
O segredo para se tornar um médico especialista em qualquer área é a experiência.
Saber interpretar os sintomas, tomar a decisão certa em situações críticas e oferecer o tratamento adequado são habilidades que se desenvolvem no treinamento e com as oportunidades de aplicá-lo.
No caso dos algoritmos de AI, a experiência é adquirida por conjuntos de dados grandes, variados e de alta qualidade. Porém, geralmente é difícil ter acesso a esses conjuntos de dados, principalmente na área da saúde.
As instituições médicas precisavam recorrer a suas próprias fontes de dados, que podem ser influenciadas, por exemplo, pelas características dos pacientes, pelos aparelhos usados ou pelas especializações clínicas. Além disso, elas precisavam reunir os dados de outras instituições para coletar todas as informações necessárias.
A aprendizagem federada possibilita que os algoritmos de AI adquiram experiência a partir de vários dados localizados em lugares diferentes.
Com essa abordagem, diversas organizações podem colaborar no desenvolvimento de modelos sem precisar compartilhar dados clínicos confidenciais diretamente entre si.
Depois de várias iterações de treinamento, os modelos compartilhados são expostos a um volume muito maior de dados do que o volume interno de qualquer organização.
Como a Aprendizagem Federada Funciona
Os algoritmos de AI implementados em contextos médicos precisam, basicamente, atingir uma precisão de nível clínico. De modo geral, eles devem atender ou exceder o padrão ouro para a aplicação na qual serão usados.
Para ser considerado especialista em uma área médica específica, geralmente um profissional precisa ter 15 anos de experiência. Esse especialista provavelmente já leu cerca de 15 mil casos em um ano, o que totaliza cerca de 225 mil casos ao longo de sua carreira.
Se considerarmos doenças raras, que afetam cerca de uma em cada 2 mil pessoas, até mesmo um especialista com 30 anos de experiência terá observado apenas 100 casos de uma determinada doença.
Os algoritmos de AI precisam processar um grande número de casos para treinar modelos que cheguem ao mesmo nível de experiência de médicos especialistas, e esses exemplos precisam representar, de modo suficiente, o ambiente clínico no qual serão usados.
Porém, atualmente, o maior conjunto de dados aberto contém 100 mil casos.
Não é só o volume de dados que conta. O conjunto também precisa ser bem diversificado e incorporar exemplos de pacientes de diferentes gêneros, idades, características e exposições ambientais.
Um instituto de saúde pode ter arquivos com centenas de milhares de registros e imagens, mas geralmente essas fontes de dados não são integradas. Isso se deve principalmente ao fato de que os dados da saúde dos pacientes são privados e não podem ser usados sem o consentimento necessário deles e a aprovação ética.
A aprendizagem federada descentraliza o deep learning, eliminando a necessidade de reunir dados em um único local. Em vez disso, o modelo é treinado em várias iterações em locais diferentes.
Digamos, por exemplo, que três hospitais decidam colaborar e desenvolver um modelo para ajudar a analisar automaticamente imagens de tumores cerebrais.
Se eles adotassem uma abordagem federada cliente-servidor, o servidor centralizado armazenaria a rede neural profunda global e cada hospital participante receberia uma cópia para treiná-la em seu próprio conjunto de dados.
Depois de algumas iterações de treinamento local do modelo, os participantes enviariam uma versão atualizada do modelo de volta para o servidor centralizado e manteriam seu conjunto de dados em uma infraestrutura segura própria.
O servidor central, então, reuniria as contribuições de todos os participantes. Os parâmetros atualizados seriam compartilhados com os institutos participantes para que eles pudessem continuar o treinamento local.
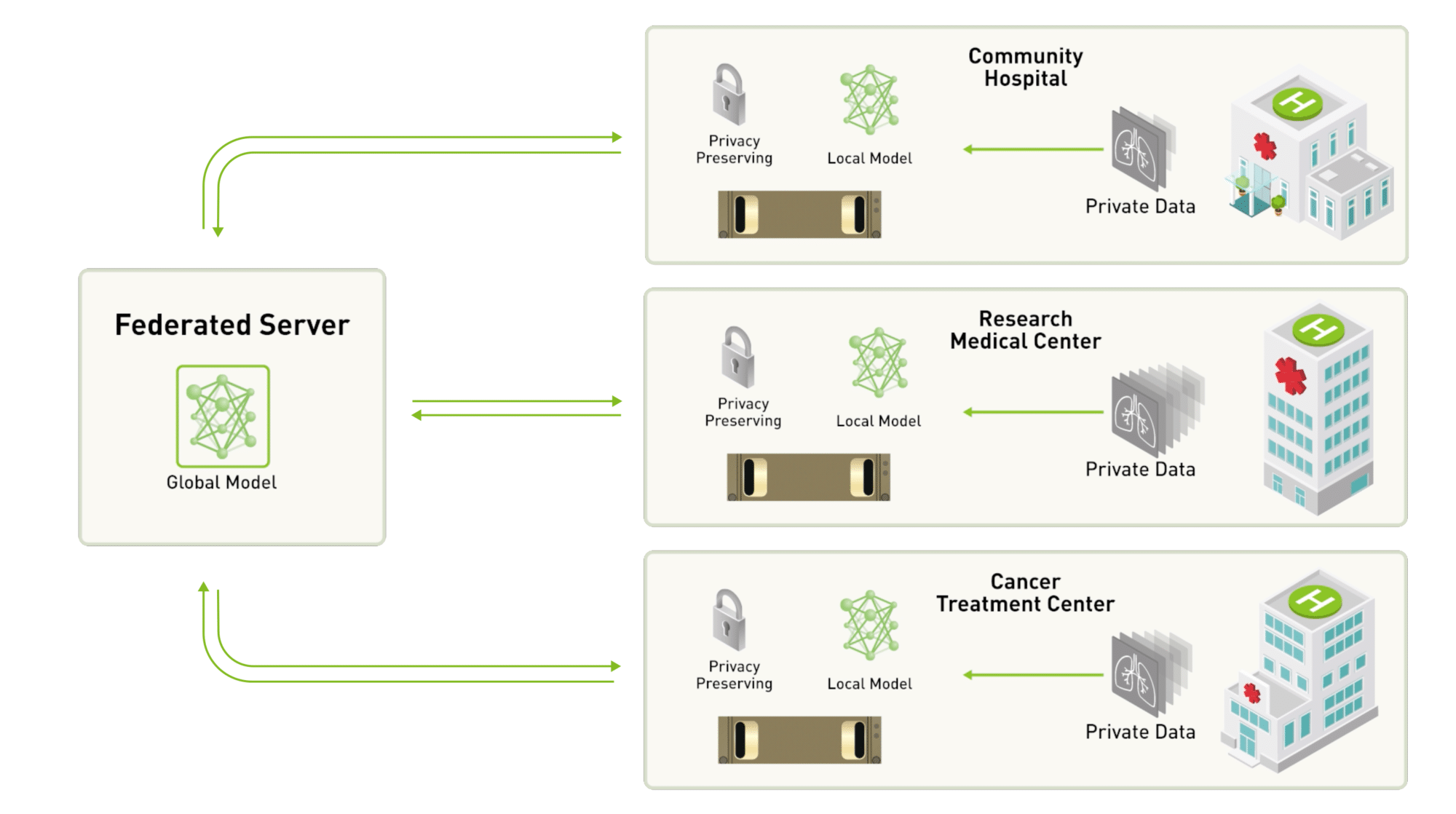
Se um dos hospitais decidisse deixar a equipe de treinamento, o treinamento do modelo não seria afetado, pois ele não depende de dados específicos. Da mesma forma, um novo hospital poderia escolher participar da iniciativa a qualquer momento.
Essa é só uma das muitas abordagens à aprendizagem federada. Em todas elas, os participantes têm acesso ao conhecimento global a partir de dados locais, ou seja, todo mundo sai ganhando.
Motivos para Adotar a Aprendizagem Federada
A aprendizagem federada ainda precisa de uma implementação cuidadosa para garantir que os dados dos pacientes sejam armazenados com segurança. Porém, ela tem o potencial de resolver alguns dos desafios encontrados em abordagens que exigem a reunião de dados clínicos confidenciais.
Na aprendizagem federada, os dados clínicos são mantidos de acordo com as medidas de segurança das instituições. Todos os participantes têm controle de seus próprios dados clínicos.
Como isso dificulta a extração de informações confidenciais dos pacientes, a aprendizagem federada abre a possibilidade de equipes criarem conjuntos de dados maiores e mais diversos para treinar seus algoritmos de AI.
A implementação de uma abordagem de aprendizagem federada também incentiva outros hospitais, instituições de saúde e centros de pesquisa a colaborar no desenvolvimento de um modelo vantajoso para todos.
Como a Aprendizagem Federada Pode Transformar a Área da Saúde
A aprendizagem federada pode revolucionar a forma como os modelos de AI são treinados, e suas vantagens também podem ser observadas no grande ecossistema da área da saúde.
Redes de hospitais maiores poderiam colaborar melhor e aproveitar o acesso a dados seguros e de várias instituições. Já hospitais comunitários e rurais menores teriam acesso a algoritmos de AI especializados.
Essa abordagem pode garantir que a AI seja usada nos locais de atendimento, possibilitando que grandes volumes de dados diversificados de organizações diferentes sejam incluídos no desenvolvimento de modelos em conformidade com a administração local dos dados clínicos.
Os médicos teriam acesso a algoritmos de AI mais eficientes baseados em dados que representam uma variedade maior de pacientes de uma área clínica específica ou de casos raros não encontrados na região onde atuam. Eles também poderiam contribuir com o treinamento contínuo dos algoritmos, dando um retorno sempre que discordassem dos resultados.
As startups da área da saúde poderiam oferecer inovações de ponta no mercado com mais rapidez graças a uma abordagem segura à aprendizagem a partir de algoritmos mais diversos.
Já as instituições de pesquisa poderiam dedicar seu trabalho a necessidades clínicas reais a partir de vários dados práticos, em vez do número limitado de conjuntos de dados abertos.
Criações da Área da Saúde para a Área da Saúde
Atualmente, há projetos de aprendizagem federada de grande escala que estão sendo iniciados para melhorar a descoberta de medicamentos e disponibilizar as vantagens da AI para o local de atendimento.
O MELLODDY, um consórcio de descoberta de medicamentos sediado no Reino Unido, visa demonstrar como as técnicas de aprendizagem federada podem oferecer o dobro de vantagem aos parceiros farmacêuticos: a capacidade de usar o maior conjunto colaborativo de dados sobre compostos de medicamentos para o treinamento da AI sem sacrificar a privacidade dos dados.
A King’s College London espera que o uso da aprendizagem federada, que faz parte do projeto London Medical Imaging and Artificial Intelligence Centre for Value-Based Healthcare, contribua para inovações na categorização de problemas neurológicos e causados por derrame cerebral, determinando as causas subjacentes do câncer e recomendando o melhor tratamento para os pacientes.
Saiba mais sobre aprendizagem federada. Conheça a ciência por trás da abordagem neste artigo.