
O paradigma da computação de consumo sempre girou em torno do conceito de dispositivo pessoal — de PCs a smartphones e tablets. Agora, a IA generativa — particularmente o OpenClaw — introduziu uma nova categoria: os computadores de agentes (agent computers). Esses dispositivos, como o supercomputador de mesa para IA NVIDIA DGX Spark ou os PCs dedicados NVIDIA RTX, são ideais para executar agentes pessoais de forma privada e gratuita.
O NVIDIA GTC, que acontece esta semana, está apresentando uma série de anúncios sobre IA agêntica, incluindo:
-
Novos modelos abertos para agentes locais, incluindo o NVIDIA Nemotron 3 Nano 4B e o Nemotron 3 Super 120B, além de otimizações para o Qwen 3.5 e o Mistral Small 4.
-
NVIDIA NemoClaw, uma stack de código aberto para o OpenClaw que otimiza a experiência em dispositivos NVIDIA, aumentando a segurança e oferecendo suporte a modelos locais.
-
Ajuste fino (fine-tuning) facilitado com o Unsloth Studio, para aprimorar ainda mais a precisão de modelos abertos em fluxos de trabalho agênticos.
Os participantes presenciais da GTC podem passar no evento “NVIDIA build-a-claw” no GTC Park, que acontece diariamente até 19 de março, das 8h às 17h. Especialistas da NVIDIA ajudarão os convidados a personalizar e implementar um assistente de IA proativo e “sempre ligado” usando o dispositivo de sua escolha. Sejam técnicos ou apenas curiosos, os participantes darão um nome ao seu agente, definirão sua personalidade e concederão acesso às ferramentas necessárias — criando um assistente pessoal acessível a partir de seu aplicativo de mensagens preferido.
Novos modelos abertos trazem qualidade de nuvem para agentes locais
A próxima geração de modelos locais — com janelas de contexto cada vez maiores — oferece a inteligência necessária para executar agentes no PC. Combinados com um contexto de usuário mais rico e ferramentas locais poderosas, esses avanços estão desbloqueando novas possibilidades em PCs com IA, especialmente no DGX Spark, com seus 128 GB de memória unificada que suporta modelos com mais de 120 bilhões de parâmetros.
O Nemotron 3 Super, lançado na semana passada, é um modelo aberto de 120 bilhões de parâmetros com 12 bilhões de parâmetros ativos, projetado para executar sistemas complexos de IA agêntica. Ele é ideal para alimentar agentes no DGX Spark ou em workstations NVIDIA RTX PRO. No PinchBench — um novo benchmark que determina o desempenho de grandes modelos de linguagem com o OpenClaw — o Nemotron 3 Super atingiu 85,6%, tornando-se o melhor modelo aberto de sua categoria.
O Mistral Small 4, um modelo aberto de 119 bilhões de parâmetros com 6 bilhões de parâmetros ativos (8 bilhões incluindo todas as camadas), unifica as capacidades dos modelos emblemáticos da Mistral. Os usuários agora têm um modelo ultraeficiente otimizado para chat geral, programação e tarefas agênticas. Ambos os modelos rodam localmente em GPUs DGX Spark e RTX PRO.
Para usuários de GeForce RTX que buscam modelos menores, o Nemotron 3 Nano 4B é o mais novo integrante da família NVIDIA Nemotron 3, proporcionando um ponto de partida compacto e capaz para construir agentes e assistentes localmente em PCs com IA RTX. O modelo é excelente para criar personas conversacionais que executam ações em jogos e aplicativos em hardwares com recursos limitados. Ele está disponível em qualquer sistema habilitado para GPU NVIDIA e combina o estado da arte em seguimento de instruções e uso excepcional de ferramentas com um consumo mínimo de VRAM.
Além disso, a NVIDIA anunciou otimizações para os modelos Qwen 3.5 da Alibaba, que demonstraram precisão excepcional (27B, 9B e 4B) e são adequados para executar agentes locais em GPUs NVIDIA. Os novos modelos suportam nativamente visão, predição de múltiplos tokens e uma ampla janela de contexto de 262.000 tokens. O modelo denso de 27 bilhões de parâmetros se destaca quando pareado com uma GPU RTX 5090.
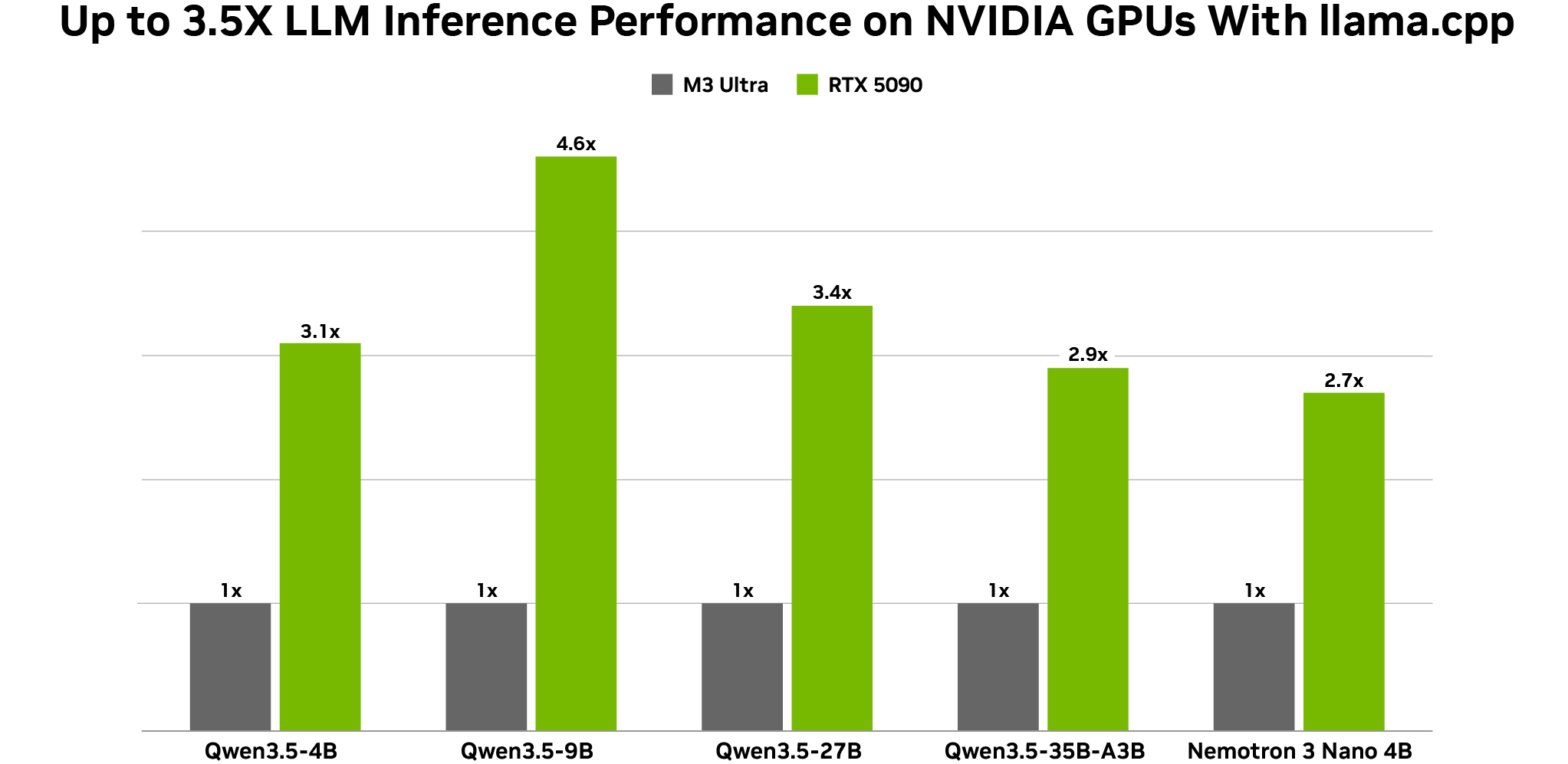
Os usuários podem testar esses modelos hoje via Ollama, LM Studio e llama.cpp, com inferência acelerada por GPUs RTX e DGX Spark.
IA criativa mais rápida com os modelos otimizados para RTX
O LTX 2.3, modelo de áudio e vídeo de última geração da Lightricks lançado no início deste mês, agora possui suporte para modelos destilados NVFP4 e FP8, acelerando o desempenho em 2,1x.
Além disso, o FLUX.2 Klein 9B da Black Forest Lab recebeu uma atualização na semana passada, acelerando a edição de imagens em até 2x. A NVIDIA colaborou com a Black Forest Labs para lançar uma versão FP8, otimizada para a máxima performance e consumo ideal de memória em GPUs RTX.
NVIDIA NemoClaw — Otimizações NVIDIA para OpenClaw
Desenvolvedores e entusiastas de IA estão adquirindo supercomputadores DGX Spark ou montando PCs RTX dedicados para executar agentes de IA autônomos, como o OpenClaw, que extraem contexto de arquivos pessoais, aplicativos e fluxos de trabalho para automatizar tarefas diárias. No entanto, à medida que a adoção de sistemas agênticos cresce, aumentam também as preocupações com custos de tokens, segurança e privacidade.
Para ajudar a sanar essas questões, a NVIDIA introduziu esta semana o NemoClaw, uma stack de código aberto que implementa otimizações para o OpenClaw em dispositivos NVIDIA. Os primeiros recursos disponíveis no NemoClaw são os modelos abertos NVIDIA Nemotron e o runtime NVIDIA OpenShell. Os modelos locais Nemotron permitem a inferência local, o que garante maior privacidade e custo zero de tokens. O OpenShell é o runtime projetado para executar os “claws” com mais segurança.
Ajuste fino facilitado com o Unsloth Studio
Com o salto tecnológico dos modelos abertos, uma forma de melhorar ainda mais a precisão é o ajuste fino (fine-tuning), que permite personalizar um modelo para dados e casos de uso específicos. Essa técnica normalmente exige profundo conhecimento técnico e codificação complexa. A Unsloth, biblioteca líder de código aberto para ajuste e alinhamento de modelos, lançou hoje o Unsloth Studio, uma interface web fácil de usar que simplifica esse processo.
O Unsloth Studio oferece suporte a mais de 500 modelos de IA. A interface simplifica o treinamento: os usuários podem apenas arrastar seu conjunto de dados, clicar na tela baseada em gráficos para gerar dados sintéticos de alta qualidade e iniciar o ajuste fino. O sistema suporta QLoRA, LoRA e ajuste fino completo. Durante o processo, é possível monitorar o progresso visualmente e, ao final, exportar o modelo para o framework de preferência.
A nova interface utiliza a biblioteca Unsloth, que entrega um treinamento até 2x mais rápido com economia de até 70% de VRAM. Isso significa que novos usuários podem extrair o máximo de suas GPUs NVIDIA RTX e DGX Spark de imediato.
#ICYMI: Destaques do GTC 2026
-
✨ Guia de geração de vídeo com IA RTX: Mostra como usar fluxos de texto para imagem no ComfyUI para criar vídeos em 4K usando tecnologia RTX em GPUs locais. Use a hashtag #AIonRTX.
-
💿 NVIDIA AI for Media: Conjunto de SDKs que traz efeitos de IA de nível profissional (Broadcast) para live media e videoconferência. A atualização de hoje traz sincronia labial mais precisa, detecção de múltiplos falantes e upscaling 4K mais rápido em GPUs RTX Séries 40 e 50.
-
💻 NVIDIA DLSS 5: Chega no segundo semestre, trazendo um salto em fidelidade visual para jogos com iluminação e materiais fotorrealistas gerados por IA.
-
🤖 Maxon Redshift 2026.4: Introduz visualização em tempo real com DLSS, permitindo que arquitetos naveguem por projetos com velocidade e qualidade interativas.
-
🪟 Reincubate Camo: Adicionou suporte a Windows ML no NVIDIA TensorRT para o recurso AI Autotune, melhorando significativamente a performance em GPUs RTX.