
Todo modelo de IA revolucionário começa da mesma forma: com uma execução de treinamento. A infraestrutura que sustenta esses trabalhos de treinamento molda tudo: a velocidade com que as equipes podem iterar, a escala do modelo que podem construir e se esses trabalhos são concluídos de forma confiável.
À medida que os modelos crescem em tamanho, complexidade e inteligência, as demandas sobre a infraestrutura de treinamento também aumentam.
No MLPerf Training 6.0 — o mais recente de uma série de benchmarks rigorosos e revisados por pares para avaliação do desempenho de treinamento de IA — a plataforma NVIDIA Blackwell liderou em todas as categorias, demonstrando:
- Tempo de treinamento mais rápido em todos os benchmarks
- Treinamento em maior escala com 8.192 GPUs usando sistemas NVIDIA Blackwell NVL72
- A única plataforma com submissões em todos os sete benchmarks do conjunto
A NVIDIA reúne desempenho, escala e confiabilidade em uma única plataforma, projetada por meio de codesign extremo, para permitir que desenvolvedores de modelos de IA lancem modelos de fronteira com mais rapidez, minimizem os custos de treinamento e comecem a gerar receita mais cedo.
Desempenho: Tempo de Treinamento Mais Rápido em Todos os Benchmarks
O MLPerf Training 6.0 adicionou dois novos workloads de pré-treinamento de mixture-of-experts (MoE) ao conjunto: DeepSeek-V3 671B e GPT-OSS-20B, refletindo a crescente centralidade das arquiteturas MoE. A plataforma NVIDIA foi a única submetida em todos os benchmarks e entregou o tempo de treinamento mais rápido em todos os sete.

Nesta rodada, a NVIDIA submeteu resultados nos sistemas rack-scale NVIDIA GB200 NVL72 e GB300 NVL72. Em cada sistema rack-scale, os NVLink Switches de quinta geração da NVIDIA conectam todas as 72 GPUs com alta largura de banda, formando um pool unificado de computação e memória, permitindo que funcionem como uma única GPU gigante.
O treinamento MoE em larga escala enfrenta o mesmo desafio de comunicação all-to-all da inferência MoE — os tokens precisam ser roteados entre GPUs para alcançar a sub-rede de especialistas correta — e a vantagem de largura de banda do NVLink é o que torna isso rápido e eficiente em escala.
A NVIDIA também apresentou métodos de treinamento NVFP4 que aumentam o desempenho enquanto atendem a requisitos rigorosos de precisão em workloads de pré-treinamento em grande e pequena escala, além de workloads de ajuste fino. A NVIDIA continua a impulsionar a inovação em treinamento de baixa precisão em diferentes arquiteturas de modelos, usando mais recentemente o NVFP4 para pré-treinar o enorme modelo NVIDIA Nemotron 3 Ultra com 550 bilhões de parâmetros.
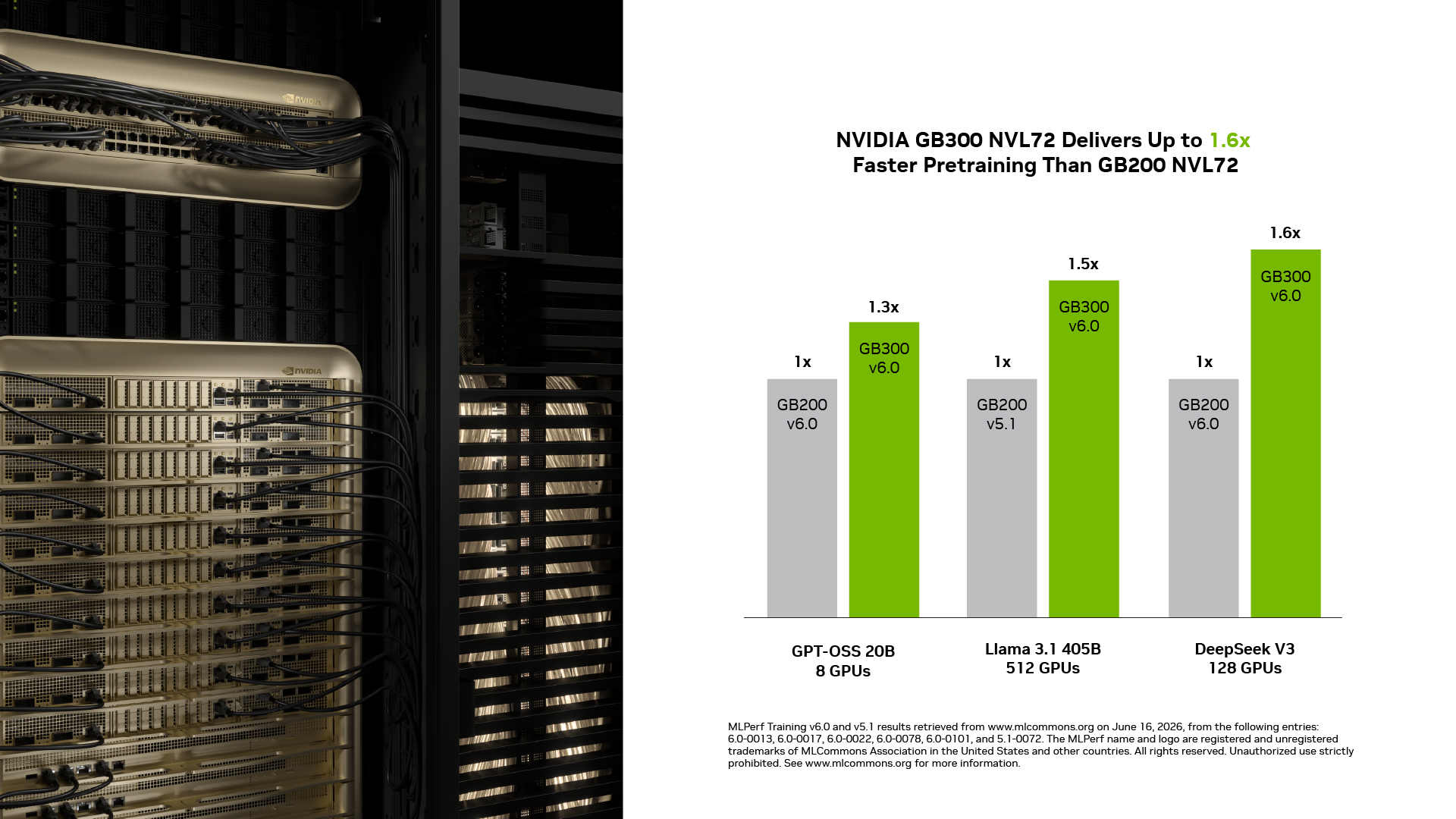
NVIDIA GB300 NVL72 entregou até 1,6x de desempenho em relação ao GB200 NVL72: Nesta rodada, o GB300 NVL72 entregou treinamento até 1,6x mais rápido do que o GB200 NVL72 na mesma escala. Capacidades-chave do Blackwell Ultra, como maior densidade computacional com NVFP4, capacidade de memória expandida e um teto de energia mais alto que permite à GPU sustentar desempenho de pico, impulsionam essa melhoria.
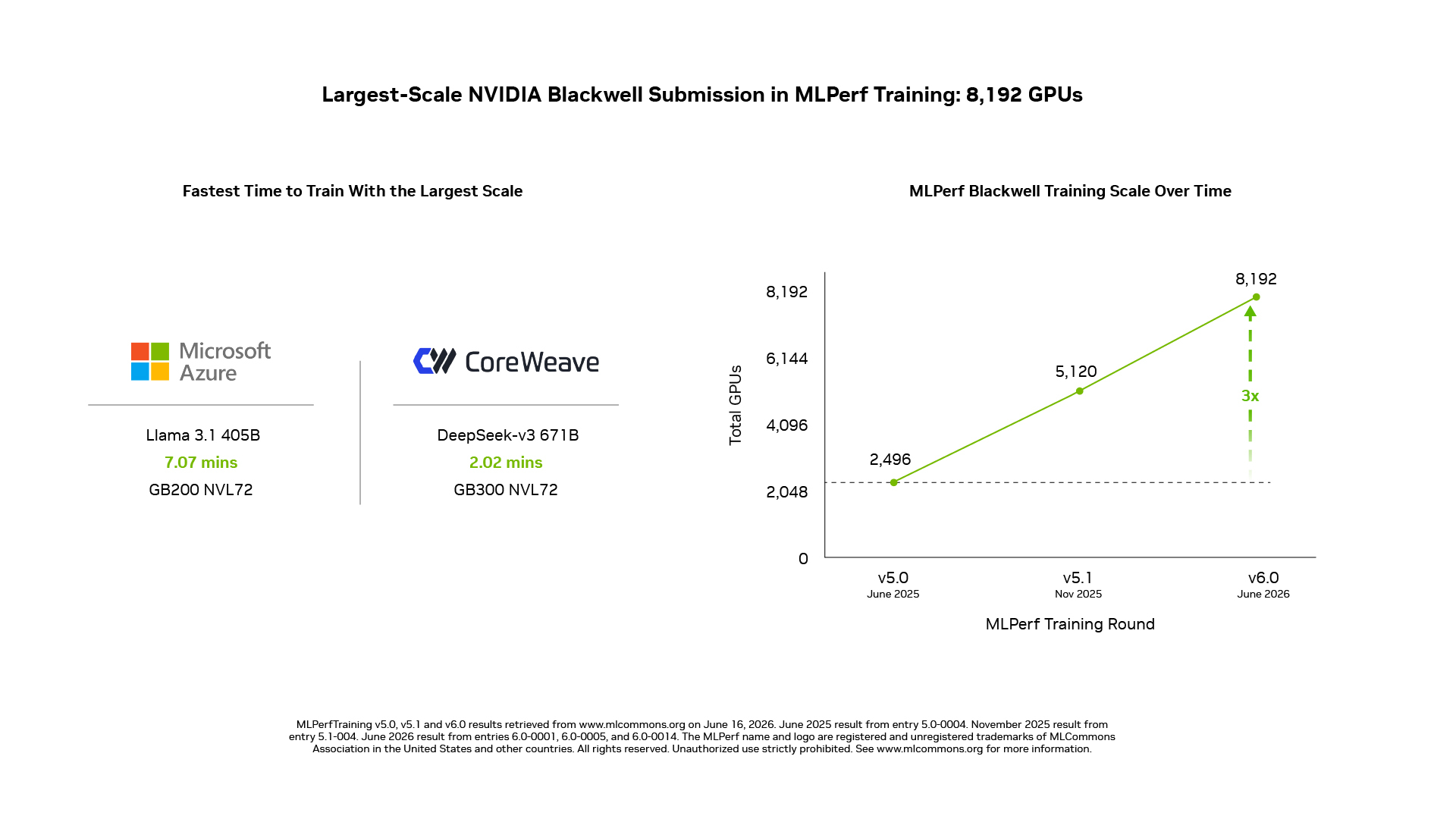
Escala: Maior Cluster Blackwell no MLPerf Training
Para oferecer suporte ao treinamento distribuído em escala, a NVIDIA oferece duas plataformas de rede scale-out complementares — NVIDIA Quantum InfiniBand e NVIDIA Spectrum-X Ethernet — dando aos data centers a flexibilidade para construir clusters de grande escala otimizados para sua infraestrutura.
No DeepSeek-V3 671B, o maior modelo MoE do conjunto, a NVIDIA escalou sua submissão para 8.192 GPUs usando sistemas GB200 NVL72 — a maior submissão baseada em Blackwell no MLPerf Training até o momento.
A NVIDIA também submeteu resultados com 5.120 GPUs em sistemas NVIDIA GB200 NVL72 para o Llama 3.1 405B, um dos maiores LLMs densos do conjunto.
Os resultados desta rodada também refletem a profunda co-engenharia entre a NVIDIA e seus parceiros em arquitetura de sistemas, redes e software:
- O Microsoft Azure escalou o treinamento do Llama 3.1 405B para 8.192 GPUs usando sistemas GB200 NVL72, e atingiu o alvo de qualidade de referência em 7,07 minutos — o tempo de treinamento mais rápido para este benchmark.
- A CoreWeave entregou o tempo de treinamento mais rápido para o DeepSeek-V3 671B, atingindo o alvo de qualidade em 2,02 minutos na escala de 8.192 GPUs usando sistemas GB300 NVL72 conectados com rede Spectrum-X Ethernet.
Confiabilidade em Escala: Projetado para Produção
Em ambientes de treinamento em produção, as execuções podem durar semanas ou meses em centenas de milhares de GPUs. Nessa escala, o throughput efetivo de treinamento depende tanto do desempenho do sistema quanto da resiliência que o torna reproduzível ao longo do tempo.
Os resultados do MLPerf Training v6.0 acima falam ao desempenho da plataforma da NVIDIA. Para resiliência, a plataforma da NVIDIA é projetada em duas dimensões:
- Menos interrupções: As GPUs NVIDIA são construídas para evitar falhas antes que ocorram. Antes de uma GPU chegar a um data center, a NVIDIA a submete a mais de 30 etapas de testes de fabricação para detectar falhas potenciais precocemente. Uma vez implantado, o Reliability, Availability and Serviceability Engine monitora quase todo o chip, e capacidades de autocorreção roteiam automaticamente ao redor de falhas detectadas sem interromper o workload. No nível de rede, o Spectrum-X Ethernet redireciona ao redor de links com falha em milissegundos, mantendo o fabric saudável sem interromper o trabalho.
- Recuperação mais rápida quando ocorrem interrupções: O NVIDIA Resiliency Extension, ou NVRx, minimiza o tempo perdido quando falhas ocorrem, com capacidades que abrangem detecção de falhas, recuperação e monitoramento de integridade em todo o cluster. Ele detecta e gerencia automaticamente nós com baixo desempenho antes que eles desacelerem o restante do cluster. Quando um nó sofre uma interrupção, em vez de reiniciar todo o trabalho, o sistema retoma a partir de um checkpoint recente — um snapshot salvo do estado de treinamento.
IA de Fronteira Construída na NVIDIA
Os parceiros do ecossistema NVIDIA também participaram extensivamente nesta rodada, com submissões de 19 organizações, incluindo ASUSTeK, Microsoft Azure, Cisco, CoreWeave, Dell Technologies, Fujitsu, Giga Computing, Google Cloud, Hewlett Packard Enterprise, Inventec, Krai, Lambda, Nebius, Netweb Technologies India Ltd., Quanta Cloud Computing (QCT), Scitix, Supermicro e TTA. Muitos desses parceiros executam alguns dos workloads de treinamento de IA mais exigentes na infraestrutura NVIDIA.
A CoreWeave, que hospeda sua infraestrutura NVIDIA em sistemas Dell PowerRack com servidores Dell PowerEdge, abriga vários desses workloads. A Cohere alcançou treinamento 3x mais rápido no GB200 NVL72 para sua plataforma de IA agêntica North. A Midjourney, que treinou seu modelo de geração de imagens v8 em um cluster Blackwell, está agora escalando uma grande frota de GPUs Blackwell Ultra na CoreWeave para treinar futuros modelos de imagem e vídeo.
No Google Cloud, o Thinking Machines Lab observou velocidades de treinamento e serviço 2x mais rápidas no GB300 NVL72 em comparação com GPUs da geração anterior, acelerando pesquisas de modelos de fronteira e workflows de aprendizado por reforço.
A Nebius, executando infraestrutura NVIDIA Blackwell e Blackwell Ultra em sua nuvem de IA, permitiu que a Higgsfield reduzisse o tempo de treinamento de modelos em 30%, suportando uma plataforma que agora atende a 22 milhões de usuários e gera mais de 6 milhões de conteúdos de IA por dia.
Para uma análise técnica mais aprofundada dos resultados do MLPerf Training 6.0 e das otimizações por trás deles, leia este blog técnico.
