
Turbinando o Desempenho do Meta Llama 3 com NVIDIA TensorRT-LLM e Servidor de Inferência NVIDIA Triton
Temos o prazer de anunciar o suporte para a família de modelos Meta Llama 3 no NVIDIA TensorRT-LLM, acelerando e otimizando seu desempenho de inferência LLM. Você pode experimentar imediatamente… Leia o artigo
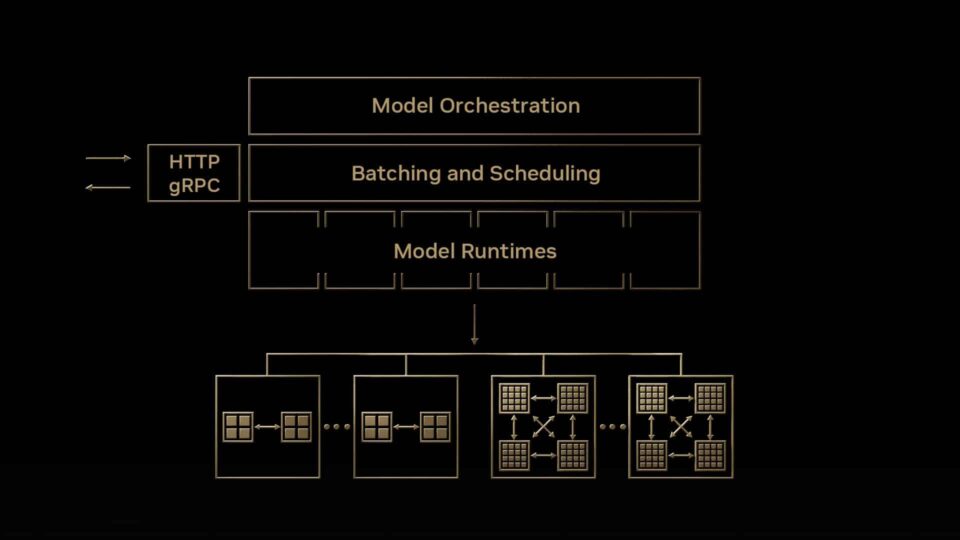
Resolvendo Desafios de Inferência de IA com NVIDIA Triton
A implantação de modelos de IA na produção para atender aos requisitos de desempenho e escalabilidade da aplicação orientada por IA mantendo os custos de infraestrutura baixos, é uma tarefa… Leia o artigo