
A IA generativa evoluiu rapidamente de modelos baseados em texto para recursos multimodais. Esses modelos executam tarefas como legendagem de imagens e resposta visual a perguntas, refletindo uma mudança em direção a uma IA mais humana. A comunidade agora está se expandindo de texto e imagens para vídeo, abrindo novas possibilidades em todos os setores.
Os modelos de IA de vídeo estão prontos para revolucionar setores como robótica, automotivo e varejo. Na robótica, eles aprimoram a navegação autônoma em ambientes complexos e em constante mudança, o que é vital para setores como manufatura e gerenciamento de armazéns. Na indústria automotiva, a IA de vídeo está impulsionando a direção autônoma, aumentando a percepção do veículo, a segurança e a manutenção preditiva para melhorar a eficiência.
Para criar modelos de base de imagem e vídeo, os desenvolvedores devem selecionar e pré-processar uma grande quantidade de dados de treinamento, tokenizar os dados de alta qualidade resultantes em alta fidelidade, treinar ou personalizar modelos pré-treinados com eficiência e em escala e, em seguida, gerar imagens e vídeos de alta qualidade durante a inferência.
Anunciando o NVIDIA NeMo para IA Generativa Multimodal
O NVIDIA NeMo é uma plataforma de ponta a ponta para desenvolver, personalizar e implantar modelos de IA generativa.
A NVIDIA acaba de anunciar a expansão do NeMo para oferecer suporte ao pipeline de ponta a ponta para o desenvolvimento de modelos multimodais. O NeMo permite que você selecione facilmente dados visuais de alta qualidade, acelere o treinamento e a personalização com tokenizadores e técnicas de paralelismo altamente eficientes e reconstrua visuais de alta qualidade durante a inferência.
Curadoria Acelerada de Dados de Vídeo e Imagem
Dados de treinamento de alta qualidade garantem resultados de alta precisão de um modelo de IA. No entanto, os desenvolvedores enfrentam vários desafios na criação de pipelines de processamento de dados, desde o dimensionamento até a orquestração de dados.
O NeMo Curator simplifica o processo de curadoria de dados, tornando mais fácil e rápido para você criar modelos de IA generativa multimodal. Sua experiência pronta para uso minimiza o custo total de propriedade (TCO) e acelera o tempo de lançamento no mercado.
Ao trabalhar com recursos visuais, as empresas podem facilmente alcançar o processamento de dados em escala de petabytes. O NeMo Curator fornece um pipeline de orquestração que pode balancear a carga em várias GPUs em cada estágio da curadoria de dados. Como resultado, você pode reduzir o tempo de processamento de vídeo em 7 vezes em comparação com uma implementação ingênua baseada em GPU. Os pipelines escaláveis podem processar com eficiência mais de 100PB de dados, garantindo o manuseio contínuo de grandes conjuntos de dados.
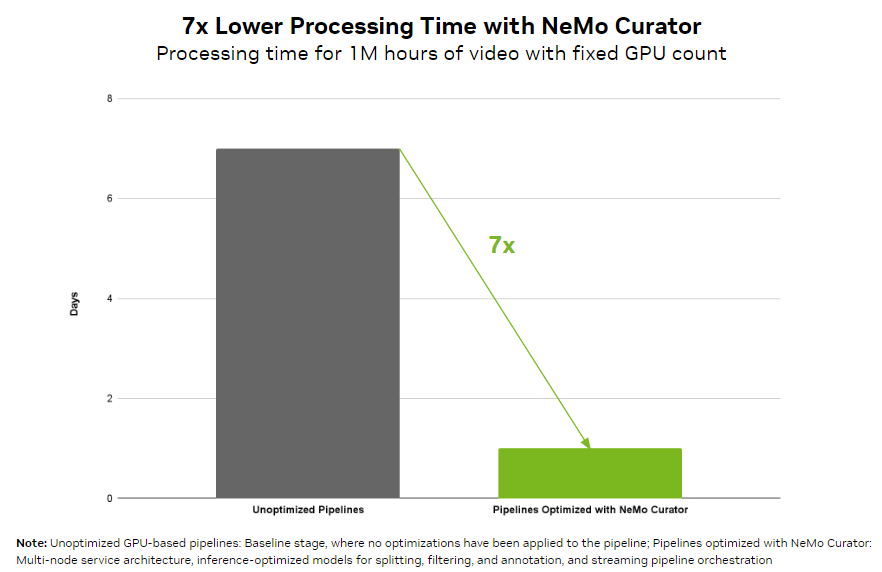
O NeMo Curator fornece modelos de curadoria de vídeo de referência otimizados para estágios de filtragem, legendagem e incorporação de alto rendimento para aprimorar a qualidade do conjunto de dados, permitindo que você crie modelos de IA mais precisos.
Por exemplo, o NeMo Curator usa um modelo de legenda otimizado que oferece uma melhoria de taxa de transferência de ordem de magnitude em comparação com implementações de modelo de inferência não otimizadas.
Tokenizadores NVIDIA Cosmos
Os tokenizadores mapeiam dados visuais redundantes e implícitos em tokens compactos e semânticos, permitindo o treinamento eficiente de modelos generativos em larga escala e democratizando sua inferência em recursos computacionais limitados.
Os tokenizadores de vídeo e imagem abertos de hoje geralmente geram representações de dados ruins, levando a reconstruções com perdas, imagens distorcidas e vídeos temporariamente instáveis e limitando a capacidade de modelos generativos construídos sobre os tokenizadores. Processos de tokenização ineficientes também resultam em codificação e decodificação lentas e tempos de treinamento e inferência mais longos, afetando negativamente a produtividade do desenvolvedor e a experiência do usuário.
Os tokenizadores NVIDIA Cosmos são modelos abertos que oferecem tokenização visual superior com taxas de compactação excepcionalmente grandes e qualidade de reconstrução de ponta em diversas categorias de imagem e vídeo.
Vídeo 1. Tokenizadores de IA generativa eficientes para imagem e vídeo
Esses tokenizadores fornecem facilidade de uso por meio de um conjunto de modelos padronizados de tokenizador que suportam modelos de linguagem de visão (VLMs) com códigos latentes discretos, modelos de difusão com incorporações latentes contínuas e várias proporções e resoluções, permitindo o gerenciamento eficiente de imagens e vídeos de grande resolução. Isso fornece ferramentas para tokenizar uma ampla variedade de dados de entrada visual para criar modelos de IA de imagem e vídeo.
Arquitetura do Tokenizador do Cosmos
Um tokenizador Cosmos usa uma estrutura sofisticada de codificador-decodificador projetada para alta eficiência e aprendizado eficaz. Em sua essência, ele emprega blocos de convolução causal 3D, que são camadas especializadas que processam conjuntamente informações espaço-temporais e usa atenção temporal causal que captura dependências de longo alcance nos dados.
A estrutura causal garante que o modelo use apenas quadros passados e presentes ao executar a tokenização, evitando quadros futuros. Isso é crucial para se alinhar com a natureza causal de muitos sistemas do mundo real, como aqueles em IA física ou LLMs multimodais.
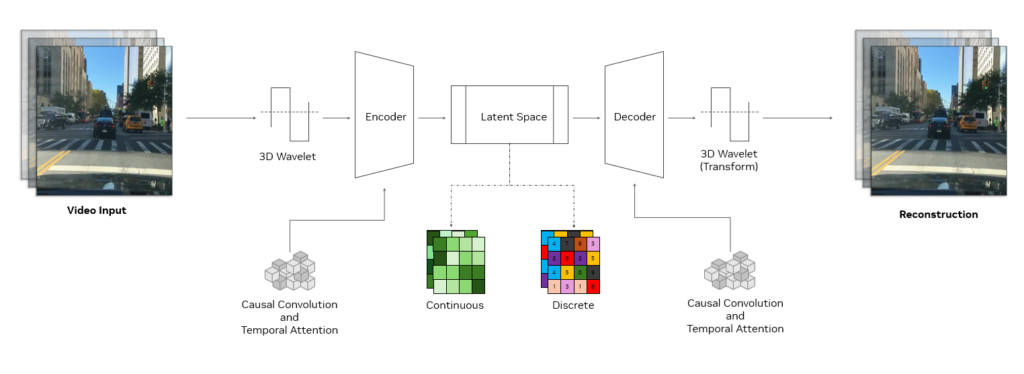
A entrada é reduzida usando wavelets 3D, uma técnica de processamento de sinal que representa informações de pixel com mais eficiência. Depois que os dados são processados, uma transformada wavelet inversa reconstrói a entrada original.
Essa abordagem melhora a eficiência do aprendizado, permitindo que os módulos aprendíveis do codificador-decodificador do tokenizador se concentrem em recursos significativos em vez de detalhes de pixel redundantes. A combinação de tais técnicas e sua receita de treinamento exclusiva torna os tokenizadores Cosmos uma arquitetura de ponta para tokenização eficiente e poderosa.
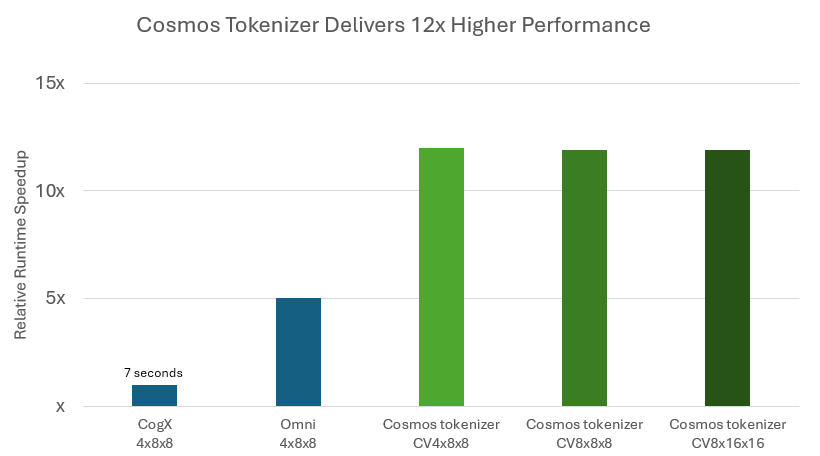
Durante a inferência, os tokenizadores Cosmos reduzem significativamente o custo de execução do modelo, fornecendo reconstrução até 12 vezes mais rápida em comparação com os principais tokenizadores de peso aberto (Figura 3).
Os tokenizadores Cosmos também produzem imagens e vídeos de alta fidelidade enquanto compactam mais do que outros tokenizadores, demonstrando uma compensação de compactação de qualidade sem precedentes.
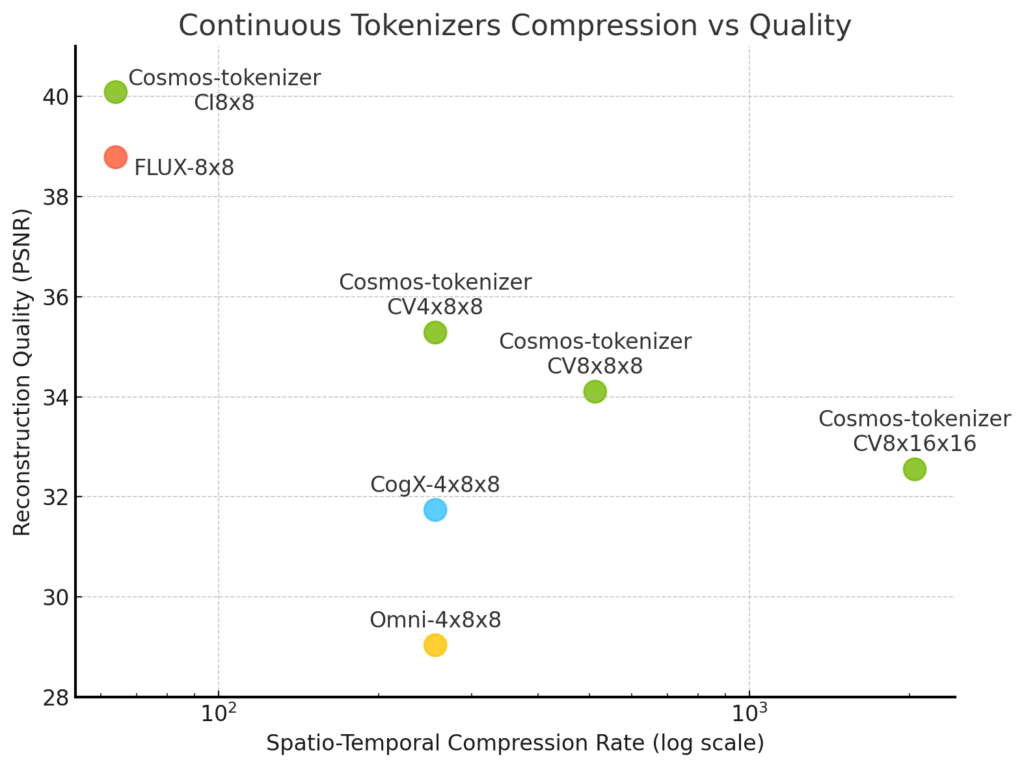
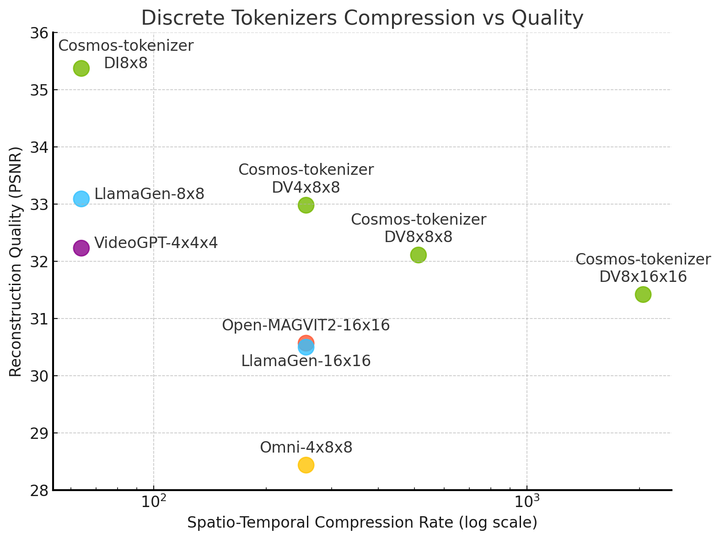
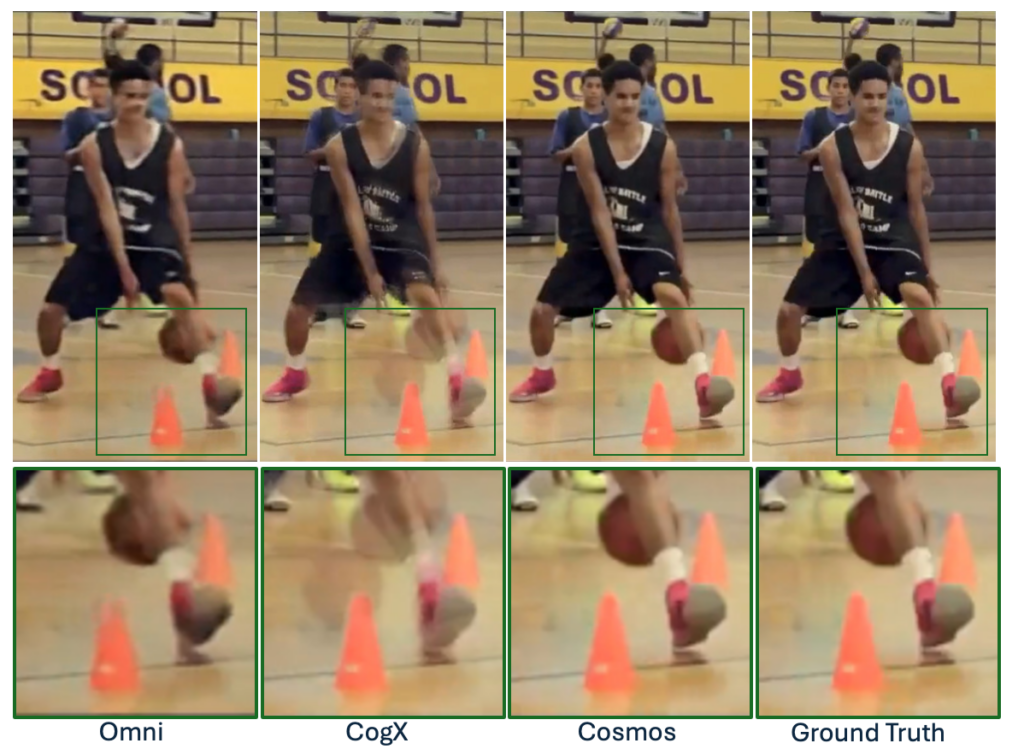
Embora o tokenizador Cosmos se regenere a partir de tokens altamente compactados, ele é capaz de criar imagens e vídeos de alta qualidade devido a uma técnica e arquitetura inovadoras de treinamento de rede neural.
Construa Seus Próprios Modelos Multimodais com o NeMo
A expansão da plataforma NVIDIA NeMo com processamento de dados em escala usando NeMo Curator e tokenização de alta qualidade e reconstrução visual usando o tokenizador Cosmos permite que você crie modelos multimodais de IA generativa de última geração.
Junte-se à lista de espera e seja notificado quando o NeMo Curator estiver disponível. O tokenizer já está disponível no repositório GitHub /NVIDIA/cosmos-tokenizer e no Hugging Face.