A IA generativa tem o potencial de transformar todos os setores. Os trabalhadores humanos já estão usando grandes modelos de linguagem (LLMs) para explicar, raciocinar e resolver tarefas cognitivas difíceis. A geração aumentada de recuperação (RAG) conecta LLMs a dados, expandindo a utilidade dos LLMs, dando-lhes acesso a informações atualizadas e precisas.
Muitas empresas já começaram a explorar como a RAG pode ajudá-las a automatizar processos de negócios e extrair dados para obter insights. Embora a maioria das empresas tenha iniciado várias fases de testes alinhadas a casos de uso de IA generativa, estima-se que 90% delas não passarão da fase de avaliação em um futuro próximo. Transformar uma demonstração atraente do RAG em um serviço de produção que ofereça valor real aos negócios continua sendo um desafio.
Neste blog, descrevemos como a IA da NVIDIA ajuda você a mover aplicações RAG da fase de testes para a produção em quatro etapas.
Construindo Um Pipeline RAG Pronto para Empresas
Muitos obstáculos estão associados ao desenvolvimento e implantação de um pipeline RAG corporativo pronto para produção.
Os administradores de IT enfrentam desafios relacionados à segurança, usabilidade, portabilidade e governança de dados do LLM. Os desenvolvedores corporativos podem ter dificuldades com a precisão do LLM e a maturidade geral dos frameworks de programação do LLM. E a velocidade da inovação de código aberto é esmagadora para todos, com novos modelos de LLM e técnicas RAG aparecendo todos os dias.
Bases para Simplificar o Desenvolvimento e a Implantação do RAG de Produção
A NVIDIA ajuda a gerenciar essa complexidade, fornecendo uma arquitetura de referência para aplicações RAG nativas da nuvem de ponta a ponta. A arquitetura de referência é modular, combinando software popular de código aberto com aceleração NVIDIA. Aproveitar um conjunto abrangente de bases modulares oferece várias vantagens.
- Primeiro, as empresas podem integrar seletivamente novos componentes em sua infraestrutura existente.
- Em segundo lugar, eles podem escolher entre componentes comerciais e de código aberto para cada estágio do pipeline. As empresas são livres para selecionar os componentes certos para seus próprios casos de uso e, ao mesmo tempo, evitar o bloqueio do fornecedor.
- Finalmente, a arquitetura modular simplifica a avaliação, a observação e a solução de problemas em cada estágio do pipeline.
A Figura 1 mostra as bases essenciais para implantar um pipeline RAG.
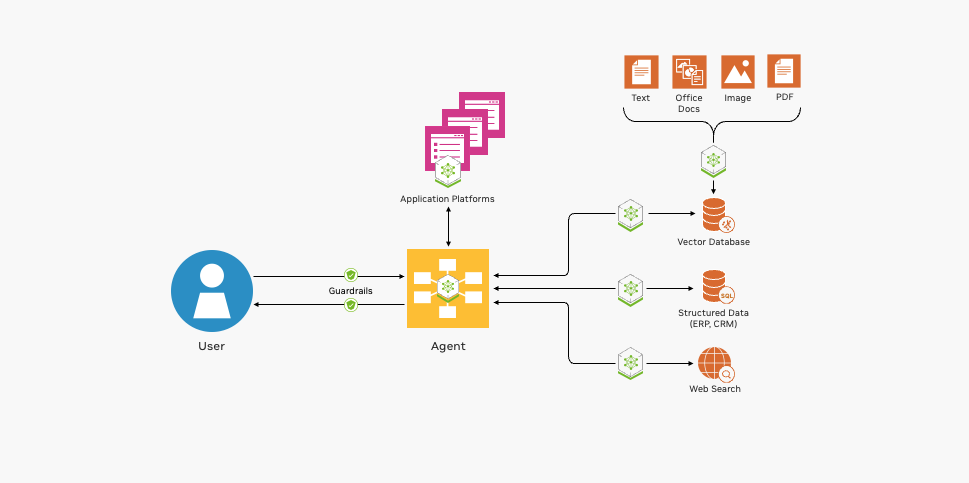
A NVIDIA oferece integração de código aberto, contêineres acelerados por GPU e muito mais para ajudar a desenvolver seus aplicativos RAG.
Integração de Código Aberto com Frameworks e Ferramentas Populares
A NVIDIA fornece pipelines de exemplo para ajudar a iniciar o desenvolvimento de aplicações RAG. Exemplos de pipeline NVIDIA RAG mostram aos desenvolvedores como combinar com pipelines de programação LLM de código aberto populares, incluindo LangChain, LlamaIndex e Haystack, com o software acelerado da NVIDIA. Usando esses exemplos como ponto de partida, os desenvolvedores corporativos podem aproveitar o melhor dos dois mundos, combinando inovação de código aberto com desempenho e escala acelerados.
Os exemplos também demonstram a integração com ferramentas populares de código aberto para avaliação, observabilidade de pipeline e ingestão de dados, tornando as operações de pipeline do segundo dia mais fáceis e econômicas.
Contêineres Acelerados por GPU para Respostas Rápidas e Precisas
As aplicações RAG corporativas com tecnologia LLM devem ser responsivos e precisos. Os sistemas baseados em CPU não podem oferecer desempenho aceitável em escala empresarial. O catálogo de API da NVIDIA inclui contêineres para impulsionar todos os estágios de um pipeline RAG que se beneficia da aceleração da GPU.
- O NVIDIA NIM oferece o melhor desempenho e escala do setor para inferência de LLM.
- O NVIDIA NeMo Retriever simplifica e acelera as funções de incorporação, recuperação e consulta de documentos no coração de um pipeline RAG.
- O NVIDIA RAPIDS acelera a pesquisa e indexação dos bancos de dados que armazenam as representações vetoriais dos dados corporativos.
Suporte para Entrada, Saída e Processamento de Dados Multimodais
As aplicações RAG estão evoluindo rapidamente de chatbots baseados em texto para workflows complexos e orientados a eventos envolvendo uma variedade de modalidades, como imagens, áudio e vídeo. O software NVIDIA AI aprimora a usabilidade e a funcionalidade dos pipelines RAG para lidar com esses casos de uso emergentes.
- O NVIDIA Riva oferece interfaces de conversão de texto em fala, fala em texto e tradução aceleradas por GPU para interagir com pipelines RAG usando linguagem falada.
- O NVIDIA RAPIDS pode acelerar ações acionadas por agentes LLM. Por exemplo, os agentes de LLM podem chamar o RAPIDS cuDF para realizar cálculos estatísticos em dados estruturados.
- O NVIDIA Morpheus pode ser usado para pré-processar grandes volumes de dados corporativos e ingeri-los em tempo real.
- O NVIDIA Metropolis e o NVIDIA Holoscan adicionam recursos de processamento de vídeo e sensor ao pipeline RAG.
Os desenvolvedores corporativos podem aproveitar o NVIDIA AI Enterprise para implantar esses componentes de software de IA para produção. O NVIDIA AI Enterprise fornece o tempo de execução mais rápido e eficiente para aplicações de IA generativa de nível empresarial.
Quatro Etapas Para Levar Sua Aplicação RAG da Fase de Testes à Produção
A criação de aplicações RAG de produção requer colaboração entre muitas partes interessadas.
- Os cientistas de dados avaliam os LLMs quanto ao desempenho e precisão.
- Os desenvolvedores de IA corporativa escrevem, testam e aprimoram aplicações RAG.
- Os engenheiros de dados conectam e transformam dados corporativos para indexação e recuperação.
- MLOps, DevOps e engenheiros de confiabilidade de site (SREs) implantam e mantêm os sistemas de produção.
A IA da NVIDIA se estende da nuvem ao silício para oferecer suporte a todos os estágios de desenvolvimento, implantação e operação de aplicações RAG. A Figura 2 mostra as quatro etapas para mover uma aplicação RAG da avaliação para a produção.
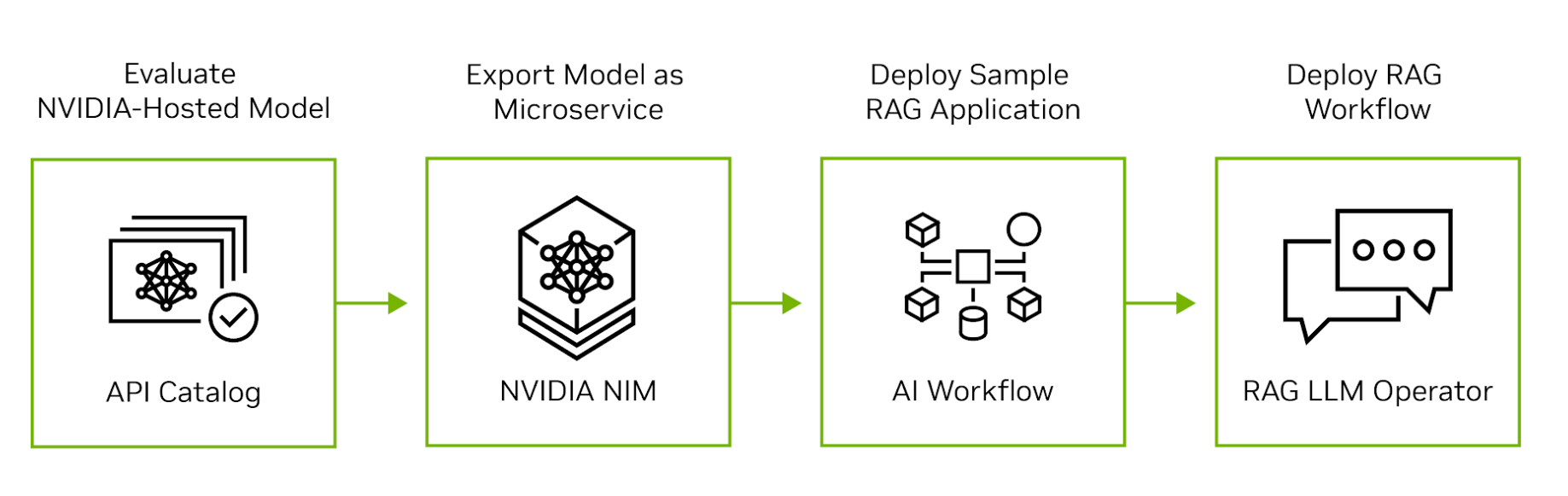
Passo 1. Avaliar LLMs no Catálogo de APIs da NVIDIA
Comece visitando o catálogo de APIs da NVIDIA para experimentar os principais modelos comerciais e de código aberto executados em GPUs NVIDIA. Os desenvolvedores podem interagir com os modelos por meio de uma interface do usuário e, em seguida, exibir as chamadas de API de back-end geradas pela interação. As chamadas de API podem ser exportadas como trechos de código Python, Go ou TypeScript ou como shell scripts.
Passo 2. Exportar Um Modelo como um Microsserviço
Em seguida, exporte um modelo como um NIM NVIDIA. Um NIM é um microsserviço auto-hospedado fácil de usar projetado para acelerar a implantação de IA generativa. O microsserviço pode ser executado como um contêiner em uma máquina virtual em qualquer nuvem principal ou pode ser instalado em um cluster Kubernetes por meio do Helm. Se você tiver preocupações sobre privacidade ou segurança de dados, poderá avaliar o modelo em seu próprio data center ou nuvem privada virtual.
Passo 3. Desenvolver uma Aplicação RAG de Exemplo
Depois de avaliar o modelo auto-hospedado, explore os Exemplos de IA Generativa da NVIDIA para escrever aplicações RAG de exemplo. Os exemplos ilustram como os microsserviços NVIDIA se integram a frameworks populares de programação LLM de código aberto para produzir pipelines RAG de ponta a ponta. Os cientistas de dados podem usar esses exemplos para ajustar o desempenho das aplicações e avaliar sua precisão. Os clientes da NVIDIA AI Enterprise também têm acesso aos workflows de IA da NVIDIA que demonstram como os exemplos de IA generativa podem ser aplicados a casos de uso específicos do setor.
Passo 4. Implantar o Pipeline RAG na Produção
Depois que a aplicação for desenvolvida, os administradores de MLOps poderão usar o operador NVIDIA RAG LLM para implantá-lo em um namespace de teste ou produção. Agora disponível para acesso antecipado, o operador RAG LLM permite a implantação rápida e fácil de aplicações RAG em clusters Kubernetes sem reescrever qualquer código da aplicação.
O operador RAG LLM é executado em cima do NVIDIA GPU Operator, um software de infraestrutura popular que automatiza a implantação e o gerenciamento de GPUs NVIDIA no Kubernetes. Ele reduz a complexidade do gerenciamento do ciclo de vida e permite a implantação, o dimensionamento e o gerenciamento contínuos de pipelines RAG.
Pipelines RAG de Produção que Aumentam a Produtividade
Os sistemas RAG de produção podem aumentar a produtividade do trabalhador reduzindo o trabalho, tornando os dados pertinentes mais fáceis de encontrar e automatizando eventos.
A NVIDIA usa um pipeline RAG para ajudar a criar software empresarial seguro. A ferramenta de análise NVIDIA CVE combina NVIDIA NIM, NeMo Retriever e o framework de IA de cibersegurança Morpheus para identificar e triar vulnerabilidades e exposições comuns (CVEs) em contêineres NGC. Esse processo de negócios crítico, que garante a integridade de todos os contêineres lançados no registro de contêineres NGC, agora leva horas em vez de dias.
Empresas como Deepset, Sandia National Laboratories, Infosys, Quantiphi, Slalom e Wipro estão desbloqueando insights valiosos com a IA generativa NVIDIA, permitindo a pesquisa semântica de dados corporativos.
A nova integração Haystack 2.0 da Deepset com NVIDIA NIM e NeMo Retriever ajuda as empresas a examinar com eficiência LLMs acelerados por GPU para oferecer suporte à prototipagem rápida de aplicações RAG.
Os Sandia National Laboratories e a NVIDIA estão colaborando para avaliar ferramentas emergentes de IA generativa para maximizar os insights de dados e, ao mesmo tempo, melhorar a precisão e o desempenho.
A Infosys expandiu sua colaboração estratégica com a NVIDIA emparelhando a Infosys Generative AI, parte do Infosys Topaz, com o NVIDIA NeMo para criar aplicações RAG prontos para empresas para vários setores. Essas aplicações interrompem as normas e agregam valor para casos de uso, desde a automação de relatórios de ensaios clínicos biofarmacêuticos até a obtenção de insights de mais de 100.000 documentos financeiros proprietários.
A Quantiphi incorpora a IA generativa acelerada da NVIDIA para desenvolver soluções baseadas em RAG que podem extrair insights de vastos repositórios de documentos de descoberta de medicamentos e ajudar a fornecer resultados inovadores, otimizando cadeias de suprimentos de varejo adaptadas à demografia e geolocalização.
A Slalom está ajudando as empresas a navegar pelas complexidades da IA generativa e do RAG, incluindo design, implementação e governança com um framework robusto para mitigar riscos e garantir a aplicação responsável da IA.
Trabalhando com ferramentas de IA generativa, a Wipro está ajudando as empresas da área de saúde a promover resultados por meio da melhor prestação de serviços a milhões de pacientes nos Estados Unidos.
Primeiros Passos
As empresas estão cada vez mais se voltando para a IA generativa para resolver desafios de negócios complexos e aumentar a produtividade dos funcionários. Muitos também incorporarão IA generativa em seus produtos. As empresas podem contar com a segurança, o suporte e a estabilidade fornecidos pelo NVIDIA AI Enterprise para mover suas aplicações RAG da fase de testes para a produção. E, ao padronizar a IA da NVIDIA, as empresas ganham um parceiro comprometido para ajudá-las a acompanhar o ritmo do ecossistema de LLM em rápida evolução.
Explore os Exemplos de IA Generativa da NVIDIA para começar a criar um chatbot que possa responder com precisão a perguntas específicas do domínio em linguagem natural usando informações atualizadas.