
Nota do editor: Este post faz parte da série IA Decodificada, que desmistifica a IA ao tornar a tecnologia mais acessível e que apresenta novos hardware, software, ferramentas e acelerações para usuários de PC RTX.
À medida que a IA generativa avança e se espalha pelos setores, aumenta a importância de executar aplicações de IA generativa em PCs e workstations locais. A inferência local proporciona aos consumidores latência reduzida, elimina a dependência da rede e permite maior controle sobre seus dados.
As GPUs NVIDIA GeForce e NVIDIA RTX apresentam Tensor Cores, aceleradores de hardware de IA dedicados que fornecem potência para executar IA generativa localmente.
O Stable Video Diffusion agora está otimizado para o kit de desenvolvimento de software NVIDIA TensorRT, que desbloqueia a IA generativa de mais alto desempenho em mais de 100 milhões de PCs e workstations com Windows equipados com GPUs RTX.
Agora, a extensão TensorRT para o popular Stable Diffusion WebUI da Automatic1111 está adicionando suporte para ControlNets, ferramentas que oferecem aos usuários mais controle para refinar resultados generativos adicionando outras imagens como orientação.
A aceleração do TensorRT pode ser testada no novo benchmark UL Procyon AI Image Generation, que testes internos mostraram que replica com precisão o desempenho do mundo real. Ele proporcionou acelerações de 50% em uma GPU GeForce RTX 4080 SUPER em comparação com a implementação mais rápida sem TensorRT.
IA mais eficiente e precisa
O TensorRT permite que os desenvolvedores acessem o hardware que fornece experiências de IA totalmente otimizadas. O desempenho da IA normalmente dobra em comparação com a execução do aplicativo em outras estruturas.
Ele também acelera os modelos generativos de IA mais populares, como Stable Diffusion e SDXL. Stable Video Diffusion, o modelo de IA generativa de imagem para vídeo da Stability AI, experimenta uma aceleração de 40% com o TensorRT.
O modelo imagem para vídeo otimizado Stable Video Diffusion 1.1 pode ser baixado em Hugging Face.
Além disso, a extensão TensorRT para Stable Diffusion WebUI aumenta o desempenho em até 2x, simplificando significativamente os fluxos de trabalho do Stable Diffusion.
Com a atualização mais recente da extensão, as otimizações do TensorRT se estendem aos ControlNets — um conjunto de modelos de IA que ajudam a orientar a saída de um modelo de difusão adicionando condições extras. Com o TensorRT, os ControlNets são 40% mais rápidos.
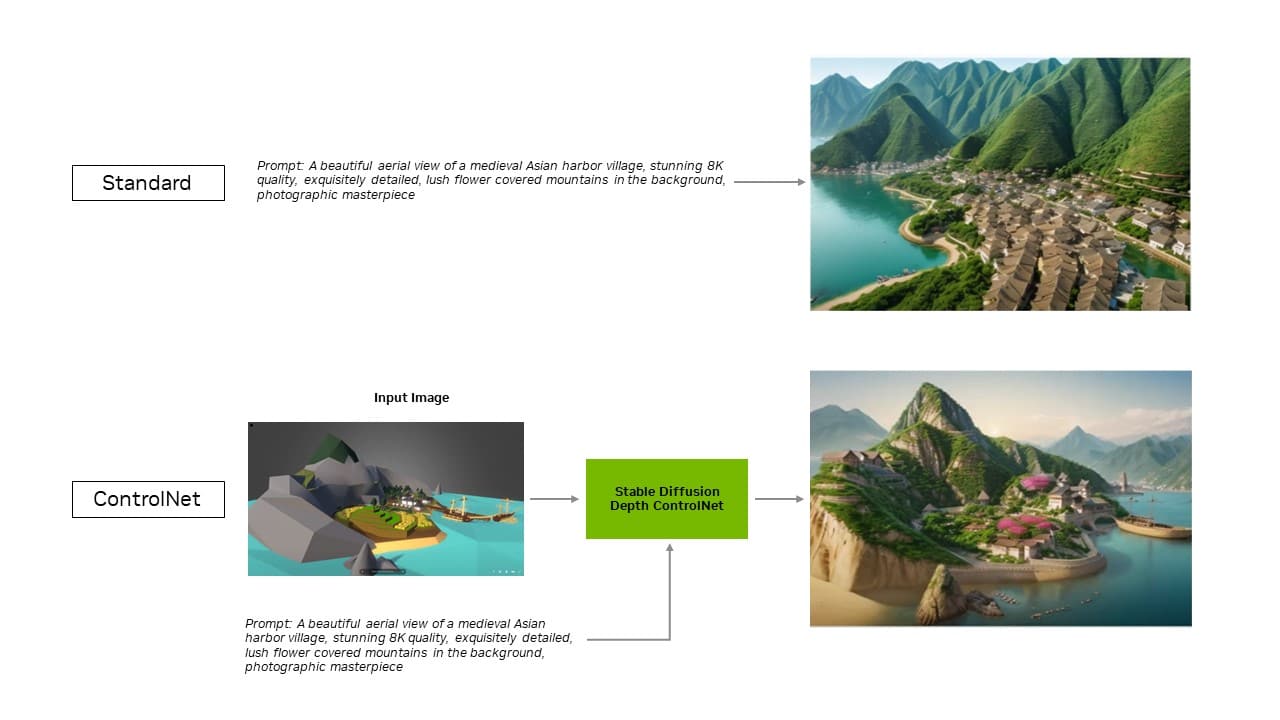
Os usuários podem orientar aspectos da saída para corresponder a uma imagem de entrada, o que lhes dá mais controle sobre a imagem final. Eles também podem usar vários ControlNets juntos para obter um controle ainda maior. Um ControlNet pode ser um mapa de profundidade, mapa de borda, mapa normal ou modelo de detecção de ponto-chave, entre outros.
Baixe a extensão TensorRT para Stable Diffusion Web UI no GitHub hoje mesmo.
Outras aplicações populares aceleradas pelo TensorRT
A Blackmagic Design adotou a aceleração NVIDIA TensorRT na atualização 18.6 do DaVinci Resolve. Suas ferramentas de IA, como Magic Mask, Speed Warp e Super Scale, rodam mais de 50% mais rápido e até 2,3x mais rápido em GPUs RTX em comparação com Macs.
Além disso, com a integração do TensorRT, a Topaz Labs observou um aumento de desempenho de até 60% em suas aplicações Photo AI e Video AI — como remoção de ruído de fotos, nitidez, super resolução de fotos, câmera lenta de vídeo, super resolução de vídeo, estabilização de vídeo e muito mais — todos rodando em RTX.
A combinação do Tensor Cores com o software TensorRT traz desempenho de IA generativa incomparável para PCs e workstations locais. E ao executar localmente, várias vantagens são desbloqueadas:
- Desempenho : os usuários experimentam latência mais baixa, pois a latência se torna independente da qualidade da rede quando todo o modelo é executado localmente. Isso pode ser importante para casos de uso em tempo real, como jogos ou videoconferências. A NVIDIA RTX oferece os aceleradores de IA mais rápidos, com escala para mais de 1.300 trilhões de operações de IA por segundo, ou TOPS.
- Custo : os usuários não precisam pagar por serviços em nuvem, interfaces de programação de aplicações hospedados em nuvem ou custos de infraestrutura para inferência de modelos de linguagem de grande porte.
- Sempre ligado : os usuários podem acessar recursos LLM em qualquer lugar, sem depender de conectividade de rede de alta largura de banda.
- Privacidade de dados : dados privados e proprietários sempre podem permanecer no dispositivo do usuário.
Otimizado para LLMs
O que o TensorRT traz para o aprendizado profundo, o NVIDIA TensorRT-LLM traz para os LLMs mais recentes.
TensorRT-LLM, uma biblioteca de código aberto que acelera e otimiza a inferência LLM, inclui suporte pronto para uso para modelos de comunidade populares, incluindo Phi-2, Llama2, Gemma, Mistral e Code Llama. Qualquer pessoa, desde desenvolvedores e criadores até funcionários corporativos e usuários casuais, pode experimentar modelos otimizados para TensorRT-LLM nos modelos NVIDIA AI Foundation . Além disso, com a demonstração técnica NVIDIA ChatRTX, os usuários podem ver o desempenho de vários modelos executados localmente em um PC com Windows. ChatRTX é baseado em TensorRT-LLM para desempenho otimizado em GPUs RTX.
A NVIDIA está colaborando com a comunidade de código aberto para desenvolver conectores TensorRT-LLM nativos para estruturas de aplicativos populares, incluindo LlamaIndex e LangChain.
Essas inovações tornam mais fácil para os desenvolvedores usarem o TensorRT-LLM com seus aplicativos e experimentarem o melhor desempenho do LLM com RTX.
Receba atualizações semanais diretamente em sua caixa de entrada assinando o newsletter de IA Decodificada.