A NVIDIA e seus parceiros continuaram a oferecer o melhor desempenho geral de treinamento em AI e o maior número de envios em todos os benchmarks, com 90% dos envios provenientes do ecossistema, de acordo com os benchmarks do MLPerf divulgados hoje.
A plataforma de AI da NVIDIA cobriu os oito benchmarks da rodada do Treinamento MLPerf 2.0, destacando sua versatilidade líder.
Nenhum outro acelerador executou todos os benchmarks, que representam casos de uso populares de AI, incluindo reconhecimento de fala, processamento de linguagem natural, sistemas de recomendação, detecção de objetos, classificação de imagens e muito mais. A NVIDIA tem um desempenho bem consistente desde seu primeiro envio em dezembro de 2018 para a primeira rodada do MLPerf, um pacote padrão do setor de benchmarks de AI.
Resultados Líderes de Benchmark, Disponibilidade
Em seu quarto envio consecutivo para o Treinamento MLPerf, a GPU NVIDIA A100 Tensor Core, baseada na arquitetura NVIDIA Ampere, continuou a se destacar.

O Selene, nosso supercomputador de AI interno baseado no NVIDIA DGX SuperPOD modular e com a tecnologia de GPUs NVIDIA A100, nosso pacote de softwares e redes NVIDIA InfiniBand, apresentou menor tempo para treinar em quatro dos oito testes.
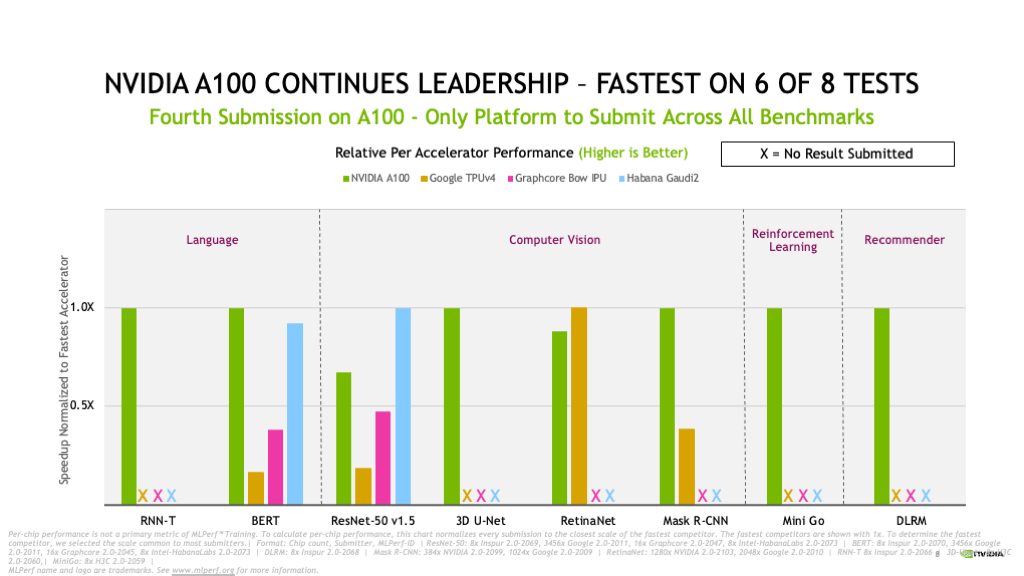
A NVIDIA A100 também continuou sua liderança por chip, provando ser a mais rápida em seis dos oito testes.
Ao todo, 16 parceiros enviaram os resultados nesta rodada usando a plataforma de AI NVIDIA. Entre eles estão ASUS, Baidu, CASIA (Institute of Automation, Chinese Academy of Sciences), Dell Technologies, Fujitsu, GIGABYTE, New H3C Information Technologies, Hewlett Packard Enterprise, Inspur Electronic Information, KRAI, Lenovo, Microsoft Azure, MosaicML, Nettrix e Supermicro.
A maioria dos nossos parceiros OEM enviou resultados usando Sistemas Certificados pela NVIDIA, servidores validados pela NVIDIA para oferecer ótimo desempenho, capacidade de gerenciamento, segurança e escalabilidade para implantações empresariais.
Muitos Modelos Impulsionam Aplicações Reais de AI
Uma aplicação de AI pode precisar entender a solicitação falada do usuário, classificar uma imagem, fazer uma recomendação e dar uma resposta em forma de mensagem falada.
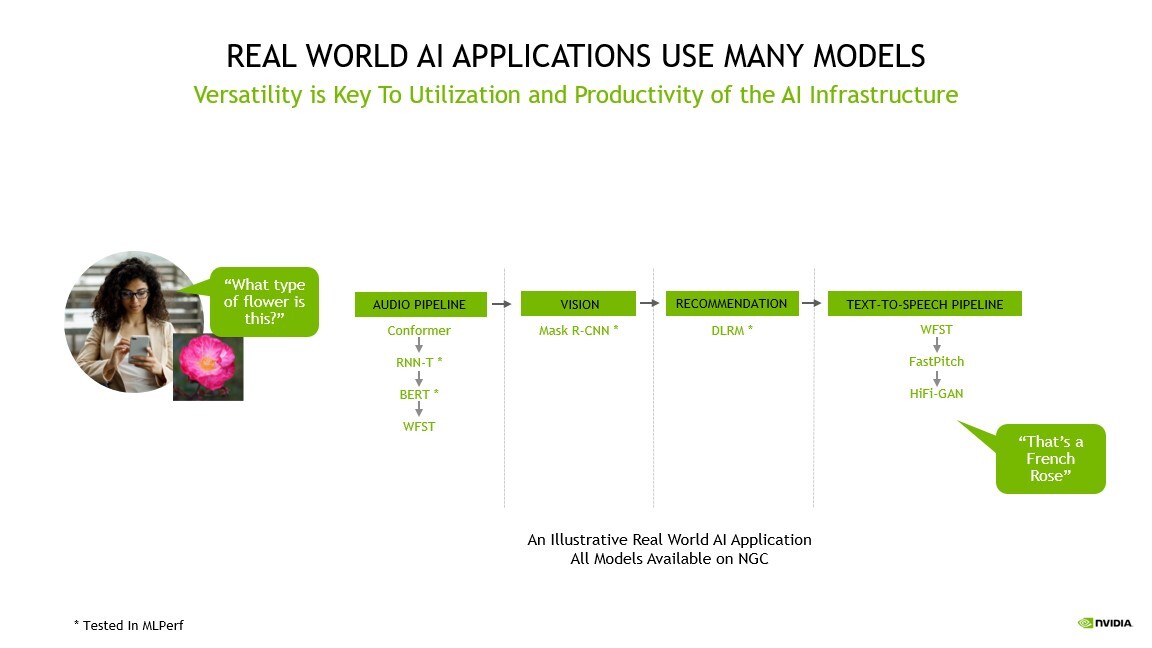
Até mesmo o caso de uso mais simples mostrado acima requer quase 10 modelos, destacando a importância de executar todos os benchmarks
Essas tarefas exigem vários tipos de modelos de AI para funcionar em sequência, também conhecido como pipeline. Os usuários precisam projetar, treinar, implantar e otimizar esses modelos de forma rápida e flexível.
É por isso que tanto a versatilidade quanto a capacidade de executar todos os modelos no MLPerf e além, bem como o desempenho líder são fundamentais para levar a AI do mundo real à produção.
Gerando ROI com AI
Para os clientes, as equipes de ciência de dados e engenharia são seus recursos mais preciosos, e sua produtividade determina o retorno sobre o investimento para a infraestrutura de AI. Os clientes devem considerar o custo das equipes caras de ciência de dados, que, muitas vezes, desempenham um papel significativo no custo total de implantação de AI, bem como no custo relativamente pequeno de implantação da própria infraestrutura de AI.
A produtividade de pesquisadores de AI depende da capacidade de testar rapidamente novas ideias, exigindo tanto a versatilidade para treinar qualquer modelo quanto a velocidade oferecida pelo treinamento desses modelos em maior escala. É por isso que as organizações se concentram na produtividade geral por dólar para determinar as melhores plataformas de AI; uma visão mais abrangente que representa mais precisamente o verdadeiro custo de implantação de AI.
Além disso, o uso de sua infraestrutura de AI depende de sua fungibilidade ou da capacidade de acelerar todo o workflow de AI, desde a preparação de dados até o treinamento e a inferência, em uma única plataforma.
Com a AI da NVIDIA, os clientes podem usar a mesma infraestrutura para todo o pipeline de AI, redefinindo-a para corresponder às variadas demandas entre preparação, treinamento e inferência de dados, o que aumenta significativamente a utilização, levando a um ROI muito alto.
Além disso, à medida que os pesquisadores descobrem novos avanços em AI, apoiar as últimas inovações de modelos é fundamental para maximizar a vida útil da infraestrutura de AI.
A AI da NVIDIA oferece a maior produtividade por dólar, pois é universal e tem desempenho para todos os modelos, dimensiona para qualquer tamanho e acelera a AI de ponta a ponta, desde a preparação de dados até o treinamento e a inferência.
Os resultados de hoje mostram a ampla e profunda experiência em AI da NVIDIA em todas as rodadas de treinamento do MLPerf, inferência e HPC até hoje.
23 Vezes Mais Desempenho em 3,5 Anos
Nos dois anos desde nosso primeiro envio ao MLPerf com a A100, nossa plataforma oferece um desempenho 6 vezes maior. Otimizações contínuas em nosso pacote de softwares ajudaram a impulsionar esses ganhos.
Desde o advento do MLPerf, a plataforma de AI da NVIDIA forneceu um desempenho 23 vezes maior em 3,5 anos no benchmark, resultado de uma inovação no pacote completo que abrange GPUs, software e melhorias em escala. É esse compromisso contínuo com a inovação que garante aos clientes que a plataforma de AI em que investem hoje e se mantém em serviço por 3 a 5 anos, continuará avançando para apoiar a tecnologia de ponta.
Além disso, a arquitetura NVIDIA Hopper, anunciada em março, promete outro grande salto em desempenho nas próximas rodadas do MLPerf.
Como Conseguimos
A inovação em software continua a liberar mais desempenho na arquitetura NVIDIA Ampere.
Por exemplo, o CUDA Graphs, um software que ajuda a minimizar a sobrecarga de inicialização de tarefas executadas em muitos aceleradores, é amplamente usado em nossos envios. Kernels otimizados em nossas bibliotecas, como cuDNN e pré-processamento no DALI, desbloquearam mais acelerações. Também implementamos melhorias no pacote completo em hardware, software e redes, como o NVIDIA Magnum IO e o SHARP, que transferem algumas funções de AI para a rede para gerar um desempenho ainda maior, especialmente em escala.
Todo o software que usamos está disponível no repositório do MLPerf para que todos possam obter nossos resultados superiores. Nós sempre colocamos essas otimizações em contêineres disponíveis no NGC, nosso hub de softwares para aplicações de GPU, e oferecemos o NVIDIA AI Enterprise para proporcionar um software otimizado e totalmente compatível com a NVIDIA.
Dois anos após o lançamento da A100, a plataforma de AI da NVIDIA continua a oferecer o mais alto desempenho no MLPerf 2.0 e é a única plataforma enviada em todos os benchmarks. Nossa arquitetura Hopper de última geração promete outro grande salto nas próximas rodadas do MLPerf.
Nossa plataforma é universal para todos os modelos e frameworks em qualquer escala e oferece a fungibilidade para lidar com cada parte da carga de trabalho de AI. Ela está disponível em todos os principais fabricantes de servidores e cloud.