
Um dos principais desafios para os sistemas de geração aumentada por recuperação (RAG) é lidar com consultas de usuários que carecem de clareza explícita ou carregam intenção implícita. Os usuários costumam formular perguntas de forma imprecisa. Por exemplo, considere a consulta do usuário: “Fale-me sobre a atualização mais recente no treinamento do modelo NVIDIA NeMo”. É possível que o usuário esteja implicitamente interessado em avanços nos recursos de personalização de grandes modelos de linguagem (LLM) do NeMo, em vez de seus modelos de fala. No entanto, essa preferência não é expressa explicitamente, o que pode levar a resultados abaixo do ideal.
Superar essas limitações e desbloquear o verdadeiro potencial do RAG requer ir além das técnicas básicas. Esta postagem apresenta os recursos de raciocínio de IA dos LLMs NVIDIA Nemotron que aprimoram significativamente os pipelines RAG. Analisamos um exemplo da vida real de como aplicamos estratégias avançadas, como análise e reescrita de consultas, para refinar os recursos de pesquisa de um mecanismo de consulta.
O que é reescrita de consulta no RAG?
A reescrita de consulta no RAG é uma etapa crucial que transforma o prompt inicial de um usuário em uma consulta mais otimizada para melhorar a recuperação de informações. Esse processo é vital para aumentar o desempenho do RAG porque preenche a lacuna semântica entre como um usuário faz uma pergunta e como as informações são estruturadas na base de conhecimento. Ao refinar a consulta, o sistema pode superar problemas como imprecisão ou complexidade excessiva, levando à recuperação de documentos mais precisos e relevantes. Esse contexto de alta qualidade permite diretamente que o modelo de linguagem gere respostas mais precisas, abrangentes e baseadas em fatos.
Várias técnicas surgiram para uma reescrita de consulta eficaz, particularmente aproveitando LLMs:
- Q2E (Query2Expand): gera consultas ou expansões semanticamente equivalentes que abrangem diferentes maneiras pelas quais as informações do usuário podem ser expressas, aumentando a chance de recuperar documentos relevantes.
- Q2D (Query2Doc): constrói um pseudodocumento da consulta original, refletindo o estilo e o conteúdo das passagens de recuperação. Isso melhora o alinhamento com a forma como as informações são armazenadas no corpus.
- Reescrita de consulta CoT (cadeia de pensamento): esse método usa um prompt específico instruindo o LLM a fornecer uma lógica passo a passo, dividindo a consulta original e elaborando o contexto relacionado antes de fornecer a consulta expandida. Ao contrário de reescrever a consulta diretamente, os prompts do método geram explicações lógicas detalhadas que tendem a incluir um amplo conjunto de palavras-chave relevantes naturalmente incorporadas ao raciocínio.
Ao empregar essas técnicas, os sistemas RAG podem reestruturar perguntas mal formadas, introduzir palavras-chave vitais e ancorar as consultas do usuário mais de perto na semântica do corpus, elevando substancialmente a qualidade da pesquisa e da resposta.
Para incorporar a técnica de reescrita de consulta no RAG, o prompt precisaria ser adaptado especificamente aos casos de uso do RAG. Confira alguns exemplos de prompts para cada método:
Prompt Q2E
Your task is to brainstorm a set of useful search terms and related key phrases that could help locate information
about the following question. Focus on capturing alternate expressions, synonyms, and specific entities or events
mentioned in the query.
Original Question: {query}
Related Search Keywords:
Prompt Q2D
Imagine you are composing a short informative article that directly addresses a given question. Write a detailed passage
that would help someone fully understand the subject or find an answer to the query.
Query: {query}
Passage:
Prompt de reescrita de consulta CoT
Please carefully consider the following question. First, break down what the question is asking and think through any
relevant facts, possible interpretations, or required background knowledge. Then, list out important words, concepts, or
phrases that emerge from your reasoning process, which could help retrieve detailed answers.
Question: {query}
Your step-by-step reasoning and expansion terms:
Como os modelos NVIDIA Nemotron avançam o RAG?
A família de modelos multimodais e de raciocínio NVIDIA Nemotron se baseia na família Meta Llama para fornecer um conjunto de LLMs otimizados para eficiência, desempenho e aplicativos avançados, como RAG e sistemas agenciais. Os modelos Nemotron são uma família aberta de modelos avançados de IA projetados para fornecer fortes recursos de raciocínio, alta eficiência e implantação flexível para agentes de IA corporativos. Disponíveis nos tamanhos Nano, Super e Ultra, esses modelos combinam a arquitetura Meta Llama com as extensas técnicas pós-treinamento da NVIDIA para obter a máxima precisão nos benchmarks do setor.
Entre a família de modelos Nemotron, descobrimos que o modelo Llama 3.3 Nemotron Super 49B v1 se adapta mais ao caso de uso para impulsionar avanços no RAG, particularmente considerando a latência de inferência e a capacidade de raciocínio apropriada. Os resultados no conjunto de dados de perguntas naturais (NQ) mostram claramente que a reescrita de consultas melhora significativamente a precisão da recuperação. Accuracy@K indica a fração de perguntas em que uma resposta correta é encontrada nas passagens recuperadas do top K.

Arquitetura para pipeline RAG com Llama Nemotron
A Figura 1 mostra a arquitetura de um processo RAG aprimorado com o Llama 3.3 Nemotron Super 49B v1.
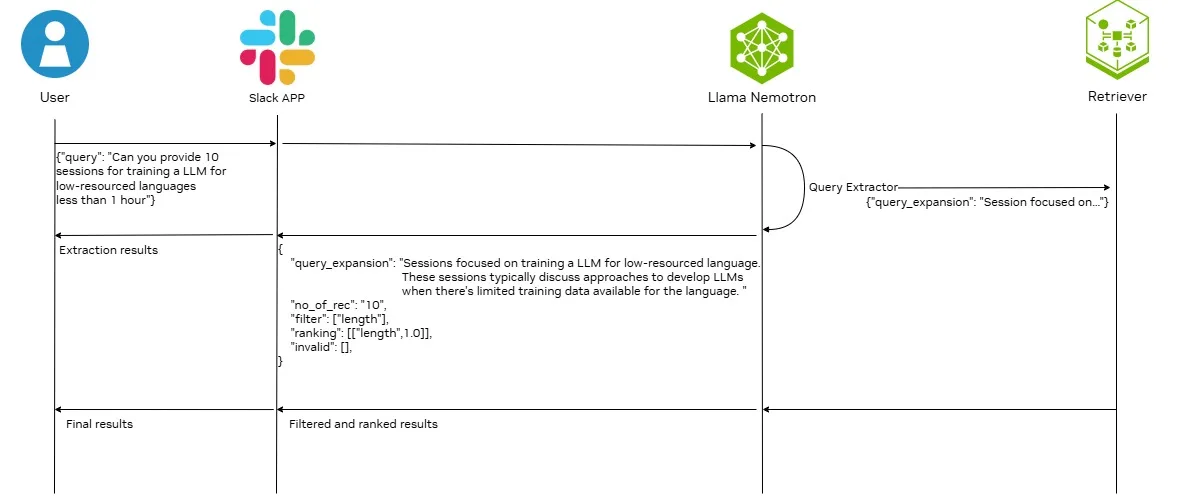
Na arquitetura, o modelo Llama Nemotron é usado como um extrator de consulta com as seguintes funções:
- Analise a consulta do usuário para extrair a consulta principal. Esta etapa refina a consulta do usuário para excluir frases desnecessárias e que distraem, que provavelmente afetarão negativamente o resultado da recuperação.
- Analise a consulta do usuário para extrair o critério de filtragem ou classificação disponível. O critério de filtragem extraído pode ser usado para pesquisa de recuperação híbrida ou como entrada para um modelo de reclassificação para executar filtragem qualitativa. O critério de classificação extraído permite que os usuários definam outros critérios de classificação, exceto para relevância.
- Expanda a consulta principal adicionando informações contextuais relacionadas. Esse processo pode incluir técnicas como gerar paráfrases, dividir consultas complexas em subperguntas ou anexar contexto de plano de fundo. Expandir as consultas dessa maneira é benéfico, pois melhora a precisão da recuperação, especialmente quando as consultas do usuário são ambíguas ou incompletas.
- Passe a consulta expandida para o NVIDIA NeMo Retriever para ingestão, incorporação e reclassificação aceleradas.
O Slack é integrado ao back-end com o Slack para permitir a integração com aplicativos adicionais e eliminar a necessidade de desenvolver e manter um front-end tradicional. Vários componentes principais garantem uma comunicação perfeita entre os usuários do Slack e o back-end, incluindo:
- Tratamento de eventos em tempo real: SocketModeHandler permite o tratamento de eventos em tempo real, garantindo uma comunicação perfeita entre os usuários do Slack e o back-end.
- Configuração modular do bot: para carregar componentes, conectar-se à lógica principal e configurar manipuladores de eventos e logs.
- Experiência do usuário interativa organizada: para aprimorar a experiência do usuário postando todas as respostas como mensagens encadeadas para minimizar a desordem e manter as conversas organizadas.
Para os fins desta postagem, a arquitetura mostrada na Figura 1 é aplicada para ajudar a melhorar os resultados da pesquisa para sessões NVIDIA GTC 2025. A reescrita de consulta garante que a pesquisa de similaridade semântica recupere um conjunto de sessões mais focado. Isso é explicado com exemplos na próxima seção.
Como refinar um mecanismo de consulta de pesquisa com recursos de raciocínio
Um dos principais desafios que destaca a necessidade de reescrita de consulta em um workflow RAG é a lacuna semântica entre a linguagem dos usuários e o vocabulário do conteúdo. Por exemplo, considere a consulta do usuário, “Sessões para treinar um LLM para linguagem com poucos recursos”. O desafio nesta consulta é a frase “linguagem com poucos recursos”.
Com essa consulta, o usuário está procurando sessões sobre sessões relacionadas ao treinamento de LLMs multilíngues ou IA soberana. Embora várias sessões do GTC 2025 discutam esse tópico, nenhuma delas usa a frase-chave “linguagem com poucos recursos”. Em vez disso, frases mais comuns incluem “multilíngue”, “não inglês”, “IA soberana” ou idiomas específicos, como “coreano” ou “francês”. Por esse motivo, usar a consulta original para recuperar e classificar as sessões relevantes provavelmente não produzirá um resultado satisfatório.
Para resolver esse problema, adotamos as técnicas Q2E para reescrever as consultas. Nesse caso de usuário, a reescrita de consulta Q2D e COT não é apropriada porque a consulta do usuário será específica do domínio e o LLM de uso geral não tem conhecimento sobre a criação de pseudodocumentos ou contexto para a consulta do usuário, levando a uma grande chance de alucinação do LLM. Um exemplo de prompt de Q2E para este caso de uso é mostrado abaixo.
## Instruction
### Goal
You are given a user query about querying for GTC sessions. Your task is to determine what topic or particular sessions
the user is looking for.
### Steps
1. You should first extract the major request from the user query.
– Understand the main search target in the user query, make sure you know what the user is looking for
– Pay attention to all the details or keywords that are relevant to the main search target and include them.
Please note that it is possible that the user will place the relevant keywords anywhere in the query but not necessarily
right next to the main search target. Please relate ALL relevant search keywords and complete the main search query.
– Include ALL non-filter/non-ranking **descriptive phrases** in `main_query` even if they don’t match available
criteria, but **Remove subjective descriptors** like “promising” in `main_query`
– EXCLUDE ALL the filtering and ranking criteria
– **Remove event references** (e.g., “GTC”, “SIGGRAPH”) from `main_query` even if they appear mid-phrase
2. Provide your understanding/explanation on the main query extracted.
– Write **EXACTLY 1-3 sentences** describing ONLY what the sessions are about, based strictly on the literal words
in `main_query`.
– Use this template:
`”Sessions focused on [exact field from main_query]. These sessions typically discuss [general description of what
such sessions typically cover, elaborating on all KEY PHRASES from the main_query. Where appropriate, briefly mention
common goals, benefits, or general approaches relevant to the topic, as long as they are directly related to the key
phrases and align with common understanding in the field.].”`
– **Do NOT mention any specific techniques, challenges, industries, methods, or examples unless they are explicitly stated
in the main_query.**
– **Do NOT add or infer information that is not present or clearly implied in the main_query.**
– **Elaborate on each key phrase in the main_query, providing context or typical session content that aligns with standard
interpretations in the AI/tech field.**
– **Ensure your explanation is clear, human-like, and aligns with normal human perception and expectations for such
sessions.**
– **Do NOT include any preamble, reasoning, or formatting other than the explanation sentence(s).**
– **Example**:
– User query 1: “Sessions about enabling AI-recommended knowledge articles for customer service agents”
– Explanation 1: “Sessions focused on enabling AI-recommended knowledge articles for customer service agents.
These sessions typically discuss how AI can recommend relevant articles in real time to help agents resolve customer
issues more efficiently.”
– User query 2: “Any sessions that introduce large language models (LLMs) and their applications?”
– Explanation 2: “Sessions focused on introducing large language models (LLMs) and their applications. These sessions
typically discuss what LLMs are, how they are developed, and their uses in tasks like text generation, translation,
and summarization.”
– User query 3: “Sessions on AI ethics and societal impact in technology”
– Explanation 3: “Sessions focused on AI ethics and societal impact in technology. These sessions typically discuss
ethical considerations in AI development and the broader effects of AI technologies on society.”
### Output
Output as the following JSON format
{{
“main_query”: “”, // string of major requests from the user query. Be as concise as possible while capturing all
the descriptive phrases.
“main_query_explanation”: “”, // Understanding/explanation on what kind of sessions the user is looking for
based on the main query
}}
## User query
{query}
## Your Final output
“`json
{{
YOUR OUTPUT
}}
“`
Para a consulta de exemplo, “Sessões para treinar um LLM para linguagem com poucos recursos”, a expansão da consulta pode aumentar significativamente a classificação das sessões mais relevantes retornadas por um retriever baseado em similaridade semântica. A Tabela 2 fornece mais detalhes.

Além disso, a expansão da consulta ajuda o reclassificador a se concentrar em um escopo mais amplo, mas ainda altamente relevante, durante o processo de classificação. Por exemplo, o token de pensamento lógico truncado do modelo Llama Nemotron com uma consulta diferente:
- Consulta original: “As frases-chave são ‘treinamento’, ‘LLM’ e ‘linguagem com poucos recursos'”
- Expansão da consulta: “As frases-chave são ‘linguagem com poucos recursos’, ‘dados de treinamento limitados’, ‘multilíngue’, ‘adaptação de domínio’ e assim por diante”
Observe que, com a expansão da consulta, o reclassificador está mais bem equipado para identificar sessões que discutem conceitos relacionados, mesmo que não usem os termos de consulta originais exatos. Essa perspectiva mais ampla permite que o reclassificador crie uma classificação mais abrangente e centrada no usuário, apresentando sessões que fornecem uma compreensão mais profunda da necessidade geral de informações do usuário.
Quais são os benefícios da reescrita de consultas?
Ao melhorar os resultados da pesquisa por meio da reescrita de consultas, o pipeline aprimorado oferece uma vantagem atraente sobre as abordagens tradicionais de RAG. A principal vantagem vem da reformulação inteligente das consultas do usuário. Isso adiciona contexto e detalhes cruciais. Esta etapa é responsável por criar um pool de candidatos de alta qualidade e altamente relevante, que é o maior fator na melhoria do desempenho do sistema.
Quais são os desafios dessa abordagem?
A reescrita de consultas requer inferência de IA, que consome muitos recursos e é mais lenta do que os métodos tradicionais, limitando a escalabilidade. Além disso, os LLMs só podem processar um número limitado de documentos de uma vez, necessitando de estratégias de janela deslizante para grandes conjuntos de candidatos. Isso aumenta a complexidade e pode prejudicar a qualidade do ranking global.
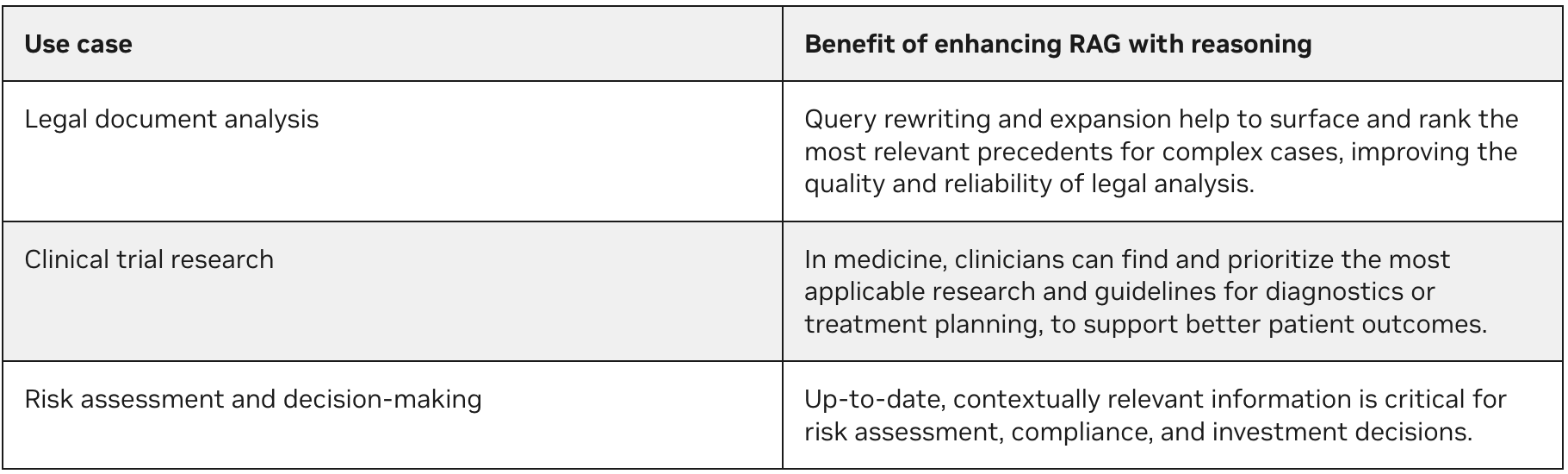
Quando otimizar um pipeline RAG
Esse pipeline RAG aprimorado é especialmente valioso em domínios onde a exatidão e a precisão são mais importantes do que a velocidade, conforme detalhado na Tabela 3.
Comece a aprimorar seus pipelines RAG
Nesta postagem, apresentamos uma abordagem inovadora para melhorar os pipelines RAG usando os recursos de raciocínio da família de modelos NVIDIA Llama Nemotron. Ao abordar as limitações dos métodos tradicionais, essa arquitetura aprimorada permite um acesso mais eficaz e centrado no usuário às informações, especialmente em cenários que exigem alta precisão e compreensão diferenciada.
Para saber mais sobre todos os recursos da coleção Llama Nemotron de modelos LLM, consulte Criar agentes de IA corporativos com modelos avançados de raciocínio NVIDIA Llama Nemotron. Você pode experimentar modelos NVIDIA NIM no NVIDIA API Catalog. Aprimore e acelere ainda mais seus pipelines RAG com o NVIDIA NeMo Retriever e o blueprint NVIDIA RAG.