
A IA está evoluindo, e os modelos de raciocínio estão aumentando a demanda por tokens, impondo novos requisitos a todas as camadas da infraestrutura de IA. Mais do que nunca, o poder de processamento precisa escalar com eficiência para maximizar a geração de tokens e aumentar a produtividade para criadores de modelos e usuários.
As GPUs modernas operam sempre em capacidade máxima, elevando a taxa de transferência a cada geração. No entanto, o desempenho do sistema é cada vez mais influenciado por tarefas em série limitadas pela CPU em loops baseado em agentes — um exemplo clássico de um princípio fundamental da ciência da computação, chamado lei de Amdahl.
Essa dinâmica é especialmente visível em duas classes de cargas de trabalho: aprendizagem por reforço (RL) para treinar modelos com novas habilidades especializadas, como programação ou engenharia, e ações baseadas em agentes, que permitem que os agentes de IA usem ferramentas como navegadores web, bancos de dados, interpretadores de código e outros softwares para concluir tarefas em ambientes reais ou sandboxes.
Ambas as cargas de trabalho combinam duas características de CPU historicamente separadas. Ambientes individuais exigem alto desempenho por thread único para executar código complexo rapidamente, de forma semelhante a uma workstation. Ao mesmo tempo, os sistemas de IA modernos lançam milhares desses ambientes simultaneamente, gerando altas demandas de taxa de processamento típicas da infraestrutura de servidores.
A CPU NVIDIA Vera foi projetada para cargas de trabalho modernas de IA, com os principais recursos de design, incluindo:
- Desempenho extremo de núcleo único: a execução rápida de tarefas individuais é essencial, e o desempenho deve ser sustentado sob carga constante com muitos usuários simultâneos e tarefas baseadas em agentes.
- Alta largura de banda de memória e de malha por núcleo: para garantir SLAs consistentes sob carga, movimentando grandes volumes de dados com eficiência para tarefas de análise em tempo real e mudança de contexto.
- Codesign eficiente em escala de rack: as fábricas de IA precisam implantar e gerenciar rapidamente a capacidade para atender à demanda baseada em agentes, ao mesmo tempo em que maximizam a eficiência energética.
Data centers construídos com a Vera maximizam os investimentos em infraestrutura de IA, seja com CPUs Vera conectadas diretamente a aceleradores ou executando tarefas de forma independente, ao final da rede.
A realidade do pós-treinamento
A aprendizagem por reforço requer que os modelos avaliem constantemente seus resultados, reconhecendo quais foram bem-sucedidos e quais falharam. Por exemplo, os modelos que aprendem a desenvolver software geram grandes volumes de código usando modelos executados em aceleradores, que então são enviados para clusters de CPUs para compilar, executar e testar — atuando em um loop de feedback e recompensa (veja a Figura 1).
Essas tarefas abrangem pesquisa em bases de código, compilação, execução em tempo de execução, scripts, conversão de dados e outras operações comuns. No geral, esse fluxo requer muitos ambientes de sandbox executando simultaneamente, cada um com um conjunto completo de ferramentas. Geralmente, um único núcleo de CPU executa cada caso com baixo nível de paralelismo do início ao fim, a partir de solicitações geradas por aceleradores.

Para maximizar a utilização do acelerador e impor a iteração rápida de modelos, as fases de geração de tokens e treinamento do ciclo operam em um cronograma apertado (ou política). É comum alguns trabalhos de avaliação executados em uma CPU concluírem os trabalhos tarde demais para influenciar o próximo passo do ciclo. Quando isso acontece, o modelo demora mais para aprender com a mesma qualidade, e os tokens valiosos são desperdiçados.
Os loops baseados em agentes exigem uma combinação única de alto desempenho por núcleo, grande largura de banda de dados e execução determinista com latências de cauda mínimas das CPUs que utilizam.
Esses requisitos são um foco central do projeto da CPU NVIDIA Vera (Figura 2), que oferece desempenho em sandbox até 50% maior em comparação com as plataformas concorrentes, largura de banda de memória de 1,2 TB/s e 88 núcleos Olympus com NVIDIA Spatial Multithreading (SMT) para a simultaneidade de tarefas, necessária para fábricas de IA.

Núcleo NVIDIA Olympus
A necessidade de núcleos de maior desempenho para suportar IA levou ao desenvolvimento do núcleo NVIDIA Olympus, o primeiro núcleo de CPU totalmente personalizado para data centers da NVIDIA. O Olympus estreia na Vera juntamente com a segunda geração do NVIDIA Scalable Coherency Fabric (SCF), desenvolvido originalmente para a CPU NVIDIA Grace.
Desenvolvido para operação sustentada de alta instrução por ciclo (IPC) em cargas de trabalho de uso intensivo de memória com lógica de fluxo de controle, o Olympus usa um front-end com busca e decode de instruções de largura 10 e um preditor de desvio neural capaz de avaliar dois desvios tomados por ciclo. Ele é totalmente compatível com o conjunto de instruções Arm v9.2 e o software existente para alto desempenho em contêineres, binários, bibliotecas e sistemas operacionais baseados em Arm.
Os usuários podem escolher entre desempenho por thread e número de threads no tempo de execução com o NVIDIA SMT. Isso proporciona a cada thread desempenho estável, isolamento mais robusto e latência previsível nos piores casos sob cargas pesadas. O SMT tradicional depende de recursos compartilhados ao longo do tempo e de alternância frequente de contexto entre threads, o que introduz variações de desempenho.
NVIDIA SCF e subsistema de memória
A CPU Vera foi projetada em um único die e malha de computação monolíticos, com dielets adjacentes implementando os subsistemas de memória e E/S e preservando a uniformidade da topologia de computação.
Do ponto de vista da aplicação, todos os núcleos estão, na prática, à mesma distância de recursos como outros núcleos, caches, memória e rede, e são provisionados com largura de banda uniforme e de alta taxa de processamento. A maioria das operações sensíveis à latência permanece local, evitando tráfego entre dies desnecessário normalmente observado em CPUs tradicionais.
O caminho de execução de tarefas baseadas em agentes, operações de análise, caches KV e de blobs, orquestração e planos de controle é inerentemente imprevisível em uma fábrica de IA. Em implementações tradicionais, a topologia do processador e os padrões de uso de tarefas vizinhas executadas nele devem ser considerados com antecedência para maximizar o desempenho da aplicação. O design proporciona desempenho ideal sem esse tipo de ajuste.
O SCF de segunda geração conecta todos os 88 núcleos Olympus a um subsistema compartilhado de cache L3 e memória, oferecendo latência consistente e 3,4 TB/s de largura de banda de bisseção, o que permite que a CPU Vera sustente mais de 90% do pico de largura de banda de memória sob carga. Cada núcleo é provisionado com até 14 GB/s de largura de banda de memória, aproximadamente 3 vezes a taxa por núcleo das CPUs tradicionais de data center — garantindo que cargas de trabalho Extract-Transform-Load (ETL), análise em tempo real e cargas de trabalho limitadas à memória mantenham a taxa de processamento quando todos os núcleos estão ativos.
Alimentando o SCF, o subsistema de memória LPDDR5X de segunda geração da Vera oferece até 1,2 TB/s de largura de banda total, com menos da metade do consumo de energia de memória das configurações tradicionais de DDR, e até 1,5 TB de capacidade — um aumento de 3 vezes em relação à geração anterior. Os módulos de memória anexados por compressão de contorno (SOCAMM) trazem a memória de baixo consumo para o data center pela primeira vez, substituindo a memória soldada por módulos removíveis e atualizáveis que combinam a eficiência do LPDDR com a capacidade de manutenção de nível de servidor.
Desempenho em toda a fábrica de IA
Todos esses elementos de arquitetura permitem que a CPU Vera ofereça até 1,5 vezes o desempenho de sandbox baseado em agentes sob carga total do soquete, em comparação com plataformas x86 concorrentes, abrangendo compiladores, ferramentas de script, mecanismos de execução, conversão de texto, compressão e chamadas de ferramentas baseadas em agentes (Figura 3).

Essa vantagem é composta por três dimensões. No pós-treinamento com RL, um sandbox 1,5 vezes mais rápido retorna resultados de avaliação em janelas de tempo mais curtas, permitindo que os modelos capturem os melhores tokens de gradiente e acelerando os ciclos de treinamento.
Na inferência baseada em agentes, reduz o tempo de espera dos usuários, melhorando a utilização de aceleradores e aliviando a pressão sobre o descarregamento do cache KV.
Para problemas de treinamento de fronteira, um desempenho por núcleo 50% maior permite que mais testes sequenciais sejam concluídos antes de atingir os limites de tempo, expandindo a variedade de problemas difíceis com os quais um modelo pode aprender.
Ambientes baseados em agentes por rack
Todas as fábricas de IA exigem milhões de núcleos de CPU para viabilizar o loop baseado em agentes de RL e uso de ferramentas. Para desbloquear o potencial da infraestrutura de IA, a implantação deve ser rápida. Para muitos operadores de fábricas de IA, a CPU Vera será a primeira de sua frota, chegando em data centers projetados para alta potência de rack e resfriamento líquido.
O novo Rack de CPU NVIDIA Vera oferece densidade e desempenho incríveis com as mesmas restrições de planejamento, infraestrutura de rack, resfriamento e consumo de energia dos produtos NVL72 que estão sendo implantados atualmente.
Com uma capacidade de mais de 22 mil sandboxes, o Vera CPU Rack oferece mais de 4 vezes a capacidade e o dobro do desempenho por watt dos racks de servidores baseados em x86 (Figura 4). As fábricas de IA implantam e gerenciam a capacidade no nível do rack, reduzindo radicalmente o tempo de expansão e melhorando o tempo de lançamento no mercado para nova capacidade, ao mesmo tempo em que simplificam o planejamento da infraestrutura.
Cada CPU Vera é conectada a SmartNICs NVIDIA BlueField-4 que contêm núcleos de gerenciamento dedicados baseados na plataforma Grace, descarregando tarefas de rede como segurança e gerenciamento e garantindo que a capacidade de melhor desempenho do sistema esteja totalmente disponível para tarefas baseadas em agentes.

Plataformas e configurações da Vera
Além do Rack de CPU Vera, a NVIDIA projetou uma família completa de plataformas baseadas em Vera para as diversas cargas de trabalho de fábricas de IA modernas. Ao oferecer muitas opções de densidades, capacidades de resfriamento, configurações e fatores forma, os parceiros de projetos e sistemas Vera estão viabilizando implantação rápida e ampliação da capacidade, adaptáveis às restrições de espaço disponível em qualquer instalação de data center.
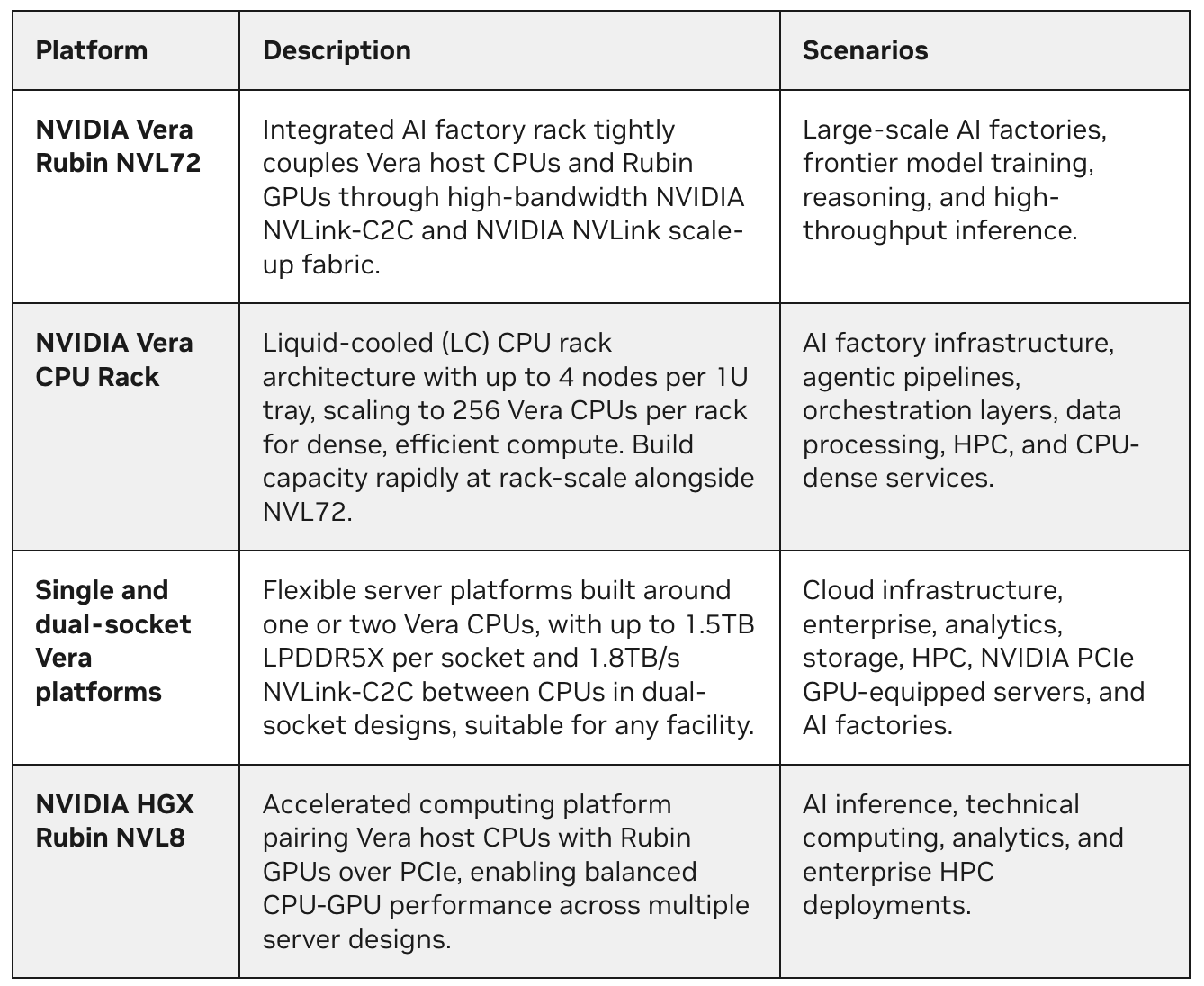

Disponibilidade da plataforma
Os sistemas Vera estarão disponíveis nos principais OEMs, incluindo Dell, HPE, Lenovo e Supermicro, no segundo semestre de 2026. Veja a página web da CPU Vera para obter mais detalhes
Saiba Mais sobre a CPU Vera e a Vera Rubin.
Desempenho da NVIDIA Vera em comparação com AMD EPYC Turin e Intel Xeon 6, em uma variedade de cargas de trabalho, incluindo compilação de código, interpretadores, scripts, mecanismos de execução, ETL, análise de dados e grafos.