Nota do editor: Esta postagem faz parte da série IA Decodificada, que desmistifica a IA ao tornar a tecnologia mais acessível e que apresenta novos hardware, software, ferramentas e acelerações para usuários de PC RTX.
Os arranha-céus começam com fundações sólidas. O mesmo vale para aplicativos alimentados por IA.
Um modelo básico é uma rede neural de IA treinada em imensas quantidades de dados brutos, geralmente com aprendizado não supervisionado.
É um tipo de modelo de inteligência artificial treinado para compreender e gerar uma linguagem semelhante à humana. Imagine dar a um computador uma enorme biblioteca de livros para ler e aprender, para que ele possa compreender o contexto e o significado por trás de palavras e frases, assim como um ser humano faz.
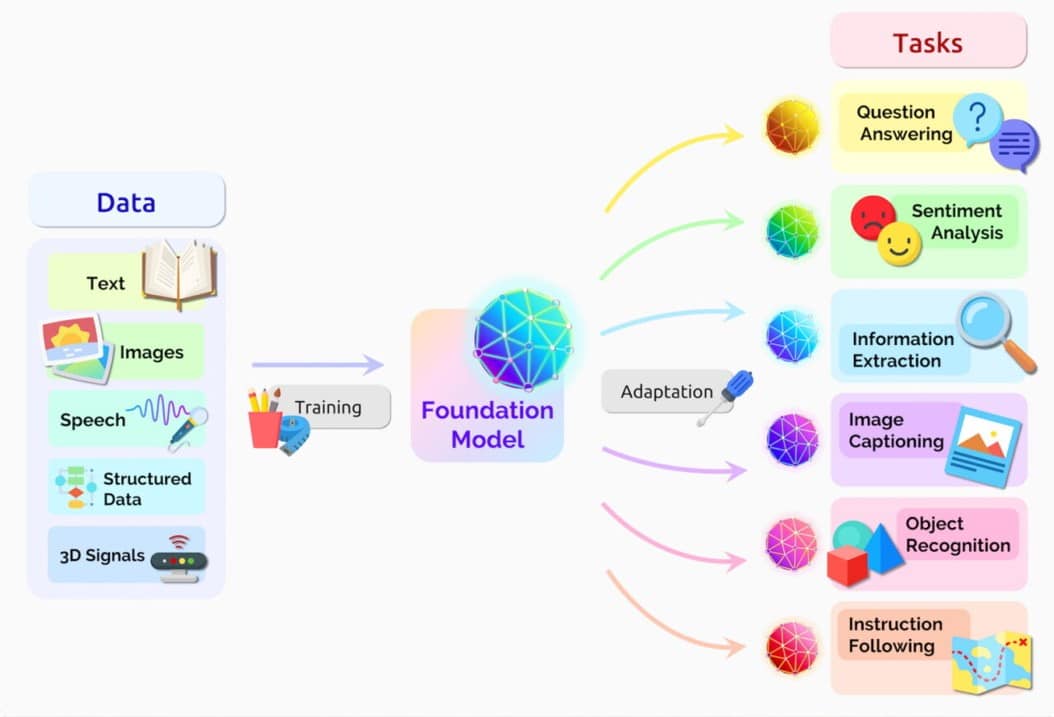
A profunda base de conhecimento de um modelo básico e a capacidade de comunicação em linguagem natural o tornam útil para uma ampla gama de aplicações, incluindo geração e resumo de texto, produção de copilot e análise de código de computador, criação de imagens e vídeos e transcrição de áudio e síntese de fala.
ChatGPT, um dos aplicativos generativos de IA mais notáveis, é um chatbot construído com o modelo básico GPT da OpenAI. Agora em sua quarta versão, o GPT-4 é um grande modelo multimodal que pode ingerir texto ou imagens e gerar respostas de texto ou imagem.
Os aplicativos online criados com base em modelos básicos geralmente acessam os modelos a partir de um data center. Mas muitos desses modelos e os aplicativos que eles alimentam agora podem ser executados localmente em PCs e workstations com GPUs NVIDIA GeForce e NVIDIA RTX.
Usos de Modelos Fundamentais
Os modelos fundamentais podem executar uma variedade de funções, incluindo:
- Processamento de linguagem: compreensão e geração de texto
- Geração de código: análise e depuração de código de computador em muitas linguagens de programação
- Processamento visual: analisando e gerando imagens
- Fala: gerando texto em fala e transcrevendo fala em texto
Eles podem ser usados como estão ou com maior refinamento. Em vez de treinar um modelo de IA inteiramente novo para cada aplicação de IA generativa – um empreendimento caro e demorado – os usuários geralmente ajustam os modelos fundamentais para casos de uso especializados.
Os modelos fundamentais pré-treinados são notavelmente capazes, graças a prompts e técnicas de recuperação de dados, como geração aumentada de recuperação ou RAG. Os modelos fundamentais também se destacam na aprendizagem por transferência, o que significa que podem ser treinados para realizar uma segunda tarefa relacionada ao seu propósito original.
Por exemplo, um modelo de linguagem grande (LLM) de uso geral projetado para conversar com humanos pode ser treinado posteriormente para atuar como um chatbot de atendimento ao cliente capaz de responder a perguntas usando um fundamento de conhecimento corporativo.
Empresas de todos os setores estão ajustando modelos fundamentais para obter o melhor desempenho de seus aplicativos de IA.
Tipos de modelos fundamentais
Mais de 100 modelos fundamentais estão em uso – um número que continua a crescer. LLMs e geradores de imagens são os dois tipos mais populares de modelos básicos. E muitos deles são gratuitos para qualquer pessoa experimentar — em qualquer hardware — no Catálogo de APIs da NVIDIA .
LLMs são modelos que entendem a linguagem natural e podem responder a consultas. Gemma, do Google, é um exemplo; é excelente na compreensão de texto, transformação e geração de código. Quando questionado sobre o astrônomo Cornelius Gemma, ele compartilhou que suas “contribuições para a navegação celestial e a astronomia impactaram significativamente o progresso científico”. Também forneceu informações sobre suas principais realizações, legado e outros fatos.
Ampliando a colaboração dos modelos Gemma, acelerada com NVIDIA TensorRT-LLM em GPUs RTX, o CodeGemma do Google traz recursos de codificação poderosos, porém leves, para a comunidade. Os modelos CodeGemma estão disponíveis como variantes pré-treinadas 7B e 2B especializadas em tarefas de conclusão e geração de código.
O Mistral LLM da MistralAI pode seguir instruções, atender solicitações e gerar textos criativos. Na verdade, ajudou a debater o título deste blog, incluindo a exigência de que usasse uma variação do nome da série “IA Decodificada”, e ajudou a escrever a definição de um modelo fundamental.
O Llama 2 da Meta é um LLM de última geração que gera texto e código em resposta a prompts.
Mistral e Llama 2 estão disponíveis na demonstração técnica NVIDIA ChatRTX, rodando em PCs e workstations RTX. O ChatRTX permite que os usuários personalizem esses modelos fundamentais conectando-os a conteúdo pessoal – como documentos, anotações médicas e outros dados – por meio do RAG. É acelerado pelo TensorRT-LLM para respostas rápidas e contextualmente relevantes. E como funciona localmente, os resultados são rápidos e seguros.
Geradores de imagens como Stable Diffusion XL e SDXL Turbo da StabilityAI permitem que os usuários gerem imagens e visuais impressionantes e realistas. O gerador de vídeo do StabilityAI, Stable Video Diffusion, usam um modelo de difusão generativa para sintetizar sequências de vídeo com uma única imagem como quadro de condicionamento.
Os modelos fundamentais multimodais podem processar simultaneamente mais de um tipo de dados — como texto e imagens — para gerar resultados mais sofisticados.
Um modelo multimodal que funcione tanto com texto quanto com imagens poderia permitir que os usuários carregassem uma imagem e fizessem perguntas sobre ela. Esses tipos de modelos estão rapidamente chegando a aplicações do mundo real, como atendimento ao cliente, onde podem servir como versões mais rápidas e fáceis de usar dos manuais tradicionais.
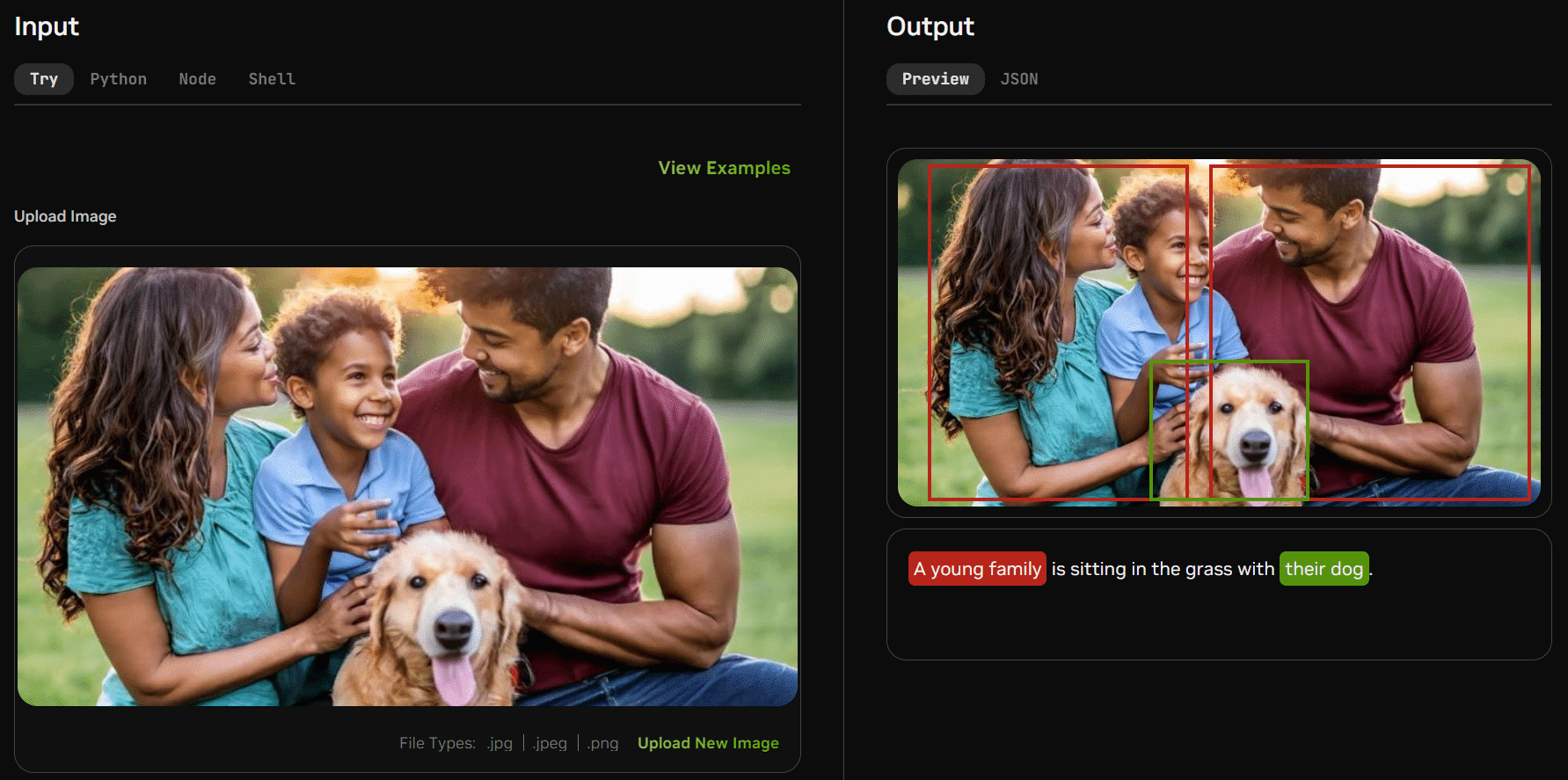
Kosmos 2 é o modelo multimodal inovador da Microsoft projetado para compreender e raciocinar sobre elementos visuais em imagens.
Pense globalmente, execute modelos de IA localmente
As GPUs GeForce RTX e NVIDIA RTX podem executar modelos fundamentais localmente.
Os resultados são rápidos e seguros. Em vez de depender de serviços baseados em nuvem, os usuários podem aproveitar aplicativos como o ChatRTX para processar dados confidenciais em seu PC local sem compartilhar os dados com terceiros ou precisar de uma conexão com a Internet.
Os usuários podem escolher entre um catálogo cada vez maior de modelos de base aberta para baixar e executar em seu próprio hardware. Isso reduz os custos em comparação com o uso de aplicativos e APIs baseados em nuvem e elimina problemas de latência e conectividade de rede. A IA generativa está transformando jogos, videoconferências e experiências interativas de todos os tipos. Entenda o que há de novo e o que vem por aí assinando a newsletter de IA Decodificada.