A inferência, que é o processo de usar AI em softwares, está começando a ter usos convencionais e ser executada com uma rapidez inédita.
As GPUs NVIDIA ganharam em todos os testes de inferência de AI em sistemas de data center e computação no edge na mais atual edição dos únicos benchmarks do setor baseados em um consórcio e revisados por pares.
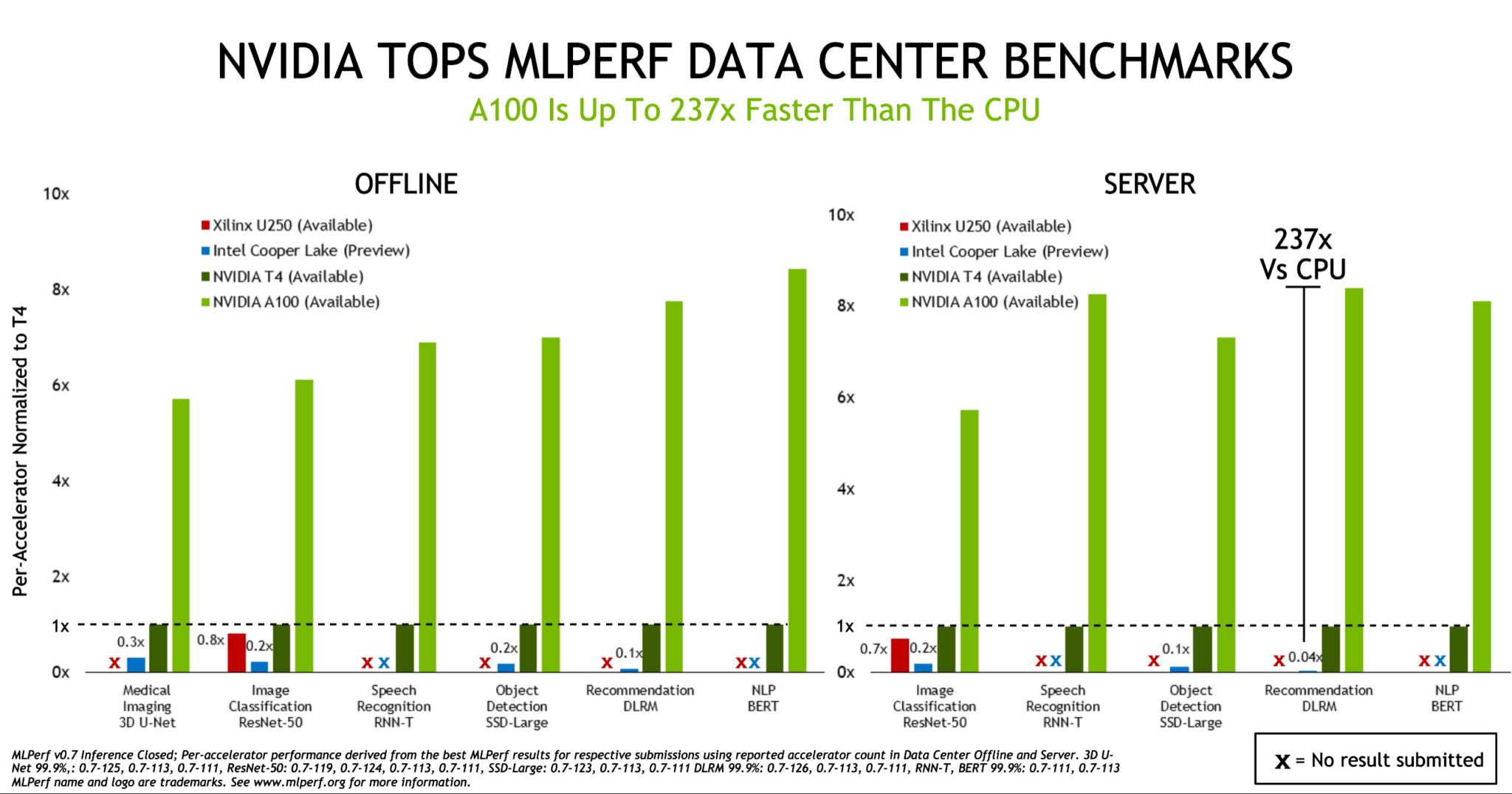
As GPUs NVIDIA A100 Tensor Core mostraram, mais uma vez, que oferecem o melhor desempenho, como visto nos primeiros testes de inferência de AI realizados no ano passado pelo MLPerf, um consórcio de benchmarking do setor formado em maio de 2018.
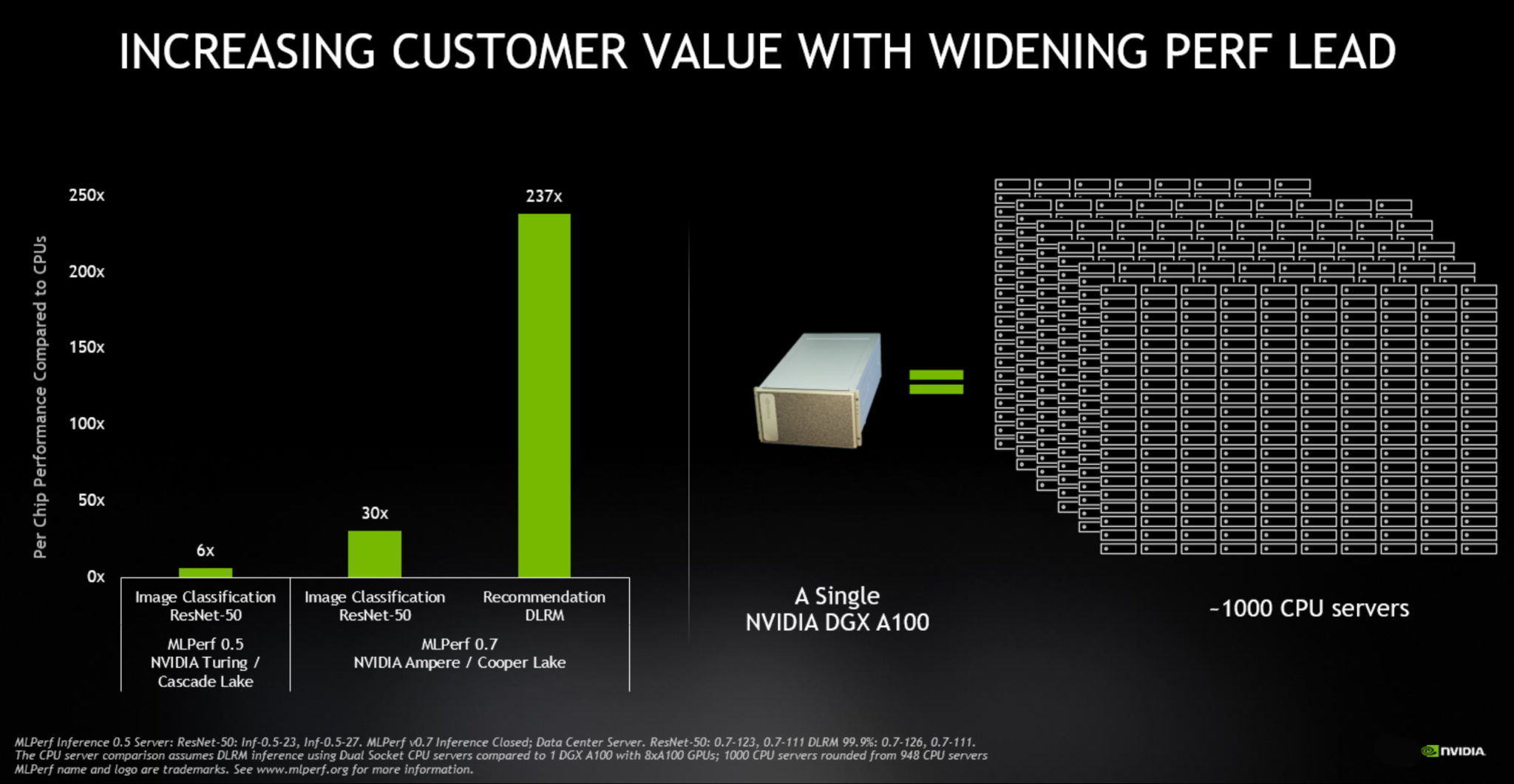
As A100, lançadas em maio, apresentaram um desempenho até 237 vezes superior ao das CPUs na inferência de data centers, de acordo com os benchmarks MLPerf Inference 0.7. As GPUs NVIDIA T4, compactas e com eficiência energética, foram até 28 vezes melhores que as CPUs nos mesmos testes.
Para se ter uma ideia melhor, um único sistema NVIDIA DGX A100 com oito GPUs A100 oferece o mesmo desempenho que quase mil servidores com CPUs de soquete duplo em algumas aplicações de AI.
Nessa edição de benchmarks, também houve mais participantes: 23 empresas enviaram os dados de seus produtos (na última edição, foram apenas 12), e os parceiros da NVIDIA usaram a plataforma de AI da NVIDIA em mais de 85% do total de produtos participantes.
GPUs A100 e Jetson AGX Xavier Mostram Desempenho no Edge
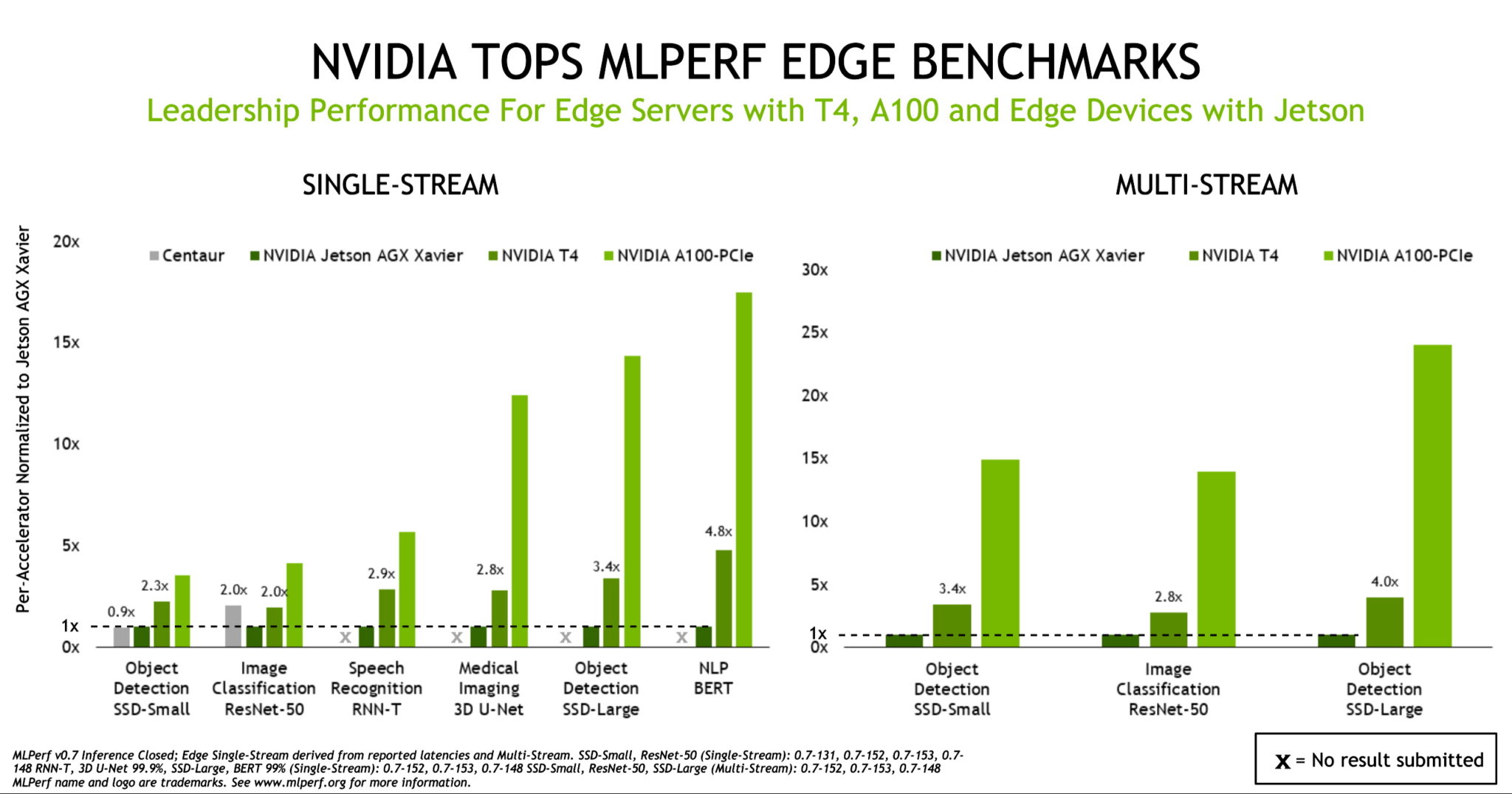
Embora o desempenho da inferência de AI esteja chegando a novos patamares com as A100, os benchmarks mostram que a T4 continua sendo uma plataforma de inferência segura para as principais empresas, servidores edge e instâncias de cloud econômicas. Além disso, o NVIDIA Jetson AGX Xavier evidencia sua posição de liderança em dispositivos no edge baseados em SoC com restrição de energia por servir para todos os novos casos de uso.
Os resultados também mostram que nosso ecossistema de AI está forte e em crescimento, pois enviou 1.029 resultados com soluções da NVIDIA, representando 85% do total de produtos participantes das categorias de data center e edge. Os produtos mostraram um desempenho consistente em todos os sistemas dos parceiros, como Altos, Atos, Cisco, Dell EMC, Dividiti, Fujitsu, Gigabyte, Inspur Electronic Information, Lenovo, Nettrix e QCT.
A Expansão dos Casos de Uso Leva a AI para a Vida Diária
Os benchmarks do MLPerf contam com o amplo suporte do setor e do meio acadêmico, desenvolvendo-se constantemente para representar os casos de uso do setor. Algumas das empresas apoiadoras são Amazon, ARM, Baidu, Facebook, Google, Harvard, Intel, Lenovo, Microsoft, NVIDIA, Stanford, a Universidade de Toronto e a NVIDIA.
Os benchmarks mais atuais apresentaram quatro novos testes, destacando o cenário em expansão da AI. Agora, o conjunto classifica o desempenho em processamento de linguagem natural, diagnósticos por imagens, sistemas de recomendação e reconhecimento de fala, além de casos de uso da AI na visão computacional.
Basta observar um mecanismo de busca para ver como o processamento de linguagem natural afeta a vida diária.
“Com as recentes inovações em AI na compreensão de linguagem natural, um número cada vez maior de serviços de AI, como o Bing, está oferecendo uma interação mais natural, garantindo resultados, respostas e recomendações precisas e úteis em menos de um segundo”, afirmou Rangan Majumder, Vice-Presidente de Pesquisa e Inteligência Artificial da Microsoft.
“Os benchmarks do MLPerf, padrão do setor, oferecem dados de desempenho relevantes sobre as redes de AI mais usadas e ajudam a tomar decisões de compras em plataformas informadas por AI”, declarou.
AI Ajuda a Salvar Vidas na Pandemia
O impacto da AI em diagnósticos por imagens é ainda maior. A startup Caption Health, por exemplo, usa AI para facilitar o trabalho de realizar ecocardiogramas, um recurso que ajudou a salvar vidas em hospitais dos Estados Unidos no começo da pandemia de COVID-19.
É por isso que os líderes da AI na área da saúde veem modelos como o 3D U-net, usados nos benchmarks mais atuais do MLPerf, como os principais contribuintes.
“Nós colaboramos com a NVIDIA para oferecer inovações como o 3D U-Net para a área da saúde”, afirmou Klaus Maier-Hein, Diretor de Computação de Diagnósticos por Imagens do Centro Alemão de Pesquisa do Câncer (DKFZ).
“A visão computacional e os exames de imagem são os elementos mais importantes da pesquisa em AI, contribuindo para descobertas científicas e representando os principais componentes do atendimento médico. Além disso, os benchmarks padrão do MLPerf oferecem dados de desempenho relevantes que ajudam organizações de IT e desenvolvedores a acelerar seus projetos e softwares específicos”, complementou.
No mercado, os casos de uso da AI, como os sistemas de recomendação, que também fazem parte dos testes mais atuais do MLPerf, já estão causando um grande impacto. A Alibaba usou os sistemas de recomendação em novembro para processar US$ 38 bilhões em vendas on-line no Dia dos Solteiros chinês, o maior dia de compras do ano.
Adoção da Inferência de AI da NVIDIA Chega a Momento Decisivo
Neste ano, a inferência de AI atingiu um marco importante.
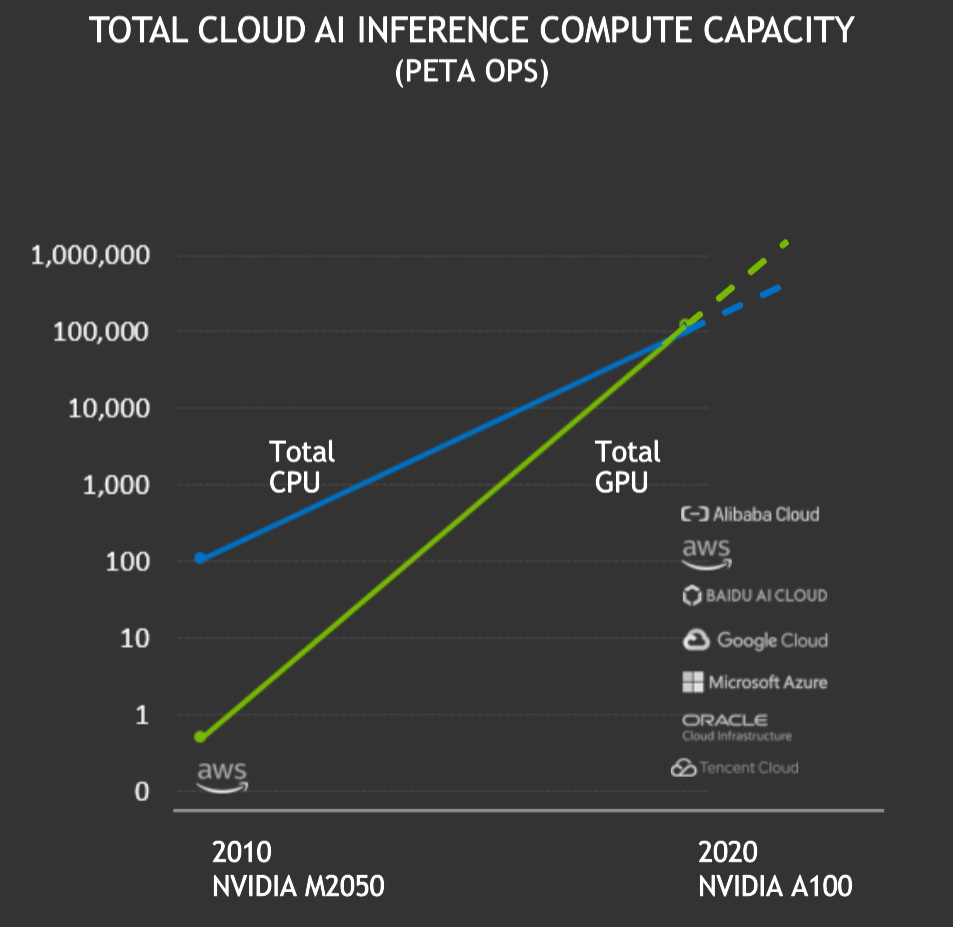
As GPUs NVIDIA ofereceram um total de mais de 100 exaflops de desempenho de inferência de AI no cloud público nos últimos 12 meses, ultrapassando as inferências nas CPUs no cloud pela primeira vez. A capacidade de computação total da inferência de AI no cloud das GPUs NVIDIA aumentou aproximadamente dez vezes a cada dois anos.
Agora, com o desempenho, a usabilidade e a disponibilidade excelentes da computação das GPUs NVIDIA, há um número cada vez maior de empresas de vários setores, como automotivo, cloud, robótica, área da saúde, varejo, serviços financeiros e manufatura, que dependem das GPUs NVIDIA para realizar a inferência de AI. Entre elas estão American Express, BMW, Capital One, Domino’s, Ford, GE Healthcare, Kroger, Microsoft, Samsung e Toyota.

Por que a Inferência de AI É Difícil
É evidente que os casos de uso da AI estão aumentando, mas a inferência de AI é difícil por vários motivos.
Sempre há novos tipos de redes neurais, como as redes generativas adversariais, para novos casos de uso, e os modelos estão crescendo exponencialmente. Agora, os melhores modelos de linguagem para AI contam com bilhões de parâmetros, e as pesquisas no campo estão só começando.
Esses modelos precisam ser executados no cloud, em data centers corporativos e no edge da rede. Isso significa que os sistemas que os executam precisam ser altamente programáveis para funcionar com excelência em várias dimensões.
O fundador e CEO da NVIDIA, Jensen Huang, identificou as dificuldades da inferência moderna de AI: ela precisa de excelência na programação, na latência, na precisão, no tamanho do modelo, no rendimento, na eficiência energética e na velocidade de aprendizagem.
Nosso foco é sempre melhorar a plataforma de AI de ponta a ponta para realizar tarefas exigentes de inferência e, assim, garantir a excelência em todas as dimensões.
AI Exige Desempenho e Usabilidade
Um acelerador como a A100, com sua terceira geração de Tensor Cores e a flexibilidade da arquitetura de GPU multi-instância, é apenas o começo. É preciso ter um pacote completo de softwares para garantir resultados dignos de liderança.
O software de AI da NVIDIA começa com uma série de modelos pré-treinados prontos para executar a inferência de AI. Com o Kit de Ferramentas de Transfer Learning, os usuários podem otimizar os modelos para seus casos de uso e conjuntos de dados específicos.
O NVIDIA TensorRT otimiza modelos treinados para a realização de inferências. Com 2 mil otimizações, ele já foi baixado 1,3 milhão de vezes por 16 mil organizações.
O Servidor de Inferência NVIDIA Triton oferece um ambiente configurado para executar os modelos de AI, sendo compatível com várias GPUs e frameworks. O processo é simples: os softwares enviam a consulta e as restrições, como o tempo de resposta necessário ou a taxa de transferência que precisa ser adaptada para milhares de usuários, e o Triton cuida do resto.
Esses elementos são executados no CUDA-X AI, um pacote sofisticado de bibliotecas de softwares baseadas na famosa plataforma de computação acelerada.
Começando a Toda com Frameworks de Aplicações
Além de tudo isso, nossos frameworks de aplicações aceleram a adoção da AI corporativa em diferentes setores e casos de uso.
Entre os frameworks estão o NVIDIA Merlin para sistemas de recomendação, o NVIDIA Jarvis para AI conversacional, o NVIDIA Maxine para videoconferências, o NVIDIA Clara para a área da saúde e muitos outros já disponíveis.
Esses frameworks, juntamente com as otimizações dos benchmarks mais atuais do MLPerf, estão disponíveis no NGC, o hub de softwares acelerados por GPU que é executado em todos os sistemas e serviços em cloud dos OEMs certificados pela NVIDIA.
Assim, o trabalho pesado que realizamos trará vantagens para toda a comunidade.