
Nota do editor: Esta postagem faz parte da série IA Decodificada, que desmistifica a IA ao tornar a tecnologia mais acessível e que apresenta novos hardware, software, ferramentas e acelerações para usuários de PC RTX.
Grandes modelos de linguagem estão impulsionando alguns dos desenvolvimentos mais interessantes em IA com sua capacidade de entender, resumir e gerar conteúdo baseado em texto rapidamente.
Esses recursos potencializam uma variedade de casos de uso, incluindo ferramentas de produtividade, assistentes digitais, personagens não jogáveis em videogames e muito mais. Mas eles não são uma solução única para todos, e os desenvolvedores geralmente precisam ajustar os LLMs para atender às necessidades de seus aplicativos.
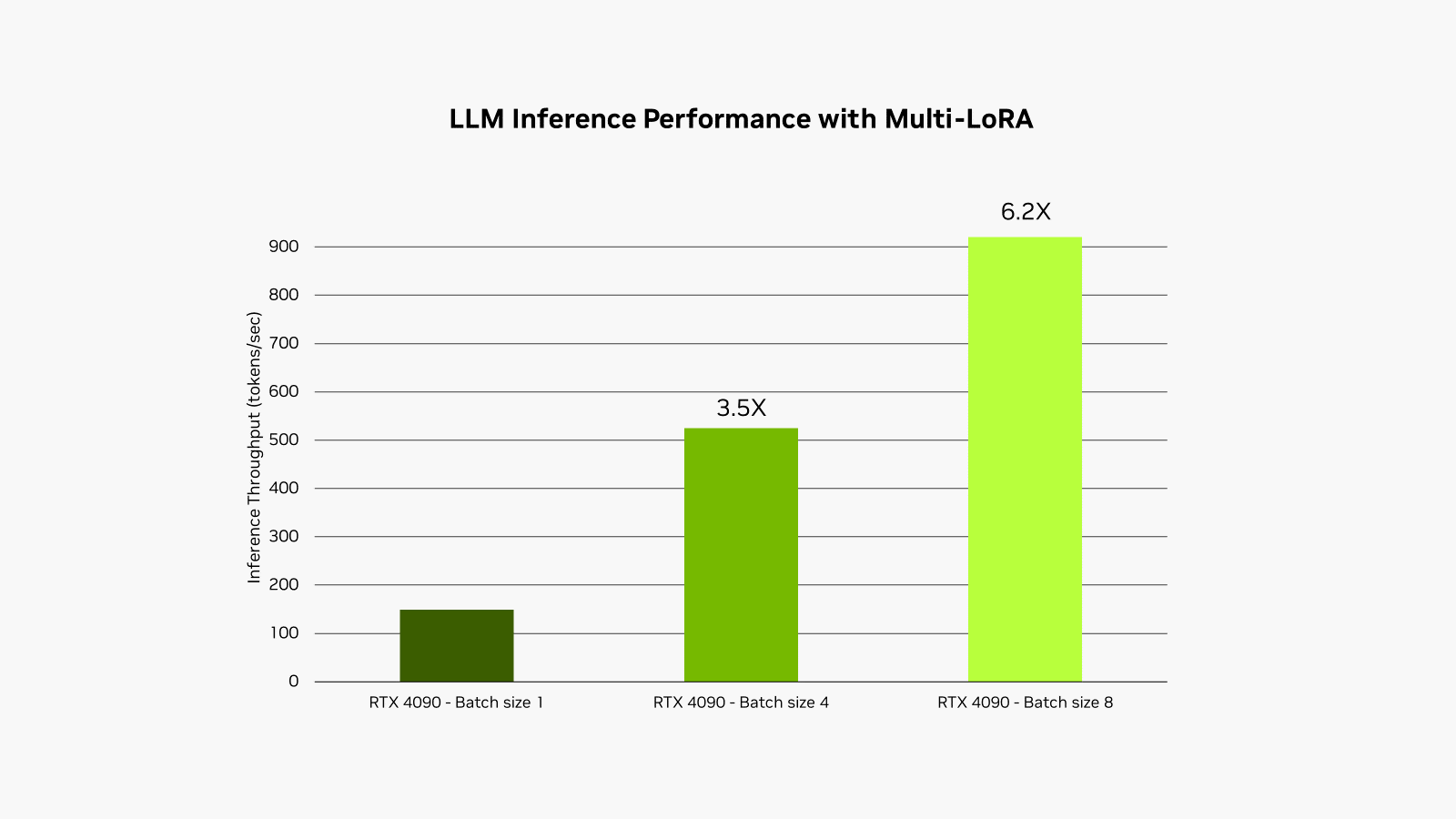
O NVIDIA RTX AI Toolkit facilita o ajuste fino e a implantação de modelos de IA em PCs e workstations RTX com IA por meio de uma técnica chamada adaptação de baixa classificação, ou LoRA. Uma nova atualização, disponível hoje, permite o suporte para o uso de vários adaptadores LoRA simultaneamente na biblioteca de aceleração NVIDIA TensorRT-LLM AI, melhorando o desempenho de modelos ajustados em até 6x.
Ajustado para desempenho
Os LLMs devem ser cuidadosamente personalizados para atingir maior desempenho e atender às crescentes demandas dos usuários.
Esses modelos fundamentais são treinados em grandes quantidades de dados, mas frequentemente não têm o contexto necessário para o caso de uso específico de um desenvolvedor. Por exemplo, um LLM genérico pode gerar diálogos de videogame, mas provavelmente não terá a nuance e a sutileza necessárias para escrever no estilo de um elfo da floresta com um passado sombrio e um desdém mal disfarçado pela autoridade.
Para obter resultados mais personalizados, os desenvolvedores podem ajustar o modelo com informações relacionadas ao caso de uso do aplicativo.
Tomemos o exemplo de desenvolvimento de um aplicativo para gerar diálogos no jogo usando um LLM. O processo de ajuste fino começa com o uso dos pesos de um modelo pré-treinado, como informações sobre o que um personagem pode dizer no jogo. Para obter o diálogo no estilo certo, um desenvolvedor pode ajustar o modelo em um conjunto de dados menor de exemplos, como diálogos escritos em um tom mais assustador ou vilão.
Em alguns casos, os desenvolvedores podem querer executar todos esses diferentes processos de ajuste fino simultaneamente. Por exemplo, eles podem querer gerar uma cópia de marketing escrita em diferentes vozes para vários canais de conteúdo. Ao mesmo tempo, eles podem querer resumir um documento e fazer sugestões estilísticas — bem como rascunhar uma descrição de cena de videogame e um prompt de imagens para um gerador de texto para imagem.
Não é prático executar vários modelos simultaneamente, pois eles não cabem todos na memória da GPU ao mesmo tempo. Mesmo se coubessem, seu tempo de inferência seria impactado pela largura de banda da memória — quão rápido os dados podem ser lidos da memória para as GPUs.
Lo(RA), Lo(RA), Lo(RA)…
Uma maneira popular de abordar esses problemas é usar técnicas de ajuste fino, como adaptação de baixa classificação. Uma maneira simples de pensar nisso é como um arquivo de patch contendo as personalizações do processo de ajuste fino.
Uma vez treinados, os adaptadores LoRA personalizados podem se integrar perfeitamente ao modelo de base durante a inferência, adicionando sobrecarga mínima. Os desenvolvedores podem anexar os adaptadores a um único modelo para atender a vários casos de uso. Isso mantém a pegada de memória baixa, ao mesmo tempo em que fornece os detalhes adicionais necessários para cada caso de uso específico.
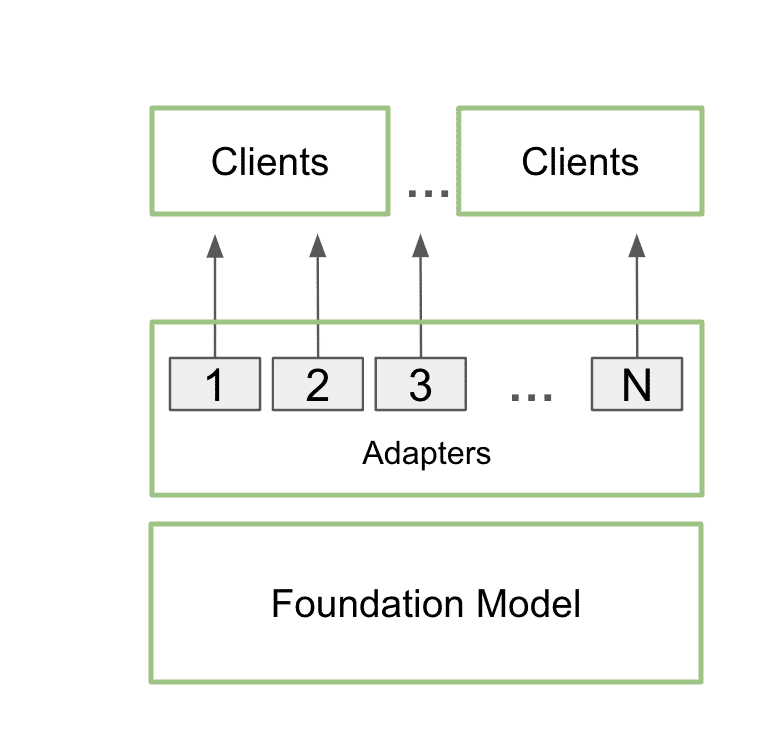
Na prática, isso significa que um aplicativo pode manter apenas uma cópia do modelo base na memória, juntamente com muitas personalizações usando vários adaptadores LoRA.
Esse processo é chamado de serviço multi-LoRA. Quando várias chamadas são feitas para o modelo, a GPU pode processar todas as chamadas em paralelo, maximizando o uso de seus Tensor Cores e minimizando as demandas de memória e largura de banda para que os desenvolvedores possam usar modelos de IA de forma eficiente em seus fluxos de trabalho. Modelos ajustados usando adaptadores multi-LoRA têm desempenho até 6x mais rápido.
No exemplo do aplicativo de diálogo no jogo descrito anteriormente, o escopo do aplicativo poderia ser expandido, usando o serviço multi-LoRA, para gerar elementos de história e ilustrações — orientados por um único prompt.
O usuário poderia inserir uma ideia básica de história, e o LLM desenvolveria o conceito, expandindo a ideia para fornecer uma base detalhada. O aplicativo poderia então usar o mesmo modelo, aprimorado com dois adaptadores LoRA distintos, para refinar a história e gerar imagens correspondentes. Um adaptador LoRA gera um prompt Stable Diffusion para criar visuais usando um modelo Stable Diffusion XL implantado localmente. Enquanto isso, o outro adaptador LoRA, ajustado para escrita de história, poderia criar uma narrativa bem estruturada e envolvente.
Neste caso, o mesmo modelo é usado para ambas as passagens de inferência, garantindo que o espaço necessário para o processo não aumente significativamente. A segunda passagem, que envolve geração de texto e imagem, é realizada usando inferência em lote, tornando o processo excepcionalmente rápido e eficiente em GPUs NVIDIA. Isso permite que os usuários iterem rapidamente por diferentes versões de suas histórias, refinando a narrativa e as ilustrações com facilidade.
Esse processo é descrito com mais detalhes em um blog técnico recente.
Os LLMs estão se tornando um dos componentes mais importantes da IA moderna. À medida que a adoção e a integração crescem, a demanda por LLMs poderosos e rápidos com personalizações específicas para aplicativos só aumentará. O suporte multi-LoRA adicionado hoje ao RTX AI Toolkit oferece aos desenvolvedores uma nova maneira poderosa de acelerar esses recursos.
A IA generativa está transformando jogos, videoconferências e experiências interativas de todos os tipos. Entenda o que há de novo e o que vem por aí assinando a newsletter de IA Decodificada.