
Nos últimos anos, os papéis da IA e do machine learning (ML) nas principais empresas mudaram. Antes atividades de pesquisa ou desenvolvimento avançado, elas agora fornecem uma base importante para os sistemas de produção.
À medida que mais empresas buscam transformar seus negócios com IA e ML, mais e mais pessoas estão falando sobre MLOps. Se você ouviu essas conversas, pode ter descoberto que quase todos os envolvidos concordam que você precisa de uma estratégia de MLOps para colocar o ML em produção.
Esta postagem fornece uma breve visão geral dos MLOps empresariais. Para saber mais, assista-me no NVIDIA GTC 2023 em Enterprise MLOps 101, uma introdução ao cenário MLOps para empresas. Apresentei a sessão com meu colega, Michael Balint.
Por que MLOps é Confuso?
A conversa MLOps é confusa por vários motivos principais, detalhados abaixo.
MLOps É Amplo
MLOps é um termo amplo que descreve as tecnologias, processos e cultura que permitem que as empresas projetem, desenvolvam e sustentem sistemas de ML de produção. Quase todas as ferramentas ou sistemas relevantes para o desenvolvimento de software convencional, gerenciamento de dados ou inteligência de negócios podem ser relevantes para um sistema de ML de produção.
Como MLOps é um tópico popular, muitas dessas ferramentas e sistemas que podem ser relevantes para sistemas de ML de produção foram renomeados para enfatizar sua conexão com MLOps.
MLOps É Diversificado
Os sistemas de machine learning são sistemas de software complexos. Diferentes organizações e profissionais adotarão diversas abordagens para gerenciar essa complexidade, assim como fazem para gerenciar a complexidade de construir e manter sistemas de software convencionais.
No entanto, como as empresas não criam sistemas de ML de produção há tanto tempo quanto as empresas criam software convencional, as abordagens padronizadas não foram estabelecidas. Também falta padronização para a linguagem usada para descrever esses sistemas e os critérios com os quais avaliá-los.
Pode ser confuso quando diferentes pessoas falam sobre MLOps porque podem estar descrevendo diferentes partes do espaço do problema. Por exemplo, as partes mais importantes para o caso de uso, o setor ou os processos e ferramentas da empresa.
MLOps É Complexo
MLOps é legitimamente complexo. No entanto, como os praticantes e empresas experientes de MLOps estão focados nos detalhes de sua abordagem e ferramentas específicas, eles tendem a enfatizar sua complexidade. Parte do problema é que, em um domínio em evolução como o machine learning de produção, pode ser difícil descobrir como separar a complexidade acidental da complexidade essencial para apresentar uma visão simples de um problema complexo.
Superando a Confusão
Uma maneira melhor de começar a abordar MLOps é pensar sobre o que sua empresa está fazendo hoje com machine learning, o que você gostaria de fazer no futuro e quais desafios enfrentará com os sistemas de machine learning como resultado.
Quais Problemas Precisam Ser Resolvidos?
Diferentes problemas de ML impõem diferentes tipos de requisitos em sistemas de ML. Problemas envolvendo dados não estruturados, como entender vídeo, áudio ou linguagem natural, envolvem muito mais esforço, incluindo esforço humano manual, para rotular exemplos de treinamento do que problemas envolvendo dados de negócios tabulares, nos quais o esforço de rotulagem pode ser trivial ou automatizado.
Alguns problemas se beneficiam de um modelo que precisa apenas de dados imediatamente disponíveis de uma única fonte, enquanto outras abordagens e problemas dependem da federação de dados históricos e agregados de várias fontes com uma nova observação para fazer uma previsão. Novas aplicações de ML podem se beneficiar de um melhor suporte para desenvolvimento experimental e exploratório, enquanto sistemas maduros podem se beneficiar mais da automação do processo de desenvolvimento.
Finalmente, os sistemas que automatizam decisões críticas que podem afetar vidas humanas, controlar máquinas perigosas ou gerenciar carteiras financeiras precisam ser simulados em uma variedade de condições, incluindo cenários improváveis ou adversos, a fim de validar sua adequação e segurança. Se você estiver trabalhando com problemas que impliquem requisitos especiais, certifique-se de encontrar uma solução MLOps que possa ajudá-lo a atender a esses requisitos.
Quais os Fatores que Precisam Ser Considerados?
Da mesma forma, algumas áreas de aplicação e requisitos de negócios impõem requisitos técnicos em sistemas de machine learning. As aplicações em setores regulamentados geralmente se beneficiam da capacidade de reproduzir e explicar resultados históricos, como explicar uma discussão de subscrição financeira ou mostrar que os dados pessoais de um usuário não foram usados no treinamento de um modelo.
Aplicações sensíveis à latência, como pesquisa, recomendações de mídia e segmentação de anúncios, podem se beneficiar da infraestrutura de serviço que oferece suporte à previsão de baixa latência e ao fornecimento de um resultado de um conjunto de modelos mais e menos complexos juntos para melhorar o tempo de resposta do pior caso. Muitos problemas de percepção se beneficiarão da infraestrutura para aprendizado de transferência e frameworks de atendimento que podem manipular e otimizar modelos grandes e complexos.
Como são as equipes de ML e dados hoje?
Assim como o cenário geral de ML continua a evoluir, as funções e personas das equipes de dados continuam a evoluir. No início dos anos 2010, um “cientista de dados” era uma função full-stack que tinha responsabilidades substanciais de engenharia de dados e desenvolvimento de software, bem como alguma sofisticação estatística. Hoje, os cientistas de dados são muito mais especializados. As equipes agora geralmente incluem as seguintes funções:
Os cientistas de dados se concentram em projetar e executar experimentos para identificar e explorar padrões em dados, usando ferramentas como resumos básicos e agregação, estatística aplicada e machine learning.
Os engenheiros de dados disponibilizam os dados, estruturados ou não, em repouso ou em movimento, em escala e abordam questões de catalogação, governança e controle de acesso.
Os analistas de negócios usam o processamento de consultas em conjuntos de dados estruturados e federados para entender as características de um problema de negócios.
Os desenvolvedores de aplicações constroem sistemas de produção desenvolvendo serviços maduros e robustos com base em experimentos de cientistas de dados, integrando-se com serviços de dados mantidos por engenheiros de dados e desenvolvendo componentes de aplicações convencionais e integrações com middleware corporativo.
Os engenheiros de machine learning têm responsabilidades que abrangem várias funções, mas com foco específico no desenvolvimento, manutenção e otimização da infraestrutura de produção.
Pensar em quem está atualmente envolvido em suas equipes de dados, e quem você gostaria de envolver no futuro, é um aspecto importante da avaliação de ferramentas, sistemas e soluções de MLOps. Essa avaliação informa o que é importante para sua equipe e quem é o público para uma determinada solução.
Avalie o Cenário e Crie uma Solução para sua Equipe
Depois de considerar os problemas que está tentando resolver e a composição de sua equipe de dados, você está preparado para avaliar e entender o cenário MLOps em termos da solução que você e sua organização precisam. Seu objetivo é apoiar suas próprias iniciativas de machine learning, em vez de tentar entender o cenário MLOps com base no que fornecedores e influenciadores estão dizendo sobre MLOps.
Uma Abordagem Centrada no Fluxo de Trabalho
Como o ecossistema MLOps está evoluindo rapidamente, muitas categorias de produtos não são mutuamente exclusivas e possuem limites difusos. Isso significa que você não quer necessariamente pensar em uma solução MLOps como uma lista de verificação de recursos ou uma combinação de produtos complementares que se encaixam como blocos de construção. Essa abordagem o comprometerá com um ponto de vista específico de uma paisagem em mudança.
Em vez disso, pense em como as pessoas trabalham juntas para construir sistemas de machine learning e como diferentes tipos de ferramentas e sistemas podem apoiá-los.
A Figura 1 mostra um fluxo de trabalho de descoberta de machine learning característico. Esse fluxo de trabalho apresenta sete processos humanos, cada um dos quais informa o próximo. As personas envolvidas em cada estágio são anotadas: as personas de cientista de dados e analista de negócios geralmente não se preocupam com os detalhes da infraestrutura de computação, enquanto engenheiros e desenvolvedores de aplicações interagem diretamente com a infraestrutura como parte de seu trabalho.
Imagem de fluxo de trabalho que identifica sete estágios de descoberta e desenvolvimento de MLOps: definição de problema/métrica, federação de dados, engenharia de recursos, seleção de modelo, validação e simulação, implantação de produção e monitoramento contínuo.
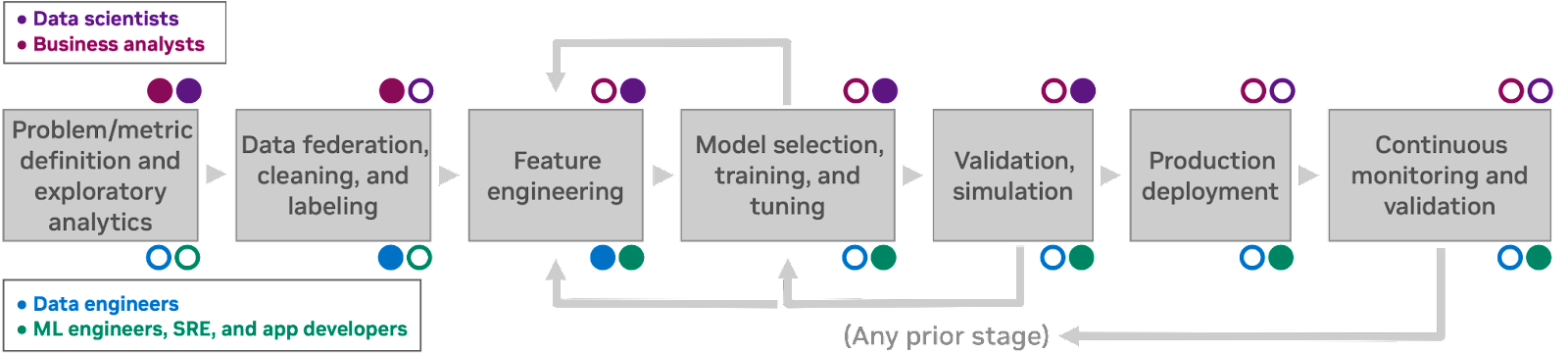
Como os humanos sempre têm informações incompletas (e frequentemente cometem erros), é possível retornar a uma fase anterior do fluxo de trabalho a qualquer momento e revisitar decisões anteriores à luz de novos insights. A forma como sua empresa fala sobre fluxos de trabalho de ML pode envolver termos ligeiramente diferentes ou um número diferente de estágios, mas deve ser possível acompanhar em qualquer caso.
Apoiando Sua Equipe em Todo o Fluxo de Trabalho de ML
Como as ferramentas MLOps podem oferecer suporte ao fluxo de trabalho de ML? A Figura 2 descreve várias categorias de produtos sobrepostas e como elas oferecem suporte a aspectos do fluxo de trabalho de ML. Personas e categorias de ofertas que são indiferentes ou isoladas da infraestrutura de computação subjacente são representadas acima do fluxo de trabalho, enquanto personas e produtos que dependem da interação direta com a infraestrutura de computação subjacente são descritos abaixo do fluxo de trabalho.
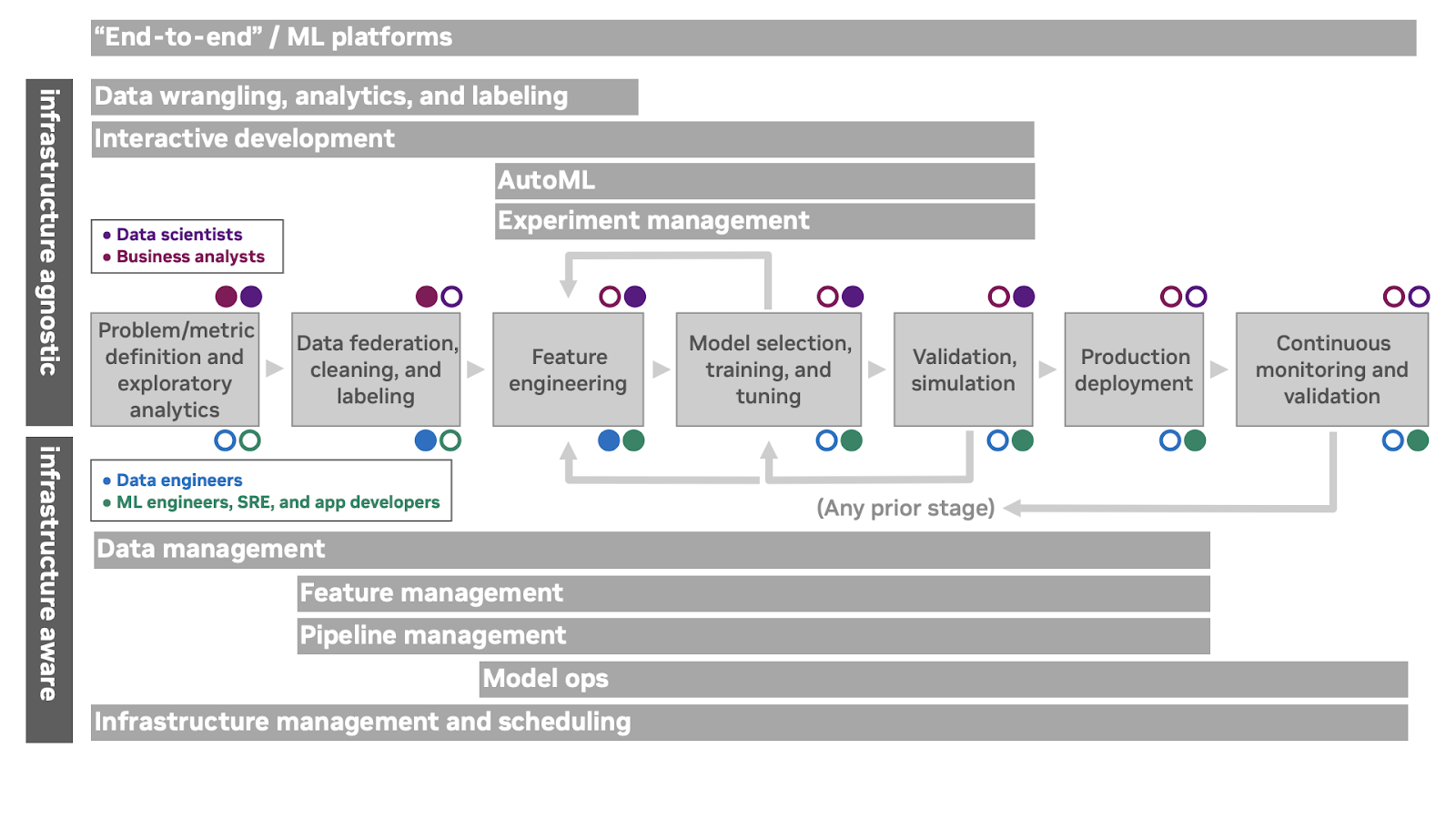
A categoria superior na Figura 2, de ponta a ponta, inclui ofertas de plataforma ML que incorporam um plano de controle e suporte para várias fases do ciclo de vida. É importante observar que o termo “ponta a ponta” não é um julgamento de valor ou uma declaração de integridade. A adesão a esta categoria apenas indica que uma determinada oferta abrange uma ampla fatia do ciclo de vida e é projetada para ser operada por si mesma.
A segunda categoria na Figura 2 combina ofertas de organização de dados, que incluem exploração de dados, visualização e recursos de federação de alto nível, inteligência de negócios convencional e ofertas analíticas e ofertas de rotulagem para dados não estruturados. Os tipos de problemas que você está resolvendo indicarão quais desses tipos de ofertas são mais relevantes para seus fluxos de trabalho.
As ofertas de desenvolvimento interativo fornecem um plano de controle para fornecer aos profissionais de ciência de dados e ML acesso a recursos de computação sob demanda. Eles geralmente fornecem uma facilidade para gerenciar ambientes de desenvolvimento e integram-se a sistemas externos de controle de versão, IDEs de desktop e outras ferramentas de desenvolvedor independentes. Eles fornecem uma visão unificada da infraestrutura local e de nuvem pública e facilitam a colaboração das equipes em projetos.
As ofertas de gerenciamento de experimentos fornecem uma maneira de rastrear resultados de várias configurações de modelo (juntamente com código e dados com versão) para entender o desempenho da modelagem ao longo do tempo. Os sistemas AutoML se baseiam no gerenciamento de experimentos para pesquisar automaticamente o espaço de possíveis técnicas e hiperparâmetros para uma determinada técnica para produzir um modelo treinado com entrada mínima do profissional.
As ofertas de gerenciamento de dados suportam armazenamento de dados, versão de dados, ingestão e controle de acesso. Do ponto de vista dos sistemas de ML, o controle de versão de dados geralmente é a peça crítica: o trabalho reproduzível depende da capacidade de identificar os dados nos quais um modelo foi treinado.
As ofertas de gerenciamento de recursos incorporam armazenamentos de recursos para rastrear recursos derivados, agregados ou caros para computação para desenvolvimento e produção. Eles também podem oferecer suporte à colaboração em torno de abordagens de engenharia de recursos em algumas empresas.
As ofertas de gerenciamento de pipeline fornecem uma maneira de orquestrar e monitorar os vários componentes de software envolvidos em fluxos de trabalho exploratórios e de produção, por exemplo, pré-processamento, treinamento e inferência.
As ofertas de ModelOps abordam as questões de publicação de modelos como serviços implantáveis, implantação desses serviços de previsão, gerenciamento e roteamento para conjuntos de serviços de previsão, explicação de previsões após o fato, rastreamento de feedback de previsões e monitoramento de entradas e saídas de modelos para desvio de conceito.
O gerenciamento de infraestrutura fornece uma interface para agendar trabalhos e serviços de computação em hardware subjacente ou recursos de nuvem. As ofertas nesse espaço são normalmente interessantes do ponto de vista dos sistemas de machine learning se fornecerem suporte especial para hardware acelerado, agendamento de grupos e outras preocupações específicas de ML.