A implantação de modelos de IA na produção para atender aos requisitos de desempenho e escalabilidade da aplicação orientada por IA mantendo os custos de infraestrutura baixos, é uma tarefa assustadora.
Esta postagem fornece uma visão geral dos desafios de inferência de IA que geralmente ocorrem ao implantar modelos na produção, além de como o Servidor de Inferência NVIDIA Triton está sendo usado hoje em vários setores para resolver esses casos.
Também examinamos alguns dos recursos, ferramentas e serviços adicionados recentemente no Triton que simplificam a implantação de modelos de IA na produção, com desempenho máximo e economia de custos.
Desafios a Serem Considerados ao Implantar a Inferência de IA
A inferência de IA é a fase de produção da execução de modelos de IA para fazer previsões. A inferência é complexa, mas entender os fatores que afetam a velocidade e o desempenho do sua aplicação ajudará você a fornecer IA rápida e escalável na produção.
Desafios para Desenvolvedores e Engenheiros de ML
- Muitos tipos de modelos: modelos de IA, machine learning e deep learning (baseado em rede neural) com arquiteturas e tamanhos diferentes.
- Diferentes tipos de consulta de inferência: lote off-line em tempo real, streaming de vídeo e áudio e pipelines de modelo tornam desafiador o cumprimento dos acordos de nível de serviço da aplicação.
- Modelos em constante evolução: os modelos em produção devem ser atualizados continuamente com base em novos dados e algoritmos, sem interrupções nos negócios.
Desafios para Profissionais de MLOps, TI e DevOps
- Vários frameworks de modelo: existem diferentes frameworks de treinamento e inferência, como TensorFlow, PyTorch, XGBoost, TensorRT, ONNX ou simplesmente Python. A implantação e manutenção de cada um desses frameworks em produção para aplicações pode ser cara.
- Processadores diversos: Os modelos podem ser executados em uma CPU ou GPU. Ter uma pilha de software separada para cada plataforma de processador leva a uma complexidade operacional desnecessária.
- Diversas plataformas de implantação: os modelos são implantados em nuvens públicas, data centers locais, no edge e em dispositivos incorporados em bare metal, virtualizados ou em uma plataforma de ML de terceiros. Soluções díspares ou soluções abaixo do ideal para se adequar à plataforma fornecida levam a um ROI insatisfatório. Isso pode incluir lançamentos mais lentos, baixo desempenho da aplicação ou uso de mais recursos.
Uma combinação desses fatores torna desafiador implantar a inferência de IA na produção com o desempenho e a eficiência de custo desejados.
Novos Casos de Uso de Inferência de IA Usando NVIDIA Triton
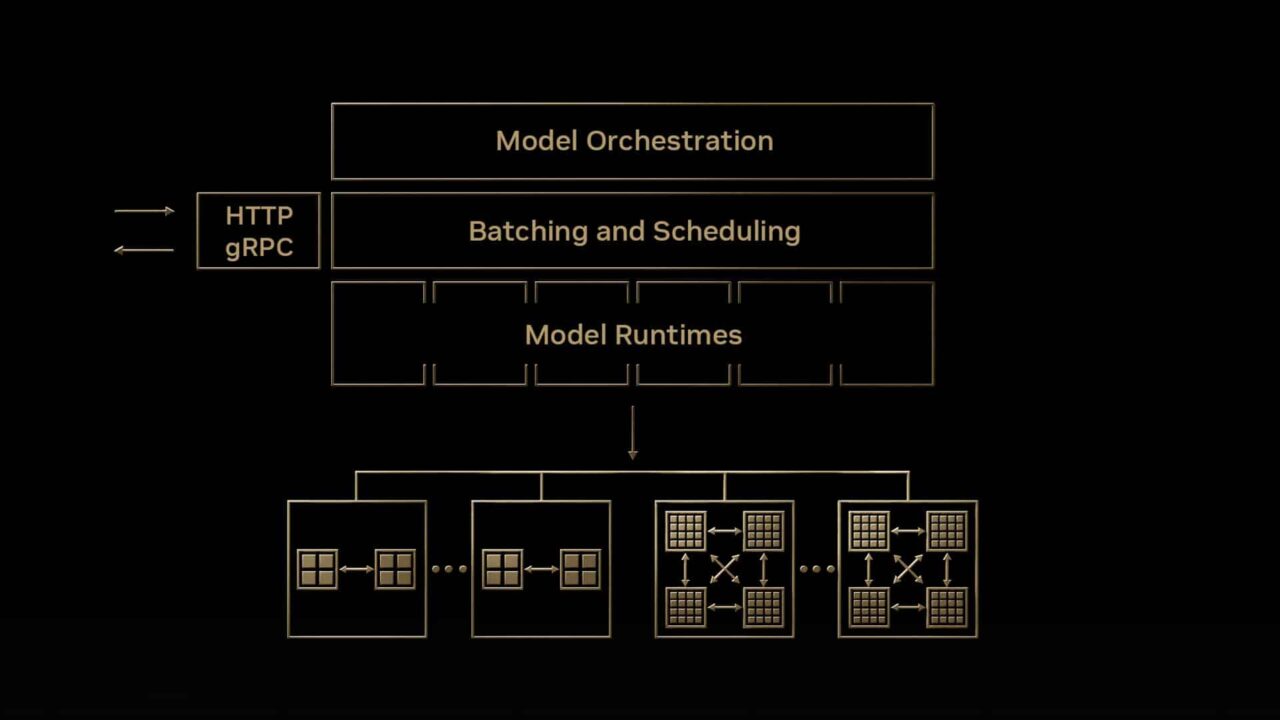
O Servidor de Inferência NVIDIA Triton (Triton) é um software de serviço de inferência de código aberto que oferece suporte a todas os principais frameworks de modelo (TensorFlow, PyTorch, TensorRT, XGBoost, ONNX, OpenVINO, Python e outros). O Triton pode ser usado para executar modelos em CPUs x86 e Arm, GPUs NVIDIA e AWS Inferentia. Ele aborda as complexidades discutidas anteriormente por meio de recursos padrão.
O Triton é usado por milhares de empresas em todos os setores em todo o mundo. Veja como o Triton ajuda a resolver os desafios de inferência de IA para alguns clientes.
NIO Autonomous Driving
A NIO usa o Triton para executar seus modelos de serviços online na nuvem e no data center. Esses modelos processam dados de veículos autônomos. A NIO usou o recurso de conjunto de modelos Triton para mover suas funções de pré e pós-processamento da aplicação cliente para o Servidor de Inferência Triton. O pré-processamento foi acelerado em 5 vezes, aumentando sua taxa de transferência de inferência geral e permitindo que eles processassem mais dados dos veículos de maneira econômica.
GE Healthcare
A GE Healthcare usa o Triton em sua plataforma Edison para padronizar o serviço de inferência em diferentes frameworks (TensorFlow, PyTorch, ONNX e TensorRT) para modelos internos. Os modelos são implantados em uma variedade de sistemas de hardware, desde servidores integrados (por exemplo, um sistema de raio-x) até servidores locais.
Wealthsimple
A empresa de gestão de investimentos online usa Triton em CPUs para executar sua detecção de fraude e outros modelos fintech. A Triton os ajudou a consolidar seus diferentes softwares de serviço em aplicações em um único padrão para vários frameworks.
Tencent
A Tencent usa o Triton em sua plataforma de ML centralizada para inferência unificada para várias aplicações de negócios. No total, o Triton os ajuda a processar 1,5 milhão de consultas por dia. A Tencent alcançou um baixo custo de inferência por meio de lotes dinâmicos do Triton e recursos de execução de modelos simultâneos.
Alibaba Intelligent Connectivity
A Alibaba Intelligent Connectivity está desenvolvendo sistemas de IA para suas aplicações de alto-falantes inteligentes. Eles usam o Triton no data center para executar modelos que geram streaming de texto em fala para o alto-falante inteligente. O Triton forneceu a menor latência do primeiro pacote necessária para uma boa experiência de áudio.
Yahoo Japão
O Yahoo Japão usa Triton em CPUs no data center para executar modelos para encontrar locais semelhantes para a funcionalidade de “pesquisa pontual” na aplicaçõa Yahoo Browser. O Triton é usado para executar o pipeline completo de pesquisa de imagens e também é integrado à plataforma ML centralizada para oferecer suporte a vários frameworks em CPUs e GPUs.
Airtel
O segundo maior provedor sem fio da Índia, a Airtel usa Triton para modelos de reconhecimento automático de fala (ASR) para aplicações de contact center para melhorar a experiência do cliente. O Triton os ajudou a atualizar para um modelo ASR mais preciso e ainda obter um aumento de taxa de transferência de 2 vezes em GPUs em comparação com a solução de serviço anterior.
Como o Servidor de Inferência Triton Aborda os Desafios de Inferência de IA
De fintech a direção autônoma, todas as aplicações podem se beneficiar da funcionalidade pronta para implantar modelos na produção com facilidade.
Esta seção discute alguns novos recursos, ferramentas e serviços importantes que o Triton fornece prontos para uso que podem ser aplicados para implantar, executar e dimensionar modelos na produção.
Orquestração de Modelo com Novo Serviço de Gerenciamento
O Triton traz um novo serviço de orquestração de modelos para inferência eficiente de vários modelos. Esta aplicação de software, atualmente em acesso antecipado, ajuda a simplificar a implantação de instâncias Triton no Kubernetes com muitos modelos de maneira eficiente em termos de recursos. Algumas das principais características deste serviço incluem o seguinte:
- Carregar modelos sob demanda e descarregando modelos quando não estiverem em uso.
- Alocação eficiente de recursos de GPU colocando vários modelos em um único servidor de GPU sempre que possível
- Gerenciar requisitos de recursos personalizados para modelos individuais e grupos de modelos
Para uma breve demonstração desse serviço, assista Take Your AI Inference to the Next Level. O recurso de orquestração de modelo está em acesso antecipado privado (EA). Se você estiver interessado em experimentá-lo, inscreva-se agora.
Inferência de Grande Modelo de Linguagem
Na área de processamento de linguagem natural (NLP), o tamanho dos modelos está crescendo exponencialmente. Grandes modelos baseados em transformadores com centenas de bilhões de parâmetros podem resolver muitas tarefas de NLP, como resumo de texto, geração de código, tradução ou título de relações públicas e geração de anúncios.
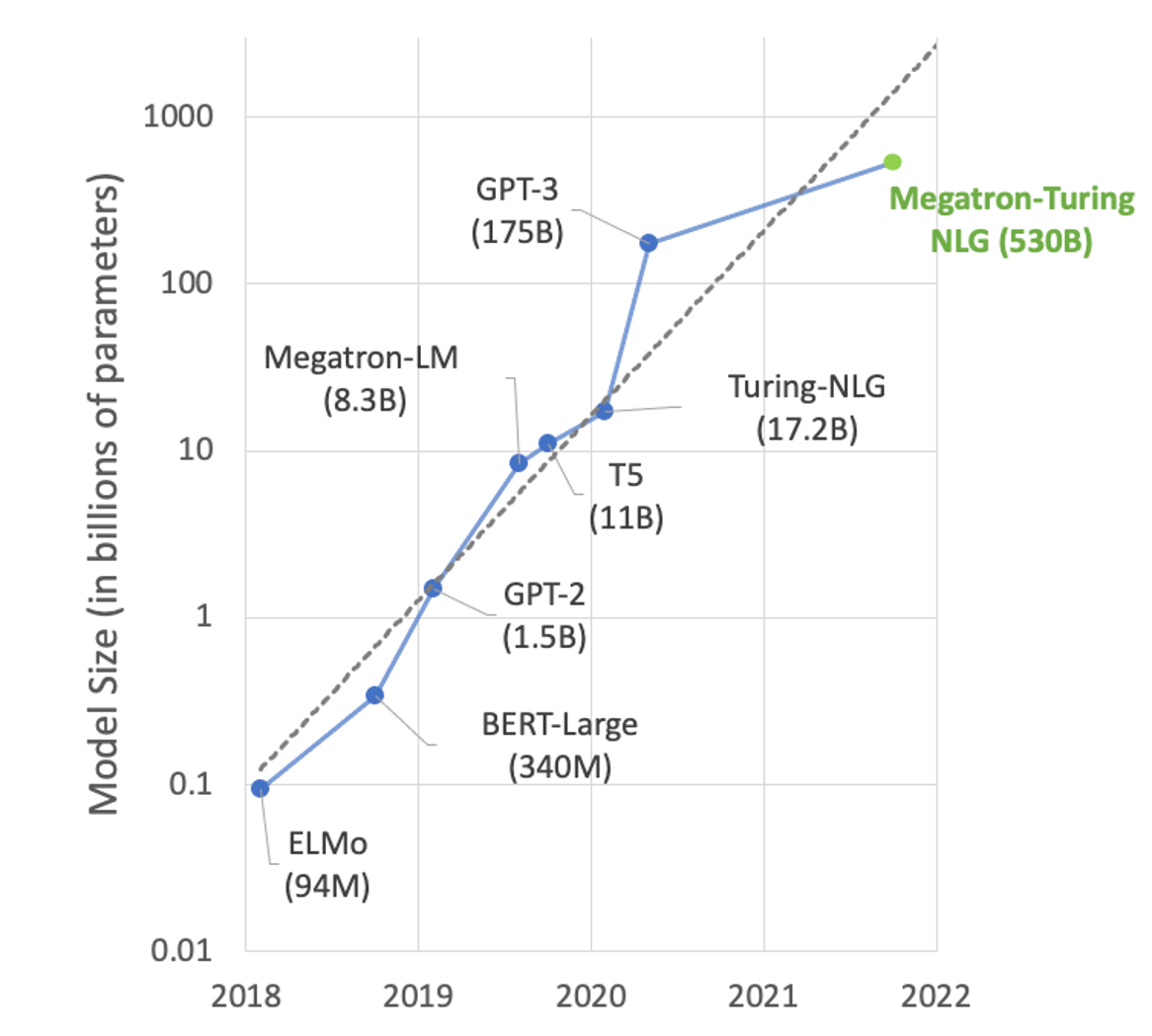
Mas esses modelos são tão grandes que não cabem em uma única GPU. Por exemplo, Turing-NLG com parâmetros 17.2B precisa de pelo menos 34 GB de memória para armazenar pesos e bias em FP16 e GPT-3 com parâmetros 175B precisa de pelo menos 350 GB. Para usá-los para inferência, você precisa de execução multi-GPU e cada vez mais multi-nó para atender ao modelo.
O Servidor de Inferência Triton tem um back-end chamado FasterTransformer que traz inferência multi-nó multi-GPU para grandes modelos de transformadores como GPT, T5 e outros. O grande modelo de linguagem é convertido para o formato FasterTransformer com otimizações e recursos de inferência distribuída e, em seguida, é executado usando o Servidor de Inferência Triton em GPUs e nós.
A figura a seguir mostra a aceleração observada com o Triton para executar o modelo GPT-J (6B) em uma CPU ou com uma e com duas GPUs A100.
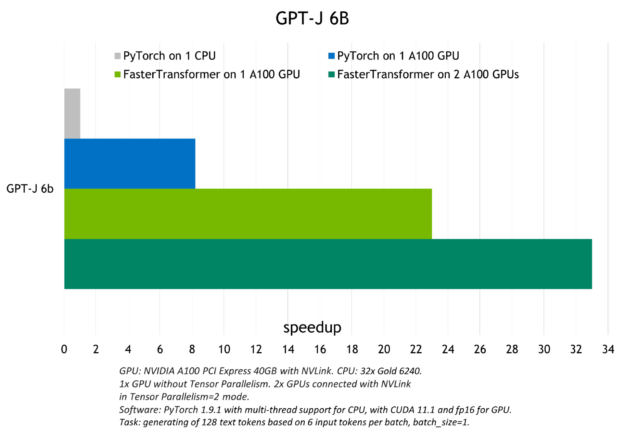
Para obter mais informações sobre a inferência de modelo de linguagem grande com o back-end Triton FasterTransformer, consulte Accelerated Inference for Large Transformer Models Using NVIDIA Triton Inference Server e Deploying GPT-J and T5 with NVIDIA Triton Inference Server.
Inferência de Modelos Baseados em Árvore
O Triton pode ser usado para implantar e executar modelos baseados em árvore de frameworks como XGBoost, LightGBM e scikit-learn RandomForest em CPUs e GPUs com capacidade de explicação usando valores SHAP. Ele consegue isso usando o back-end Forest Inference Library (FIL) que foi introduzido no ano passado.
A vantagem de usar Triton para inferência de modelo baseado em árvore é melhor desempenho e padronização de inferência em modelos de machine learning e deep learning. É especialmente útil para aplicações em tempo real, como detecção de fraudes, onde modelos maiores podem ser usados facilmente para melhor precisão.
Para obter mais informações sobre a implantação de um modelo baseado em árvore com Triton, consulte Real-time Serving for XGBoost, Scikit-Learn RandomForest, LightGBM, and More. A postagem inclui um caderno de detecção de fraudes.
Experimente este laboratório NVIDIA Launchpad para implantar um modelo de detecção de fraude XGBoost com Triton.
Configuração de Modelo Ideal com Analisador de Modelo
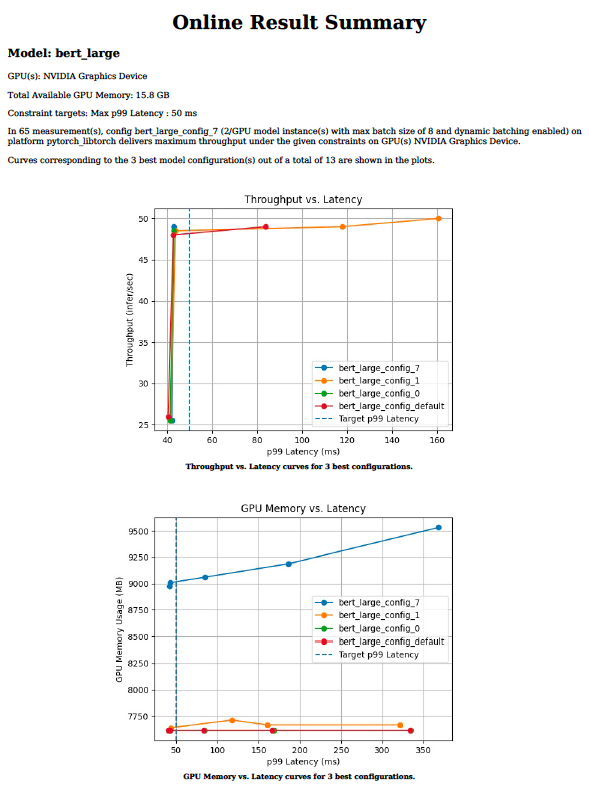
O serviço de inferência eficiente requer a escolha de valores ideais para parâmetros como tamanho do lote, simultaneidade do modelo ou precisão para um determinado processador de destino. Esses valores ditam os requisitos de taxa de transferência, latência e memória. Pode levar semanas para tentar centenas de combinações manualmente em uma gama de valores para cada parâmetro.
A ferramenta do analisador de modelo Triton reduz o tempo que leva para encontrar os parâmetros de configuração ideais, de semanas para dias ou mesmo horas. Ele faz isso executando centenas de simulações de inferência com diferentes valores de tamanho de lote e simultaneidade de modelo para um determinado processador de destino offline. No final, ele fornece gráficos como a Figura 3 que facilitam a escolha da configuração de implantação ideal. Para obter mais informações sobre a ferramenta do analisador de modelo e como usá-la para sua implantação de inferência, consulte Identifying the Best AI Model Serving Configurations at Scale with NVIDIA Triton Model Analyzer.
Modelar Pipelines com Scripts de Lógica de Negócios
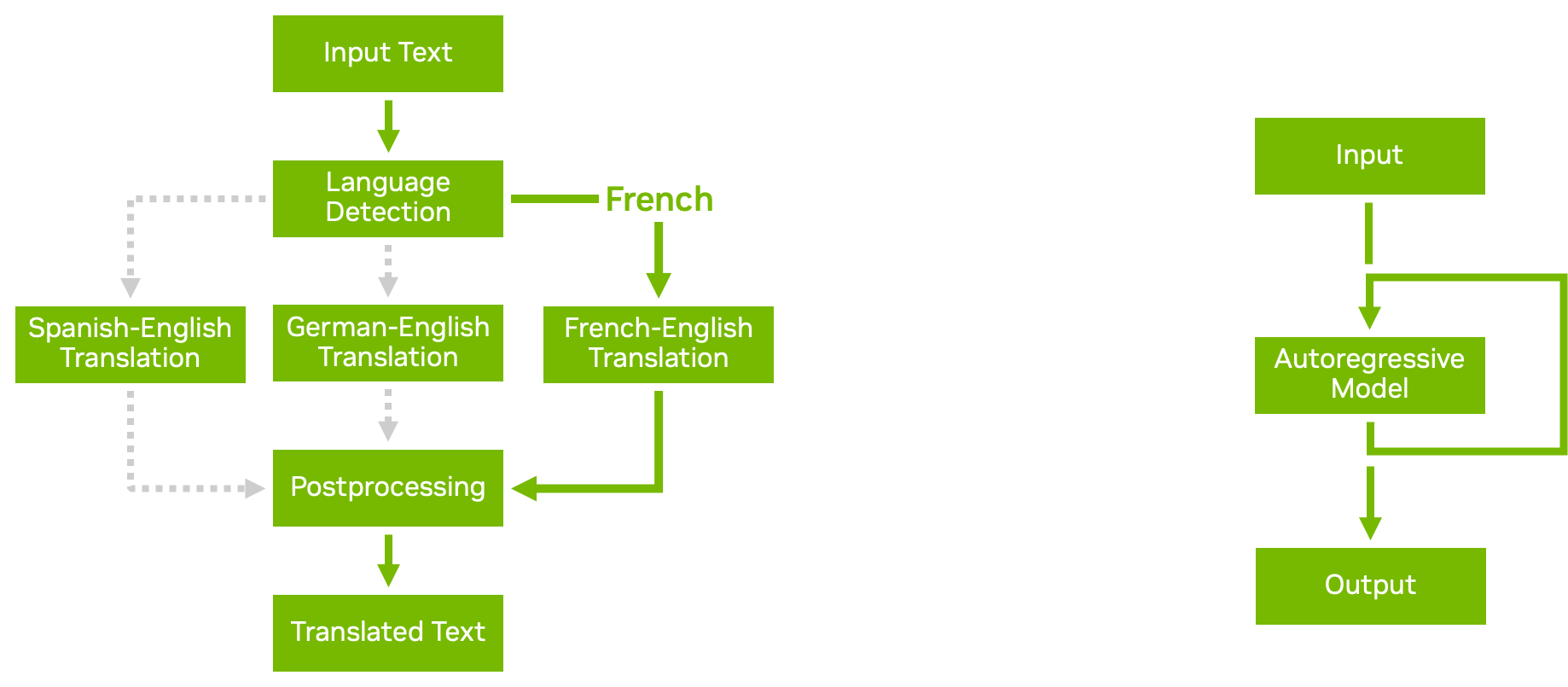
Com o recurso de conjunto de modelos no Triton, você pode criar pipelines e conjuntos de modelos complexos com vários modelos e etapas de pré e pós-processamento. O script de lógica de negócios permite adicionar condicionais, loops e reordenar etapas no pipeline.
Usando os back-ends Python ou C++, você pode definir um script personalizado que pode chamar qualquer outro modelo sendo atendido pelo Triton com base nas condições que você escolher. O Triton passa os dados com eficiência para o modelo recém-chamado, evitando cópias desnecessárias da memória sempre que possível. Em seguida, o resultado é passado de volta para seu script personalizado, a partir do qual você pode continuar o processamento ou retornar o resultado.
A figura acima mostra dois exemplos de scripts de lógica de negócios:
- A execução condicional ajuda a usar os recursos com mais eficiência, evitando a execução de modelos desnecessários.
- Os modelos autorregressivos, como a decodificação do transformador, exigem que a saída de um modelo seja realimentada repetidamente até que uma determinada condição seja alcançada. Loops em scripts de lógica de negócios permitem que você faça isso.
Para obter mais informações, consulte Business Logic Scripting.
Geração Automática de Configuração de Modelo
O Triton pode gerar automaticamente arquivos de configuração para seus modelos para implantação mais rápida. Para os modelos TensorRT, TensorFlow e ONNX, o Triton gera as configurações mínimas necessárias para executar seu modelo por padrão quando não detecta um arquivo de configuração no repositório.
O Triton também pode detectar se o seu modelo suporta inferência em lote. Ele define max_batch_size para um valor padrão configurável.
Você também pode incluir comandos em seus próprios back-ends Python e C++ personalizados para gerar arquivos de configuração de modelo automaticamente com base no conteúdo do script. Esses recursos são especialmente úteis quando você tem muitos modelos para atender, pois evita a etapa de criar manualmente os arquivos de configuração. Para obter mais informações, consulte Auto-Generated Model Configuration.
Processamento de Entrada Desacoplado
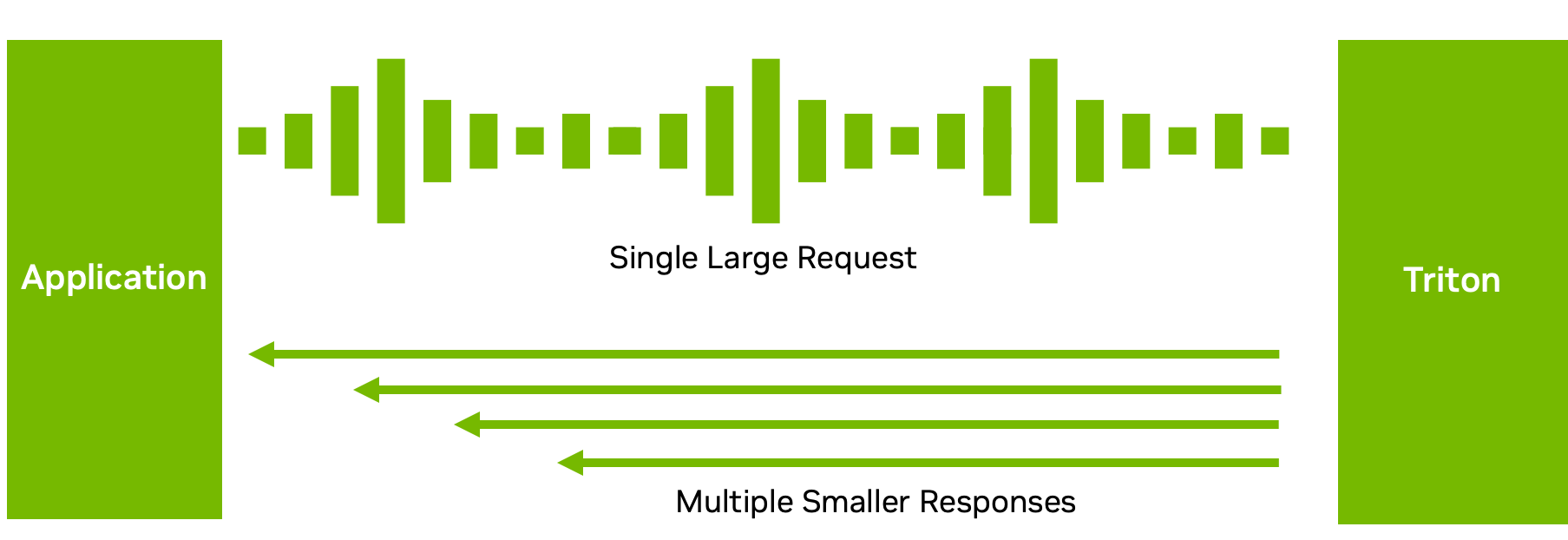
Embora muitas configurações de inferência exijam uma correspondência individual entre solicitações e respostas de inferência, esse nem sempre é o fluxo de dados ideal.
Por exemplo, com modelos ASR, enviar o áudio completo e esperar que o modelo finalize a execução pode não resultar em uma boa experiência do usuário. A espera pode ser longa. Em vez disso, o Triton pode enviar de volta o texto transcrito em vários blocos curtos (figura acima), reduzindo a latência e o tempo para a primeira resposta.
Com o processamento de modelo desacoplado no back-end C++ ou Python, você pode enviar várias respostas para uma única solicitação. Claro, você também pode fazer o oposto: enviar várias pequenas solicitações em blocos e obter uma grande resposta. Esse recurso fornece flexibilidade na forma como você processa e envia suas respostas de inferência. Para obter mais informações, consulte Decoupled Models.
Para obter mais informações sobre os recursos adicionados recentemente, consulte as notas de versão do NVIDIA Triton.
Comece com a Implantação Escalonável do Modelo de IA
Você pode implantar, executar e dimensionar modelos de IA com o Triton para mitigar efetivamente os desafios de inferência de IA que você pode ter com vários frameworks, uma infraestrutura diversificada, modelos de linguagem grandes, configurações ideais de modelo e muito mais.
O Servidor de Inferência Triton é de código aberto e oferece suporte a todos os principais frameworks de modelo, como TensorFlow, PyTorch, TensorRT, XGBoost, ONNX, OpenVINO, Python e até frameworks personalizados em sistemas de GPU e CPU. Explore mais maneiras de integrar o Triton a qualquer aplicação, ferramenta de implantação e plataforma, na nuvem, no local e no edge.
Para obter mais informações, consulte os seguintes recursos:
- Comece com o NVIDIA Triton e acesse uma variedade de recursos iniciantes a avançados.
- Descubra os recursos de que você precisa em uma plataforma de inferência ao criar uma aplicação de streaming de dados contínuo ou em tempo real, Implantação de Modelo de IA Rápida e Escalável com o Servidor de Inferência NVIDIA Triton.
- Descubra por que a infraestrutura de computação tradicional não é mais suficiente para suportar IA em grande escala. O segredo para uma computação rápida e perspicaz acelerada por IA-GPU.
- Procurando por um laboratório de habilidades práticas? Implante um chatbot de suporte de IA ou treine seu próprio modelo de IA para classificação de imagens de produtos online no NVIDIA LaunchPad.