
Os modelos abertos estão impulsionando uma nova onda de IA nos dispositivos, expandindo a inovação além da nuvem para os dispositivos do cotidiano. À medida que esses modelos avançam, seu valor depende cada vez mais do acesso a contexto local em tempo real, capaz de transformar insights significativos em ação.
Projetadas para essa mudança, as mais recentes adições da Google à família Gemma 4 apresentam uma classe de modelos compactos, rápidos e omni-capazes, desenvolvidos para execução local eficiente em uma ampla gama de dispositivos.
Google e NVIDIA colaboraram para otimizar o Gemma 4 para GPUs NVIDIA, permitindo desempenho eficiente em uma variedade de sistemas — desde implantações em data centers até PCs e workstations com NVIDIA RTX, o supercomputador pessoal de IA NVIDIA DGX Spark e os módulos de IA de borda NVIDIA Jetson Orin Nano.
Gemma 4: Modelos Compactos Otimizados para GPUs NVIDIA
As mais recentes adições à família de modelos abertos Gemma 4 — abrangendo variantes E2B, E4B, 26B e 31B — são projetadas para implantação eficiente, de dispositivos de borda a GPUs de alto desempenho.
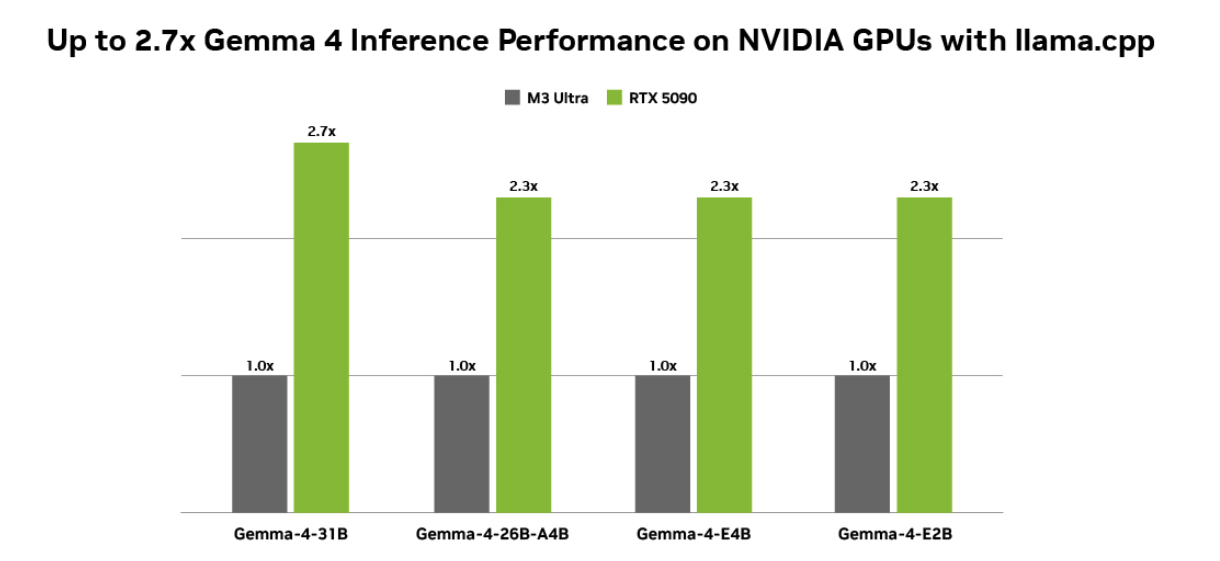
Todas as configurações foram medidas usando quantizações Q4_K_M BS = 1, ISL = 4096 e OSL = 128 nas GPUs NVIDIA GeForce RTX 5090 e Mac M3 Ultra. O throughput de geração de tokens foi medido com llama.cpp b7789, usando a ferramenta llama-bench.
Esta nova geração de modelos compactos oferece suporte a uma série de tarefas, incluindo:
- Raciocínio: Alto desempenho em tarefas complexas de resolução de problemas.
- Programação: Geração de código e depuração para fluxos de trabalho de desenvolvedores.
- Agentes: Suporte nativo para uso estruturado de ferramentas (chamada de funções).
- Capacidades de Visão, Vídeo e Áudio: Permite interações multimodais ricas para reconhecimento de objetos, reconhecimento automático de fala e inteligência de documentos ou vídeos.
- Entrada Multimodal Intercalada: Misture texto e imagens em qualquer ordem em um único prompt.
- Multilíngue: Suporte pronto para uso em mais de 35 idiomas, pré-treinado em mais de 140 idiomas.
Os modelos E2B e E4B são desenvolvidos para inferência ultraeficiente e de baixa latência na borda, funcionando completamente offline com latência quase nula em muitos dispositivos, incluindo módulos Jetson Nano.
Os modelos 26B e 31B são projetados para raciocínio de alto desempenho e fluxos de trabalho voltados a desenvolvedores, tornando-os muito adequados para IA agêntica. Otimizados para oferecer raciocínio acessível e de última geração, esses modelos rodam de forma eficiente em GPUs NVIDIA RTX e no DGX Spark — potencializando ambientes de desenvolvimento, assistentes de programação e fluxos de trabalho orientados por agentes.
À medida que a IA agêntica local continua a ganhar força, aplicações como o OpenClaw estão habilitando assistentes de IA sempre ativos em PCs RTX, workstations e DGX Spark. Os modelos Gemma 4 mais recentes são compatíveis com o OpenClaw, permitindo que os usuários criem agentes locais capazes de extrair contexto de arquivos pessoais, aplicações e fluxos de trabalho para automatizar tarefas. Saiba como executar o OpenClaw gratuitamente em GPUs RTX e DGX Spark ou usando o guia OpenClaw para DGX Spark.
Confira o blog de anúncio do Google DeepMind para saber mais sobre as últimas adições à família Gemma 4.
Como Começar: Gemma 4 em GPUs RTX e DGX Spark
A NVIDIA colaborou com a Ollama e a llama.cpp para oferecer a melhor experiência de implantação local para cada um dos modelos Gemma 4.
Para usar o Gemma 4 localmente, os usuários podem baixar o Ollama para executar os modelos Gemma 4 ou instalar o llama.cpp e combiná-lo com o checkpoint GGUF do Gemma 4 no Hugging Face. Além disso, o Unsloth oferece suporte desde o primeiro dia com modelos otimizados e quantizados para ajuste fino local eficiente e implantação via Unsloth Studio. Comece a executar e ajustar o Gemma 4 no Unsloth Studio hoje mesmo.
Executar modelos abertos como a família Gemma 4 em GPUs NVIDIA alcança desempenho ideal porque os Tensor Cores da NVIDIA aceleram as cargas de trabalho de inferência de IA para oferecer maior throughput e menor latência na execução local. Além disso, o software CUDA garante ampla compatibilidade com os principais frameworks e ferramentas, permitindo que novos modelos rodem eficientemente desde o primeiro dia.
Essa combinação permite que modelos abertos como o Gemma 4 escalem em uma ampla gama de sistemas — desde o Jetson Orin Nano na borda até PCs RTX, workstations e DGX Spark — sem exigir otimizações extensas.
Confira o blog técnico da NVIDIA para mais detalhes sobre como começar com o Gemma 4 em GPUs NVIDIA e saiba mais sobre o trabalho da NVIDIA com modelos abertos.
#ICYMI: As Últimas Novidades para PCs com IA RTX
✨ Acompanhe os blogs do RTX AI Garage com uma série de anúncios de IA agêntica da NVIDIA GTC, como novos modelos abertos para agentes locais. Esses modelos incluem NVIDIA Nemotron 3 Nano 4B e Nemotron 3 Super 120B, além de otimizações para o Qwen 3.5 e o Mistral Small 4.
A NVIDIA apresentou recentemente o NVIDIA NemoClaw, uma stack de código aberto que otimiza as experiências OpenClaw em dispositivos NVIDIA ao aumentar a segurança e oferecer suporte a modelos locais.
🚀 O Accomplish.ai anunciou o Accomplish FREE, uma versão gratuita do seu agente de IA de desktop de código aberto com modelos integrados. Ele usa GPUs NVIDIA para executar modelos de peso aberto localmente, enquanto um roteador híbrido equilibra dinamicamente as cargas de trabalho entre o hardware RTX local e a nuvem — permitindo execução rápida, privada e sem configuração, sem necessidade de chave de API.
Conecte-se com a NVIDIA AI PC no Facebook, Instagram, TikTok e X — e fique informado assinando o newsletter RTX AI PC.