completa, incluindo o tempo de enfileiramento e envio em lote e latências de rede (Figura 3). Observe que, no modo de streaming, a etapa de destokenização pode ser feita várias vezes quando os resultados parciais são retornados ao usuário.

Para uma solicitação individual, a latência de solicitação de ponta a ponta é a diferença de tempo entre o momento em que a solicitação é enviada e o token final é recebido:

Observe que generation_time é a duração desde o recebimento do primeiro token até o recebimento do token final (Figura 1). Além disso, o GenAI-Perf remove o último sinal (concluído) ou a resposta vazia, portanto, eles não são incluídos no e2e_latency.
Latência Entre Tokens
A latência intertoken (ITL) é o tempo médio entre a geração de tokens consecutivos em uma sequência. Também é conhecido como tempo por token de saída (TPOT).
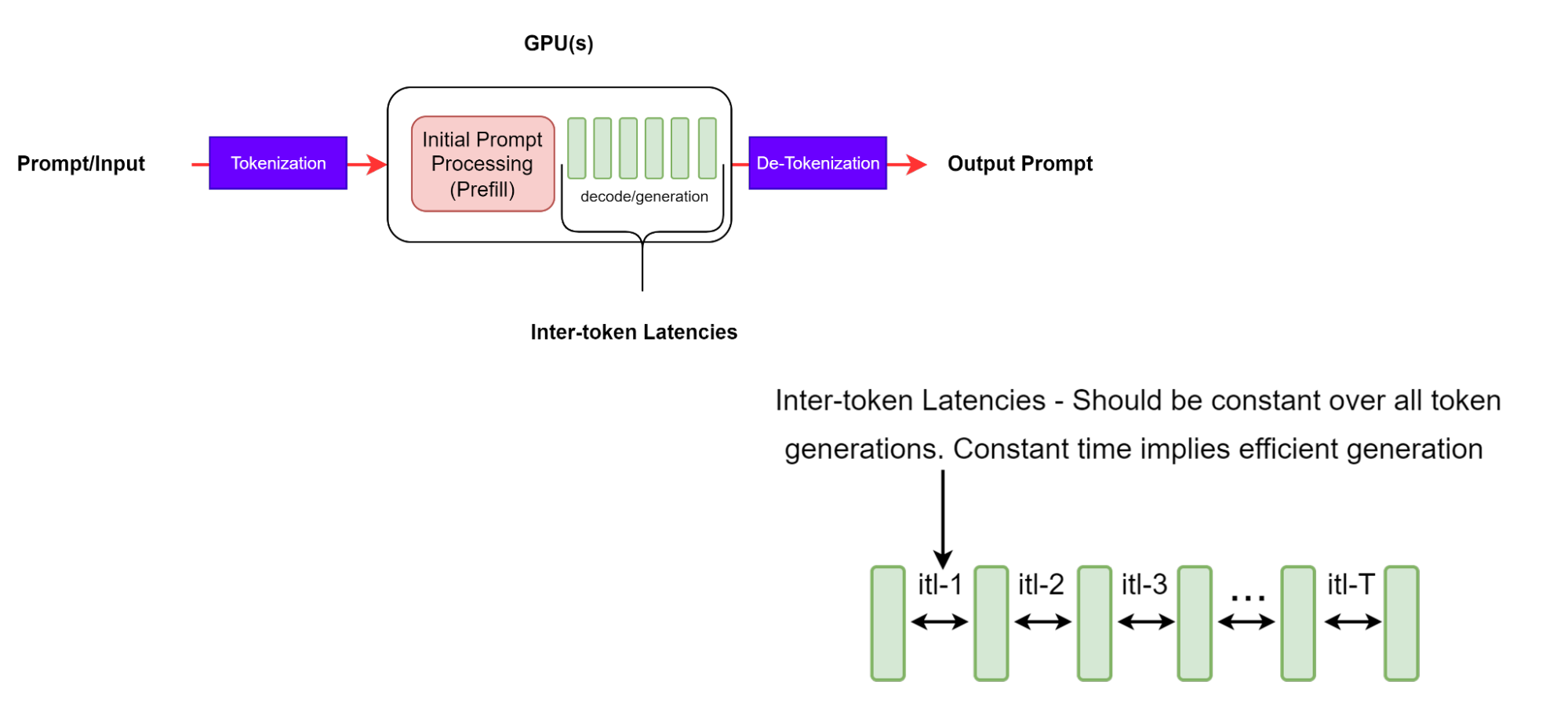
Embora esta pareça ser uma definição direta, existem algumas diferenças intrincadas em como a métrica é coletada por meio das diferentes ferramentas de benchmarking. Por exemplo, o GenAI-Perf não inclui o TTFT no cálculo médio (ao contrário do LLMPerf, que inclui o TTFT).
GenAI-Perf define ITL com a seguinte equação:

A equação usada para essa métrica não inclui o primeiro token (portanto, subtraindo 1 no denominador). Isso é feito para que a ITL seja uma característica da parte de decodificação do processamento da solicitação apenas.
É importante observar que, com sequências de saída mais longas, o cache KV cresce, portanto, o custo da memória também aumenta. O custo da computação de atenção também cresce: para cada novo token, esse custo é linear no comprimento da sequência de entrada e saída gerada até agora. No entanto, essa computação geralmente não é associada à computação. ITLs consistentes significam gerenciamento de memória eficiente e melhor largura de banda de memória, bem como computação de atenção eficiente.
Tokens Por Segundo
Tokens por segundo (TPS) por sistema representam a taxa de transferência total de tokens de saída por segundo, contabilizando todas as solicitações que ocorrem simultaneamente. À medida que o número de solicitações aumenta, o TPS total por sistema aumentará, até atingir um ponto de saturação para todos os recursos de computação de GPU disponíveis, além do qual possivelmente diminuirá.
Para o exemplo mostrado na Figura 5, suponha a linha do tempo de todo o benchmark com n solicitações totais. Os eventos são definidos da seguinte forma:
- Li: Latência de ponta a ponta da i-ésima solicitação
- T_start: Início do benchmark
- Tx: Carimbo de data/hora da primeira solicitação
- Ty: Carimbo de data/hora da última resposta da última solicitação
- T_end: Fim do benchmark

GenAI-Perf define o TPS como o total de tokens de saída dividido pela latência de ponta a ponta entre a primeira solicitação e a última resposta da última solicitação:

LLMPerf define TPS como o total de tokens de saída dividido por toda a duração do benchmark:

Como tal, o LLM-perf também inclui as seguintes despesas gerais na métrica:
- Geração de prompt de entrada
- Preparação de solicitações
- Armazenando as respostas
Em nossa observação, essas despesas gerais no cenário de simultaneidade única podem, às vezes, representar 33% de toda a duração do benchmark.
Observe que o cálculo do TPS é feito em lote e não é uma métrica em execução ao vivo. Além disso, o GenAI-Perf usa uma técnica de janela deslizante para encontrar medições estáveis. Isso significa que as medidas fornecidas serão de um subconjunto representativo das solicitações totalmente concluídas, o que significa que as solicitações de “aquecimento” e “resfriamento” não são incluídas no cálculo das métricas.
O TPS por usuário representa a taxa de transferência de uma perspectiva de usuário único e é definido como:

Essa definição é para a solicitação de cada usuário, que se aproxima assintoticamente de 1/ITL à medida que o comprimento da sequência de saída aumenta. Observe que, à medida que o número de solicitações simultâneas aumenta no sistema, o TPS total para todo o sistema aumenta, enquanto o TPS por usuário diminui à medida que a latência aumenta.
Solicitações Por Segundo
Solicitações por segundo (RPS) é o número médio de solicitações que podem ser concluídas com êxito pelo sistema em um período de 1 segundo. É calculado da seguinte forma:

Parâmetros de Benchmarking e Melhores Práticas
Esta seção apresenta alguns parâmetros de teste importantes e sua faixa de varredura, o que garante benchmarking significativo e garantia de qualidade.
Casos de Uso de Aplicações e Seu Impacto no Desempenho do LLM
Os casos de uso específicos de uma aplicação influenciarão os comprimentos de sequência (ISL e OSL), o que, por sua vez, afetará a rapidez com que um sistema digere a entrada para formar o cache KV e gerar tokens de saída. Um ISL mais longo aumentará o requisito de memória para o estágio de preenchimento prévio e, assim, aumentará o TTFT. Um OSL mais longo aumentará o requisito de memória (largura de banda e capacidade) para o estágio de geração e, assim, aumentará o ITL. É importante entender a distribuição de entradas e saídas em sua implantação de LLM para otimizar melhor a utilização do hardware.
Os casos de uso comuns e os prováveis pares ISL/OSL incluem:
- Tradução: Inclui tradução entre idiomas e código e é caracterizada por ter ISL e OSL semelhantes de aproximadamente 500 a 2000 tokens cada.
- Geração: inclui a geração de conteúdo de código, história e e-mail e conteúdo genérico por meio de pesquisa. Isso é caracterizado por ter um OSL de tokens O(1.000), muito mais longo do que um ISL de tokens O(100).
- Resumo: Inclui recuperação, solicitação em cadeia de pensamento e conversas de vários turnos. Isso é caracterizado por ter um ISL de tokens O(1000), muito mais longo do que um OSL de tokens O(100).
- Raciocínio: Modelos de raciocínio recentes geram um grande número de tokens de saída em uma abordagem explícita de raciocínio de cadeia de pensamento, autorreflexão e verificação para resolver problemas complexos, como codificação, matemática ou quebra-cabeças. Isso é caracterizado por ISL curto de tokens O(100) e um grande OSL de tokens O(1000-10000).
Parâmetros de Controle de Carga
Os parâmetros de controle de carga, conforme definido nesta seção, são usados para induzir cargas em sistemas LLM.
Simultaneidade N é o número de usuários simultâneos, cada um com uma solicitação ativa ou, equivalentemente, o número de solicitações atendidas simultaneamente por um serviço LLM. Assim que a solicitação de cada usuário recebe uma resposta completa, outra solicitação é enviada para garantir que a qualquer momento o sistema tenha exatamente N solicitações. A simultaneidade é usada com mais frequência para descrever e controlar a carga induzida no sistema de inferência.
Observe que o LLMPerf envia solicitações em lotes de N solicitações, mas há um período de drenagem em que ele aguarda a conclusão de todas as solicitações antes de enviar o próximo lote. Dessa forma, no final do lote, o número de solicitações simultâneas é reduzido gradualmente para 0. Isso difere do GenAI-Perf, que sempre garante N solicitações ativas durante todo o período de benchmarking.
O parâmetro de tamanho máximo do lote define o número máximo de solicitações que o mecanismo de inferência pode processar simultaneamente, em que batch é o grupo de solicitações simultâneas que estão sendo processadas pelo mecanismo de inferência. Isso pode ser um subconjunto das solicitações simultâneas.
Se a simultaneidade exceder o tamanho máximo do lote multiplicado pelo número de réplicas ativas, algumas solicitações terão que aguardar em uma fila para processamento posterior. Nesse caso, você pode ver um aumento no valor TTFT devido ao efeito de enfileiramento de esperar que um slot seja aberto.
A taxa de solicitação é outro parâmetro que pode ser usado para controlar a carga, determinando a taxa na qual novas solicitações são enviadas. Usar uma taxa de solicitação constante (ou estática) r significa que 1 solicitação é enviada a cada 1/r segundos, enquanto o uso de uma taxa de solicitação de Poisson (ou exponencial) determina o tempo médio entre chegadas.
GenAI-Perf suporta simultaneidade e taxa de solicitação. No entanto, recomendamos o uso de simultaneidade. Assim como acontece com a taxa de solicitação, o número de solicitações pendentes pode aumentar sem limites se a solicitação por segundo exceder a taxa de transferência do sistema.
Ao especificar as simultaneidades a serem testadas, é útil varrer um intervalo de valores, de um valor mínimo de 1 a um valor máximo não muito maior que o tamanho máximo do lote. Isso ocorre porque, quando a simultaneidade é maior que o tamanho máximo do lote do mecanismo, algumas solicitações terão que aguardar em uma fila. Portanto, a taxa de transferência do sistema geralmente satura em torno do tamanho máximo do lote, enquanto a latência continuará a aumentar constantemente.
Outros Parâmetros
Além disso, existem parâmetros relevantes de veiculação de LLM que podem afetar o desempenho da inferência, bem como a precisão do benchmark.
A maioria dos LLMs tem um token especial de fim de sequência (EOS), que significa o fim da geração. Isso indica que o LLM gerou uma resposta completa e deve parar. Sob uso geral, a inferência LLM deve respeitar esse sinal e parar de gerar mais tokens. O parâmetro ignore_eos geralmente instrui se um framework de inferência LLM deve ignorar o token EOS e continuar gerando tokens até atingir o limite max_tokens. Para fins de benchmarking, esse parâmetro deve ser definido como True, a fim de atingir o comprimento de saída pretendido e obter uma medição consistente.
Diferentes parâmetros de amostragem (como greedy, top_p, top_k e temperatura) podem ter impactos na velocidade de geração do LLM. Greedy, por exemplo, pode ser implementado simplesmente selecionando o token com o logit mais alto. Não há necessidade de normalizar e classificar a distribuição de probabilidade sobre tokens, o que economiza na computação. Qualquer que seja o método de amostragem escolhido, é uma boa prática permanecer consistente dentro da mesma configuração de benchmarking. Para obter uma explicação detalhada dos diferentes métodos de amostragem, consulte How to Generate Text: Using Different Decoding methods for Language Generation with Transformers.
Comece Agora
O benchmarking de desempenho do LLM é uma etapa crítica para garantir o desempenho e o desempenho econômico do LLM em escala. Este post discutiu as métricas e parâmetros mais importantes ao comparar a inferência de LLM. Para saber mais, confira estes recursos:
- Inferência de IA: Equilibrando Custo, Latência e Desempenho
- Como Implantar o NVIDIA NIM em 5 Minutos
- Um Guia Simples para Implantar IA Generativa com NVIDIA NIM
Explore a plataforma de Inferência de IA da NVIDIAe veja os dados mais recentes de desempenho de inferência de IA. As otimizações das bibliotecas TensorRT, TensorRT-LLM e TensorRT Model Optimizer são combinadas e disponibilizadas por meio de implantações prontas para produção usando microsserviços NVIDIA NIM.