
Nota do editor: Esta postagem faz parte da série IA Decodificada, que desmistifica a IA ao tornar a tecnologia mais acessível e que apresenta novos hardware, software, ferramentas e acelerações para usuários de PC RTX.
A era do PC com IA chegou e é alimentada pelas tecnologias NVIDIA RTX e GeForce RTX. Com isso, surge uma nova maneira de avaliar o desempenho de tarefas aceleradas por IA e uma nova linguagem que pode ser difícil de decifrar ao escolher entre os desktops e notebooks disponíveis.
Embora os jogadores de PC entendam os frames por segundo (FPS) e estatísticas semelhantes, medir o desempenho da IA requer novas métricas.
Saia na frente com TOPS
A primeira linha de base é TOPS, ou trilhões de operações por segundo. Trilhões é a palavra importante aqui – os números de processamento por trás das tarefas generativas de IA são absolutamente enormes. Pense no TOPS como uma métrica bruta de desempenho, semelhante à classificação de potência de um motor. Mais é melhor.
Compare, por exemplo, a recém-anunciada linha Copilot+ PC da Microsoft, que inclui unidades de processamento neural (NPUs) capazes de executar mais de 40 TOPS. Executar 40 TOPS é suficiente para algumas tarefas leves assistidas por IA, como perguntar a um chatbot local onde estão as anotações de ontem.
Mas muitas tarefas de IA generativa são mais exigentes. As GPUs NVIDIA RTX e GeForce RTX oferecem desempenho sem precedentes em todas as tarefas generativas – a GPU GeForce RTX 4090 oferece mais de 1.300 TOPS. Este é o tipo de potência necessária para lidar com a criação de conteúdo digital assistida por IA, super-resolução de IA em jogos de PC, geração de imagens de texto ou vídeo, consulta de modelos locais de linguagem grande (LLMs) e muito mais.
Insira tokens para jogar
TOPS é apenas o começo da história. O desempenho do LLM é medido no número de tokens gerados pelo modelo.
Os tokens são a saída do LLM. Um token pode ser uma palavra em uma frase ou até mesmo um fragmento menor, como pontuação ou espaço em branco. O desempenho para tarefas aceleradas por IA pode ser medido em “tokens por segundo”.
Outro fator importante é o tamanho do lote, ou o número de entradas processadas simultaneamente em uma única passagem de inferência. Como um LLM estará no centro de muitos sistemas modernos de IA, a capacidade de lidar com múltiplas entradas (por exemplo, de um único aplicativo ou de vários aplicativos) será um diferencial importante. Embora tamanhos de lote maiores melhorem o desempenho para entradas simultâneas, eles também exigem mais memória, especialmente quando combinados com modelos maiores.
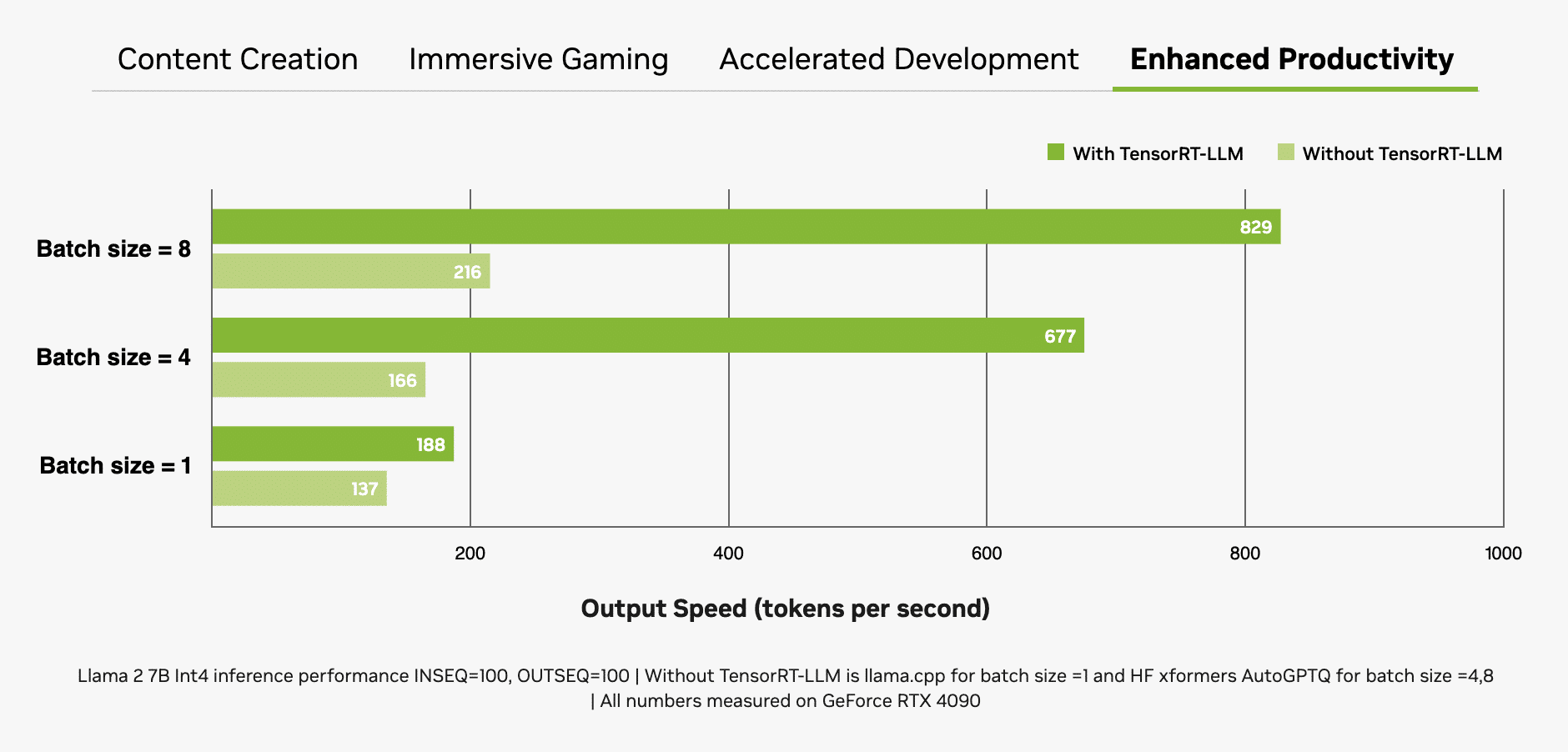
As GPUs RTX são excepcionalmente adequadas para LLMs devido às suas grandes quantidades de memória de acesso aleatório de vídeo (VRAM) dedicada, Tensor Cores e software TensorRT-LLM .
As GPUs GeForce RTX oferecem até 24 GB de VRAM de alta velocidade e as GPUs NVIDIA RTX de até 48 GB, que podem lidar com modelos maiores e permitir tamanhos de lote maiores. As GPUs RTX também aproveitam os Tensor Cores – aceleradores de IA dedicados que aceleram drasticamente as operações computacionalmente intensivas necessárias para aprendizagem profunda e modelos de IA generativos. Esse desempenho máximo é facilmente acessado quando um aplicativo usa o kit de desenvolvimento de software (SDK) NVIDIA TensorRT , que desbloqueia a IA generativa de mais alto desempenho em mais de 100 milhões de PCs e estações de trabalho com Windows equipados com GPUs RTX.
A combinação de memória, aceleradores de IA dedicados e software otimizado proporciona às GPUs RTX enormes ganhos de rendimento, especialmente à medida que o tamanho dos lotes aumenta.
Do texto para a imagem, mais rápido do que nunca
Medir a velocidade de geração de imagens é outra forma de avaliar o desempenho. Uma das maneiras mais diretas usa o Stable Diffusion, um modelo popular de IA baseado em imagens que permite aos usuários converter facilmente descrições de texto em representações visuais complexas.
Com o Stable Diffusion, os usuários podem criar e refinar rapidamente imagens a partir de prompts de texto para obter o resultado desejado. Ao usar uma GPU RTX, esses resultados podem ser gerados mais rapidamente do que processar o modelo de IA em uma CPU ou NPU.
Esse desempenho é ainda maior ao usar a extensão TensorRT para a popular interface Automatic1111. Os usuários RTX podem gerar imagens a partir de prompts até 2x mais rápido com o ponto de verificação SDXL Base – simplificando significativamente os fluxos de trabalho de difusão estável.
ComfyUI, outra interface de usuário popular do Stable Diffusion, adicionou aceleração TensorRT na semana passada. Os usuários RTX agora podem gerar imagens a partir de prompts até 60% mais rápido e podem até converter essas imagens em vídeos usando Stable Video Diffuson até 70% mais rápido com TensorRT.
A aceleração do TensorRT pode ser testada no novo benchmark UL Procyon AI Image Generation, que oferece acelerações de 50% em uma GPU GeForce RTX 4080 SUPER em comparação com a implementação mais rápida sem TensorRT.
A aceleração TensorRT será lançada em breve para Stable Diffusion 3 – o novo e altamente aguardado modelo de texto para imagem da Stability AI – aumentando o desempenho em 50%. Além disso, o novo TensorRT-Model Optimizer permite acelerar ainda mais o desempenho. Isso resulta em uma aceleração de 70% em comparação com a implementação não TensorRT, juntamente com uma redução de 50% no consumo de memória.
Claro, ver para crer – o verdadeiro teste está no caso de uso do mundo real de iteração em um prompt original. Os usuários podem refinar a geração de imagens ajustando os prompts de forma significativamente mais rápida em GPUs RTX, levando segundos por iteração em comparação com minutos em um Macbook Pro M3 Max. Além disso, os usuários obtêm velocidade e segurança com tudo permanecendo privado ao executar localmente em um PC ou estação de trabalho com tecnologia RTX.
Os resultados estão disponíveis e são de código aberto
Mas não acredite apenas na nossa palavra. A equipe de pesquisadores e engenheiros de IA por trás do Jan.ai de código aberto integrou recentemente o TensorRT-LLM em seu aplicativo chatbot local e, em seguida, testou essas otimizações por conta própria.

Os pesquisadores testaram sua implementação do TensorRT-LLM em relação ao mecanismo de inferência de código aberto llama.cpp em uma variedade de GPUs e CPUs usadas pela comunidade. Eles descobriram que o TensorRT é “30-70% mais rápido que o llama.cpp no mesmo hardware”, bem como mais eficiente em execuções de processamento consecutivas. A equipe também incluiu sua metodologia, convidando outras pessoas a medir o desempenho da IA generativa por si mesmas.
Dos jogos à IA generativa, a velocidade vence. TOPS, imagens por segundo, tokens por segundo e tamanho do lote são considerações ao determinar os campeões de desempenho.
A IA generativa está transformando jogos, videoconferências e experiências interativas de todos os tipos. Entenda o que há de novo e o que vem por aí assinando a newsletter de IA Decodificada.