
Os grandes modelos de linguagem (LLM – Large Language Models) geraram entusiasmo em todo o mundo devido à sua capacidade de compreender e processar a linguagem humana em uma escala sem precedentes. Transformou a maneira como interagimos com a tecnologia.
Tendo sido treinados em um vasto corpus de texto, os LLMs podem manipular e gerar texto para uma ampla variedade de aplicações sem muita instrução ou treinamento. No entanto, a qualidade dessa saída gerada depende muito da instrução fornecida ao modelo, chamada de prompt. O que isso significa para você? Interagir com os modelos hoje é a arte de projetar um prompt, em vez de projetar a arquitetura do modelo ou os dados de treinamento.
Lidar com LLMs pode ter um custo, dada a experiência e os recursos necessários para construir e treinar seus modelos. O NVIDIA NeMo oferece modelos de linguagem pré-treinados que podem ser adaptados com flexibilidade para resolver praticamente qualquer tarefa de processamento de linguagem, enquanto podemos nos concentrar inteiramente na arte de obter os melhores resultados dos LLMs disponíveis.
Neste post, discuto algumas maneiras de contornar os LLMs, para que você possa tirar o melhor proveito deles. Para obter mais informações sobre como começar com LLMs, consulte An Introduction to Large Language Models: Prompt Engineering and P-Tuning.
Mecanismo Por Trás da Solicitação
Antes de entrar nas estratégias para gerar resultados ideais, dê um passo atrás e entenda o que acontece quando você solicita um modelo. O prompt é dividido em pedaços menores chamados tokens e enviado como entrada para o LLM, que então gera os próximos tokens possíveis com base no prompt.
Tokenização
Os LLMs interpretam os dados textuais como tokens. Tokens são palavras ou pedaços de caracteres. Por exemplo, a palavra “sanduíche” seria dividida nos tokens “sand” e “uíche”, enquanto palavras comuns como “tempo” e “gostar” seriam um único token.
O NeMo usa codificação de par de bytes para criar esses tokens. O prompt é dividido em uma lista de tokens que são considerados como entrada pelo LLM.
Geração
Nos bastidores, o modelo primeiro gera logits para cada token de saída possível. Logits são uma função que representa valores de probabilidade de 0 a 1 e de infinito negativo a infinito. Esses logits são então passados para uma função softmax para gerar probabilidades para cada saída possível, fornecendo uma distribuição de probabilidade sobre o vocabulário. Aqui está a equação softmax para calcular a probabilidade real de um token:

Na formula, 
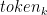


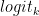
O modelo então selecionaria a palavra mais provável e a adicionaria à sequência de prompts.

Enquanto o modelo decide qual é a saída mais provável, você pode influenciar essas probabilidades girando alguns botões de parâmetro do modelo para cima e para baixo. Na próxima seção, discuto quais são esses parâmetros e como ajustá-los para obter os melhores resultados.
Ajuste os Parâmetros
Para desbloquear todo o potencial dos LLMs, explore a arte de refinar os resultados. Aqui estão as principais categorias de parâmetros a serem considerados ajustes:
- Deixe o modelo saber quando parar
- Previsibilidade vs. criatividade
- Reduzindo a repetição
Experimente esses parâmetros e descubra as melhores combinações que funcionam para seu caso de uso específico. Em muitos casos, experimentar o parâmetro de temperatura pode obter o que você precisa. Porém, se você tiver algo específico e quiser um controle mais granular sobre a saída, comece a experimentar os outros.
Deixe o Modelo Saber Quando Parar
Existem parâmetros que podem orientar o modelo para decidir quando parar de gerar qualquer texto adicional:
- Número de Tokens
- Palavras de Parada
Número de Tokens
Anteriormente, mencionei que o LLM está focado na geração do próximo token, dada a sequência de tokens. O modelo faz isso em um loop anexando o token previsto à sequência de entrada. Você não gostaria que o LLM continuasse indefinidamente.
Embora haja um limite para o número de tokens variando de 2.048 a 4.096 que os modelos NeMo podem aceitar por enquanto, não recomendo atingir esses limites, pois o modelo pode gerar respostas erradas.
Palavras de Parada
Palavras de parada são um conjunto de sequências de caracteres que informam ao modelo para parar de gerar qualquer texto adicional, mesmo que o comprimento de saída não tenha atingido o limite de token especificado.
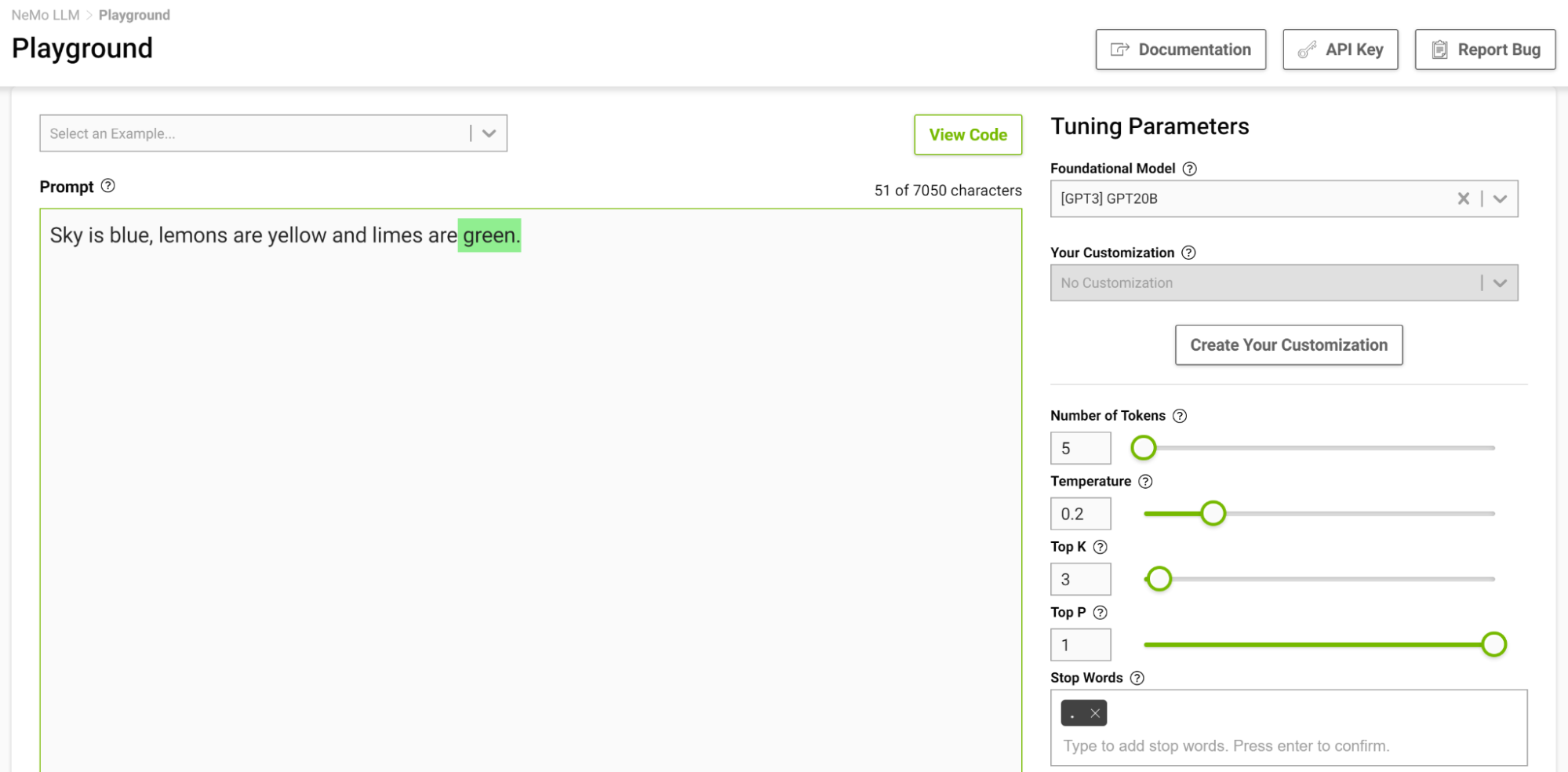
Esta é outra maneira de controlar o comprimento da saída. Por exemplo, se o modelo for solicitado a completar a seguinte frase “O céu é azul, os limões são amarelos e as limas são” e você especificar a palavra de parada apenas como “.”, o modelo parará após terminar apenas esta frase, mesmo que o token limite é maior que a sequência gerada (Figura 2).
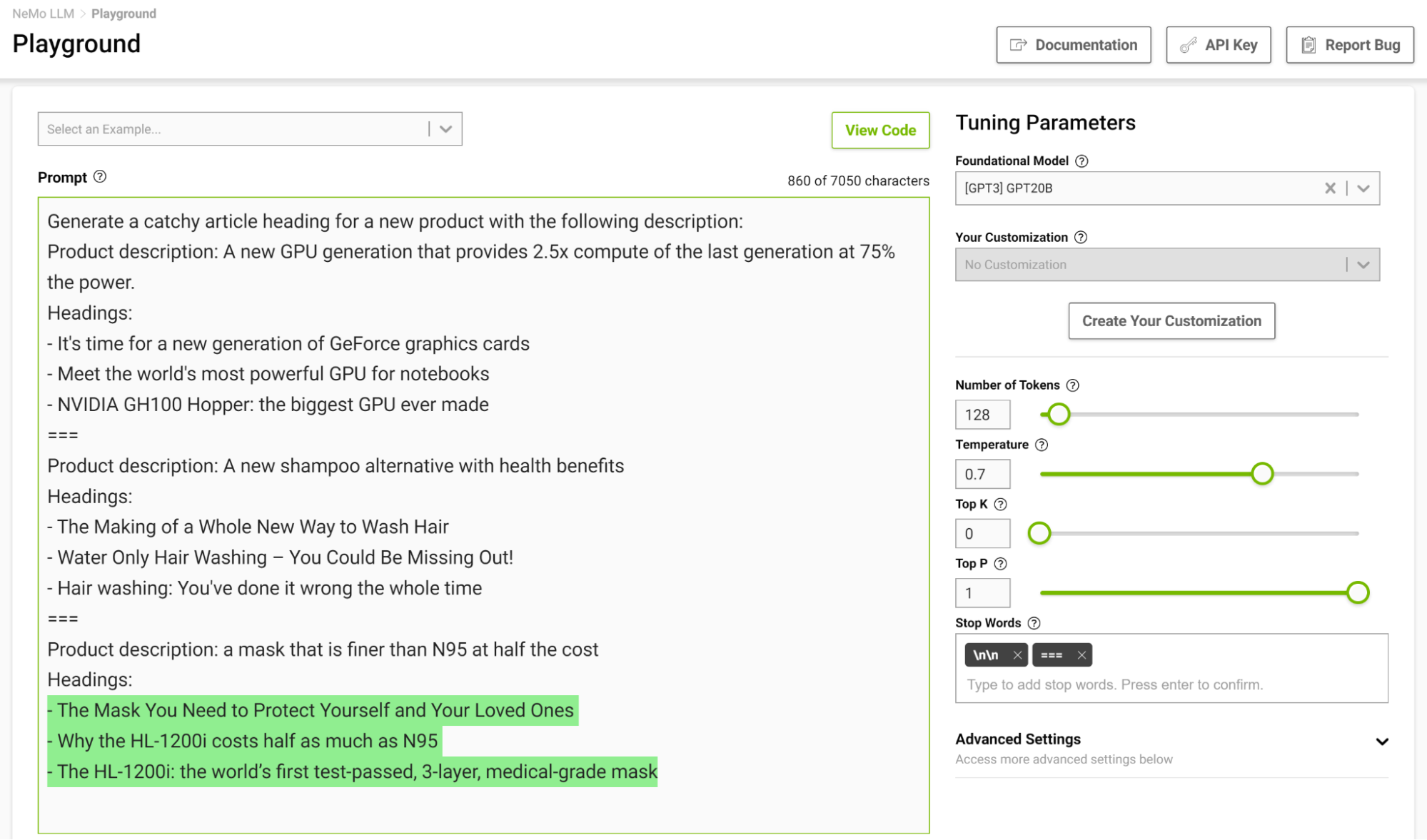
É especialmente útil projetar um modelo de parada em uma configuração de poucas tomadas para que o modelo possa aprender a parar adequadamente ao concluir a tarefa pretendida. A Figura 3 mostra a separação de exemplos com a string “===” e a passagem como palavra de parada.
Previsibilidade vs. Criatividade
A partir de um prompt, é possível gerar diferentes saídas com base nos parâmetros que você definir. Com base na aplicação do LLM, você pode optar por aumentar ou diminuir a capacidade criativa do modelo. Aqui estão alguns desses parâmetros que podem ajudá-lo a fazer isso:
- Temperatura
- Top-k e Top-p
- Amplitude de pesquisa do feixe
Temperatura
Este parâmetro controla a capacidade criativa do seu modelo. Conforme discutido anteriormente, ao gerar o próximo token na sequência de entrada, o modelo apresenta uma distribuição de probabilidade. O parâmetro temperatura ajusta o formato dessa distribuição, gerando mais diversidade no texto gerado.
Em uma temperatura mais baixa, o modelo é mais conservador e limita-se a escolher tokens com probabilidades mais altas. À medida que a temperatura aumenta, esse limite fica mais brando, permitindo que o modelo escolha palavras menos prováveis, resultando em um texto mais imprevisível e criativo.
A Figura 4 mostra a tarefa do modelo para completar a frase começando com “O oceano”, onde você define a temperatura para 0,1.
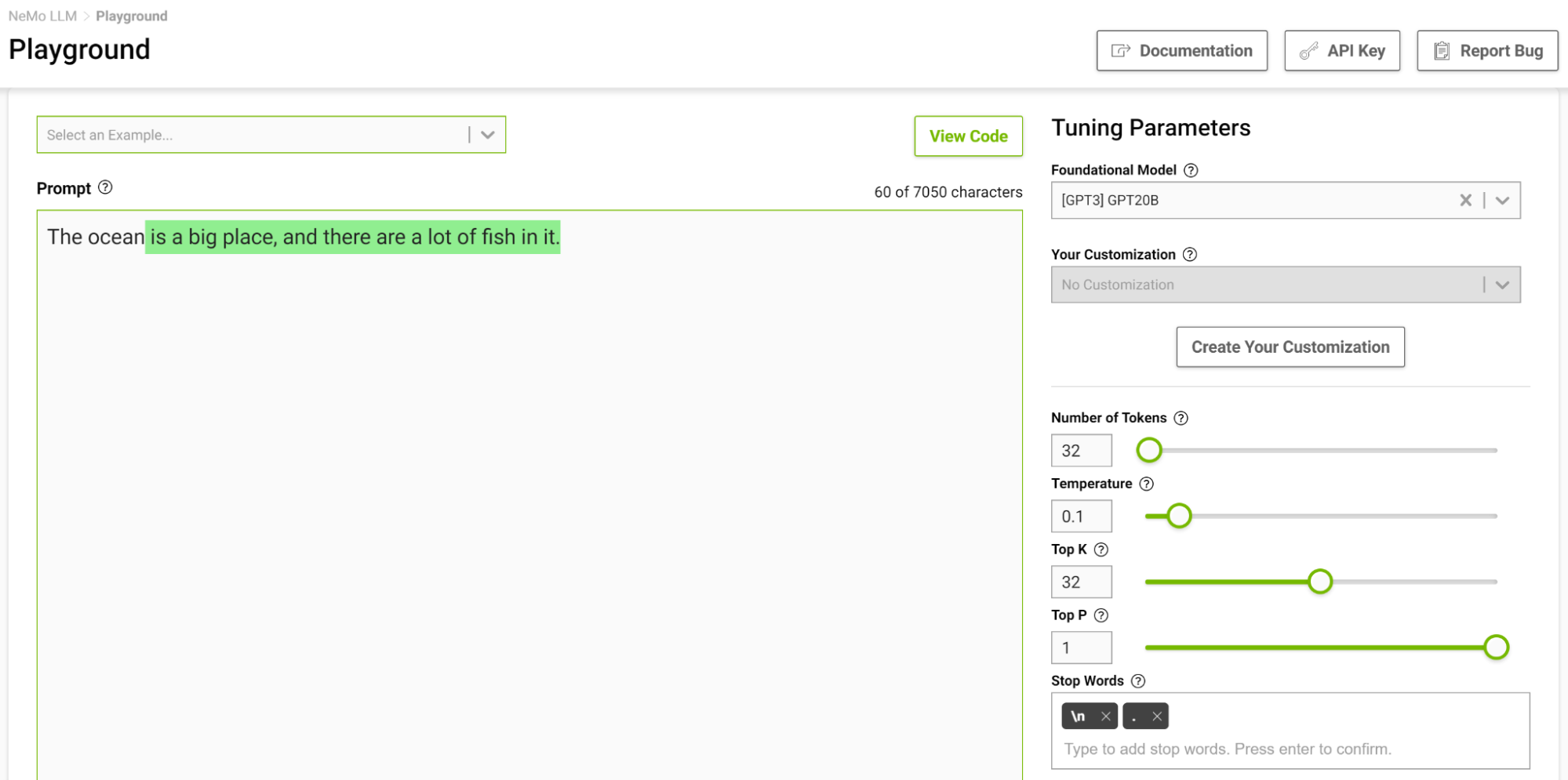
Quando você pensa em completar tal frase, provavelmente pensaria em frases como “…é enorme” ou “…é azul”. O resultado é basicamente o simples fato de que o oceano é grande e cheio de peixes.
Agora, tente novamente com a configuração de temperatura em 1 (Figura 5).
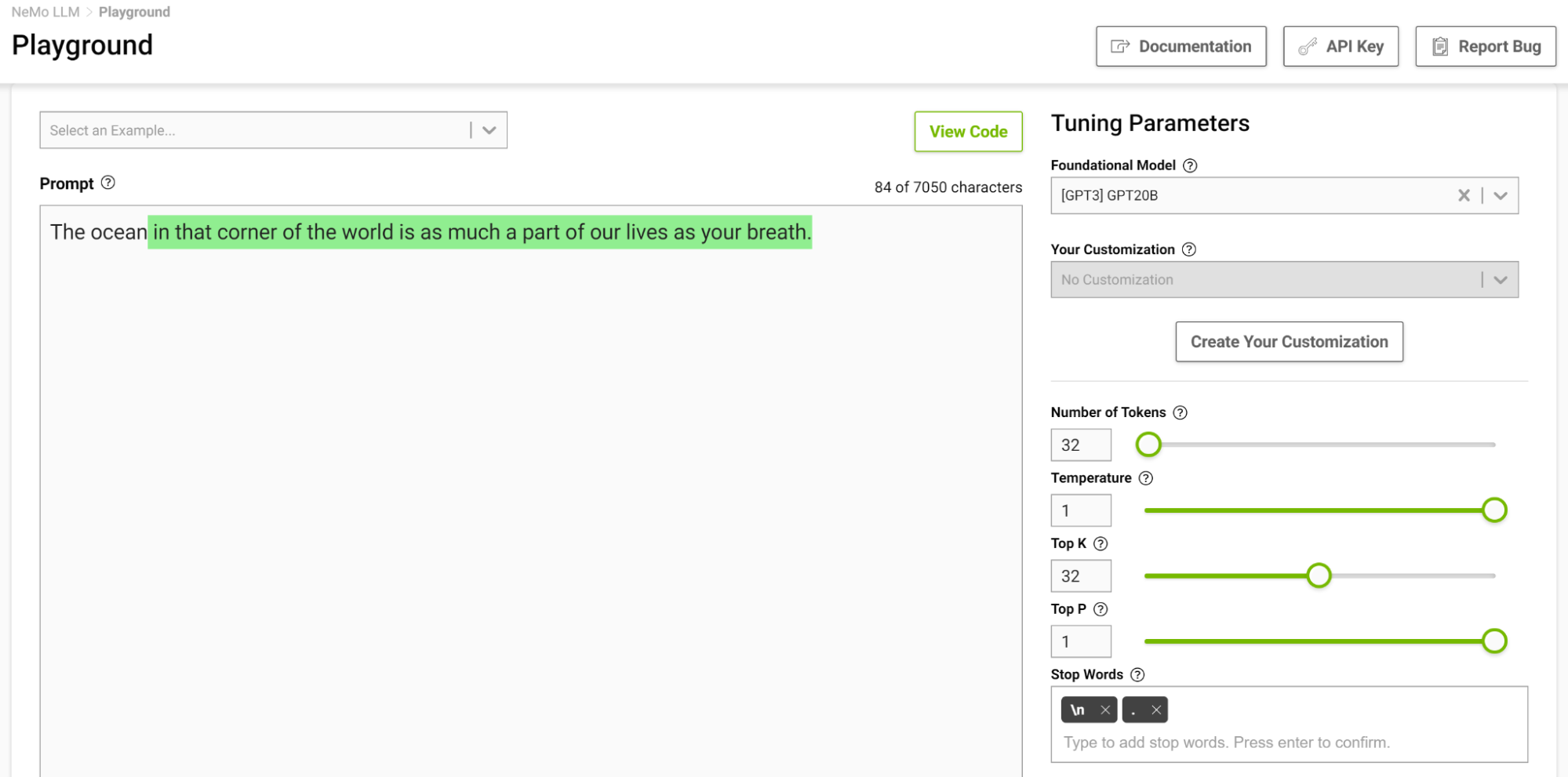
O modelo começou a oferecer analogias nas quais você normalmente não pensa. Temperaturas mais altas são adequadas para tarefas que exigem escrita criativa, como poemas e histórias. Mas tome cuidado, pois o texto gerado às vezes também pode ficar sem sentido. Temperaturas mais baixas são adequadas para tarefas mais definitivas, como resposta a perguntas ou resumos.
Recomendo experimentar diferentes valores de temperatura para encontrar a melhor temperatura para seu caso de uso. O intervalo [0,5, 0,8] deve ser um bom ponto de partida no playground do serviço NeMo.
Top-k e Top-p
Esses dois parâmetros também controlam a aleatoriedade da seleção do próximo token. Top-k informa ao modelo que ele deve manter os k tokens de maior probabilidade, dos quais o próximo token é selecionado aleatoriamente. Valores mais baixos reduzem a aleatoriedade, pois você corta tokens menos prováveis, gerando texto previsível. Se k for definido como 0, Top-k não será usado. Quando definido como 1, sempre selecionará o próximo token mais provável.
Pode haver casos em que a distribuição de probabilidade para o token possível pode ser ampla, onde há tantos tokens prováveis. Também pode haver casos em que a distribuição é estreita, onde há apenas alguns tokens mais prováveis.
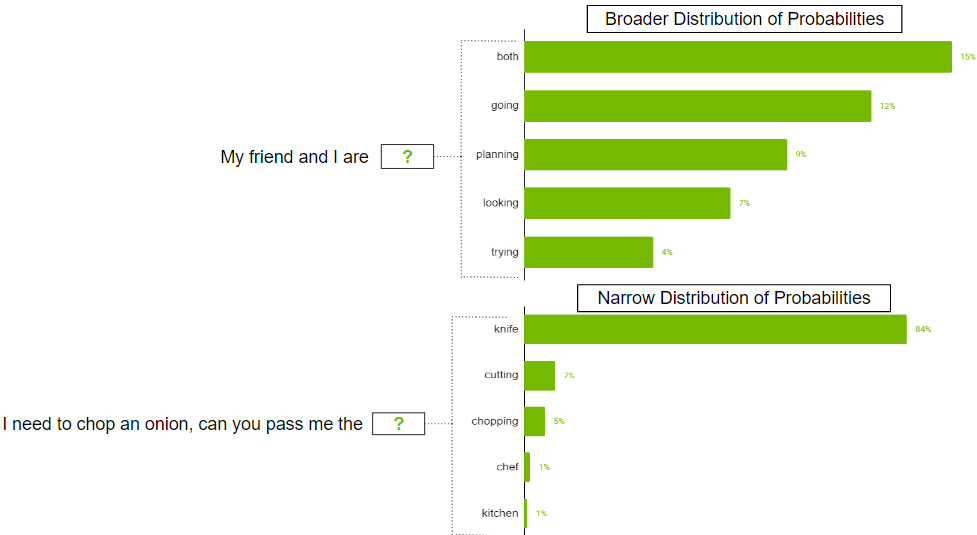
Você provavelmente não deseja restringir estritamente o modelo para selecionar apenas os k principais tokens no cenário de distribuição mais amplo. Para resolver isso, o parâmetro top-p pode ser usado onde o modelo escolhe aleatoriamente entre os tokens de maior probabilidade cujas probabilidades somam ou excedem o valor top-p. Se top-p estiver definido como 0,9, um dos seguintes cenários poderá ocorrer:
- No exemplo de distribuição mais ampla, pode-se considerar os 50 principais tokens cuja soma de probabilidades seja igual ou superior a 0,9.
- No cenário de distribuição estreita, você pode exceder 0,9 apenas com os dois primeiros tokens. Dessa forma, você evita escolher fichas aleatórias, ao mesmo tempo que preserva a variedade.
Amplitude de Pesquisa do Feixe
Este é outro parâmetro útil que pode controlar a diversidade de resultados. A pesquisa de feixe é um algoritmo comumente usado em muitos modelos de PNL e reconhecimento de fala como uma etapa final de tomada de decisão para escolher o melhor resultado, dadas as opções possíveis. A amplitude de busca do feixe é um parâmetro que determina o número de candidatos que o algoritmo deve considerar em cada etapa da busca.
Valores mais altos aumentam a chance de encontrar um bom resultado, mas isso também custa mais computação.
Reduzindo a Repetição
Às vezes, o texto repetido pode não ser desejável na saída. Se for esse o caso, use o parâmetro de penalidade de repetição para ajudar a reduzir a repetição.
Penalização por repetição
Este parâmetro pode ajudar a penalizar os tokens com base na frequência com que ocorrem no texto, incluindo o prompt de entrada. Um token que já apareceu cinco vezes é penalizado mais pesadamente do que um token que apareceu apenas uma vez. Um valor 1 significa que não há penalidade e valores maiores que 1 desencorajam tokens repetidos.
Estratégias Rápidas para um Design de Alerta Eficaz
O design imediato é crucial para gerar resultados relevantes e coerentes dos LLMs. Ter estratégias para um design de prompts eficaz pode ajudar a criar prompts relevantes, evitando armadilhas comuns como preconceito, ambiguidade ou falta de especificidade. Nesta seção, compartilho algumas estratégias importantes para um design de prompt eficaz.
Solicitar com Restrições
Restringir o comportamento do modelo por meio de um design cuidadoso de prompts pode ser bastante útil. Você sabe que os modelos de linguagem em sua essência tentam prever a próxima palavra em uma sequência. Uma descrição de tarefa que faça todo o sentido para um ser humano pode não ser compreendida pelo modelo de linguagem. É por isso que o aprendizado rápido geralmente funciona bem: conforme você demonstra um padrão para o modelo, ele faz um bom trabalho aderindo a ele.
Considere a seguinte solicitação: “Traduza do inglês para o francês: hoje é um lindo dia”.
Com esse prompt, o modelo provavelmente tentaria continuar a frase ou adicionar mais frases em vez de realizar a tradução. Alterando o prompt para “Traduza esta frase em inglês para francês: hoje é um lindo dia.” aumenta a probabilidade de o modelo entender esta tarefa como uma tarefa de tradução e gera uma saída mais confiável.
Caracteres São Importantes!
Como você viu no exemplo de tradução anterior, pequenas alterações podem levar a resultados variados. Outra coisa a observar é que os tokens geralmente são gerados com um espaço à esquerda, portanto, caracteres como espaço e próxima linha também podem afetar suas saídas. Se um prompt não estiver funcionando, tente mudar a forma como você o estruturou.
Considere Certas Frases
Freqüentemente, quando você deseja que seu modelo responda logicamente às suas solicitações e chegue a conclusões precisas ou simplesmente faça com que o modelo alcance um determinado resultado, você pode considerar o uso das seguintes frases:
- Vamos pensar nisso passo a passo: isso incentiva o modelo a abordar um problema de forma lógica e a chegar a respostas precisas. Esse estilo de estímulo também é conhecido como promoção de cadeia de pensamento (CoT).
- No estilo de <pessoa notável>: corresponde ao estilo de escrita da pessoa notável. Por exemplo, para gerar texto como Shakespeare ou Edgar Allen Poe, adicione-o ao prompt e a geração corresponderá ao seu estilo de escrita.
- Como <profissão/função>: Isso ajuda o modelo a entender melhor o contexto da questão. Com uma melhor compreensão, o modelo geralmente dá melhores respostas.
Prompt com Conhecimento Gerado
Para obter respostas mais precisas, você pode solicitar ao LLM que gere conhecimento potencialmente útil sobre uma determinada pergunta antes de gerar uma resposta final (Figura 7).

Esse tipo de erro mostra que os LLMs às vezes exigem mais conhecimento para responder a uma pergunta. Os próximos exemplos mostram a geração de alguns fatos sobre pontuação de golfe em um cenário de poucas tacadas.
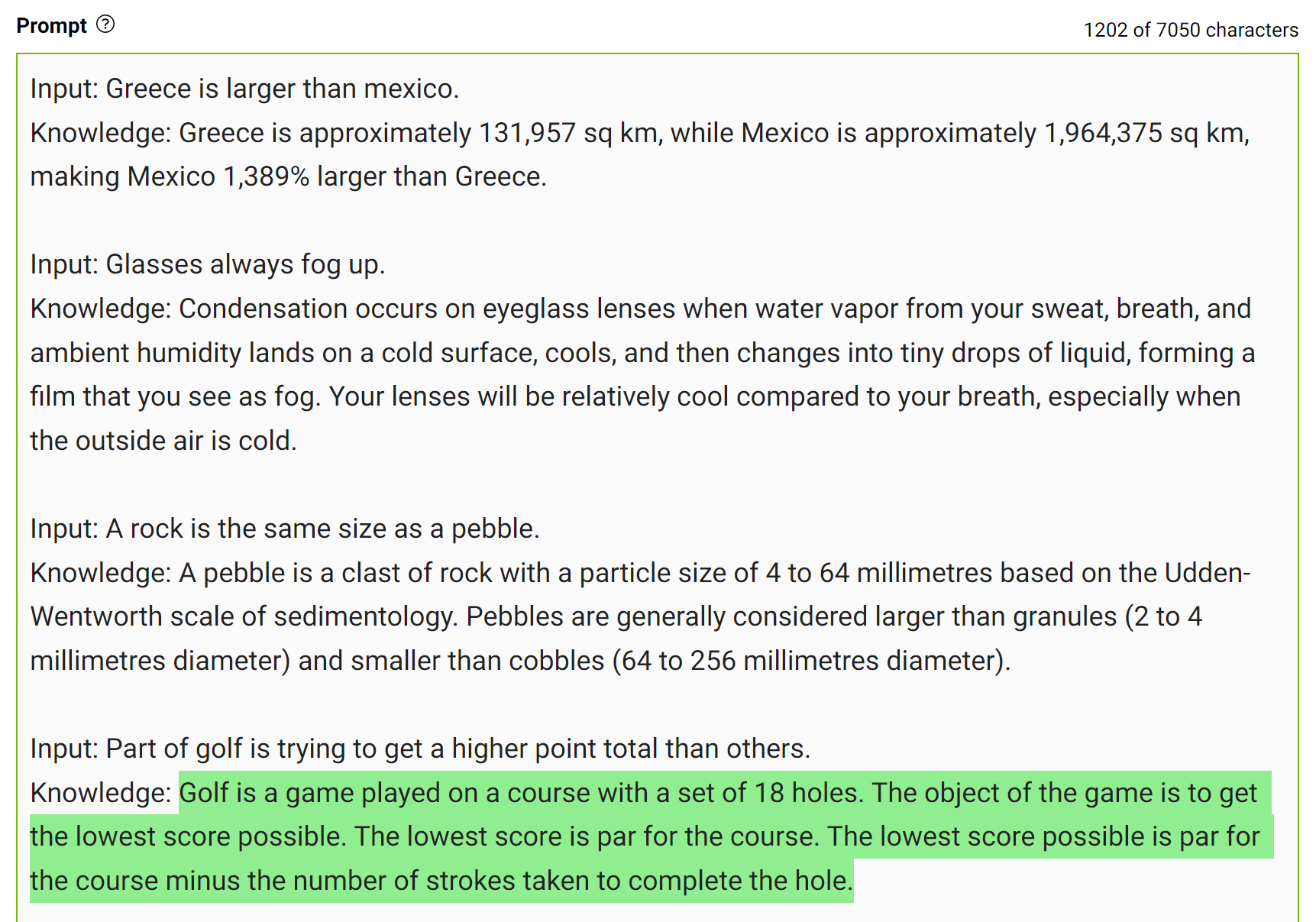
Integre esse conhecimento ao prompt e faça a pergunta novamente.
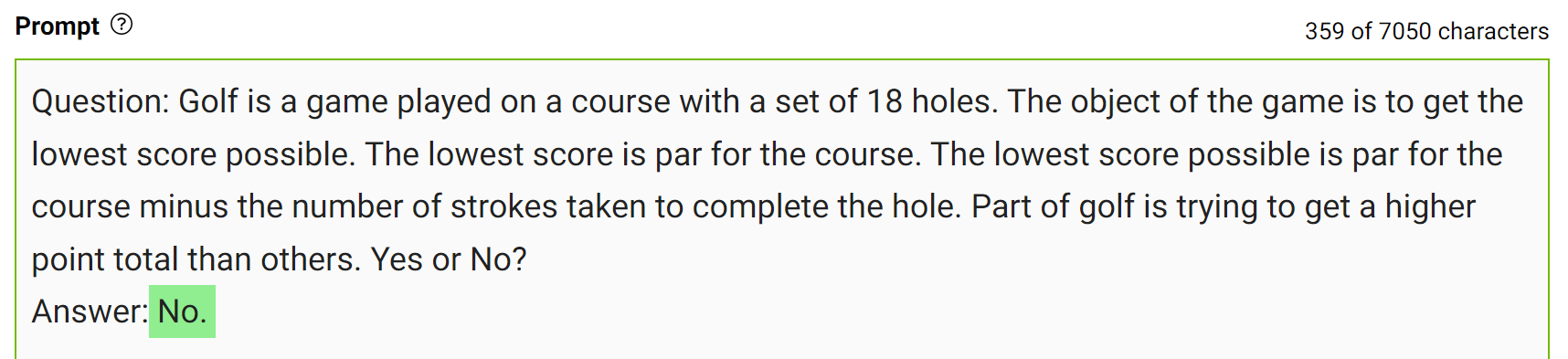
O modelo respondeu “Não” com segurança à mesma pergunta. Esta é uma demonstração simples desse tipo de inspiração. No entanto, há mais alguns detalhes a serem considerados antes de chegar à resposta final. Para obter mais informações, consulte Generated Knowledge Prompting for Commonsense Reasoning.
Na prática, você gera múltiplas respostas e seleciona a resposta que ocorre com mais frequência como a final.
Experimente!
A melhor maneira de escrever prompts adequados ao seu caso de uso é experimentar e brincar. É uma experiência de aprendizado projetar um prompt que pode fornecer os resultados corretos, seja como você o escreve ou como você define os parâmetros do modelo.
O playground do serviço NeMo pode ajudá-lo a testar seus prompts e criar seu caso de uso. Se você estiver interessado em acessar o playground, consulte Serviço NVIDIA NeMo.
Conclusão
Neste post, compartilhei maneiras de gerar melhores resultados a partir de LLMs. Discuti como os parâmetros do modelo podem ser ajustados para obter os resultados desejados e algumas estratégias para projetar seus prompts.