
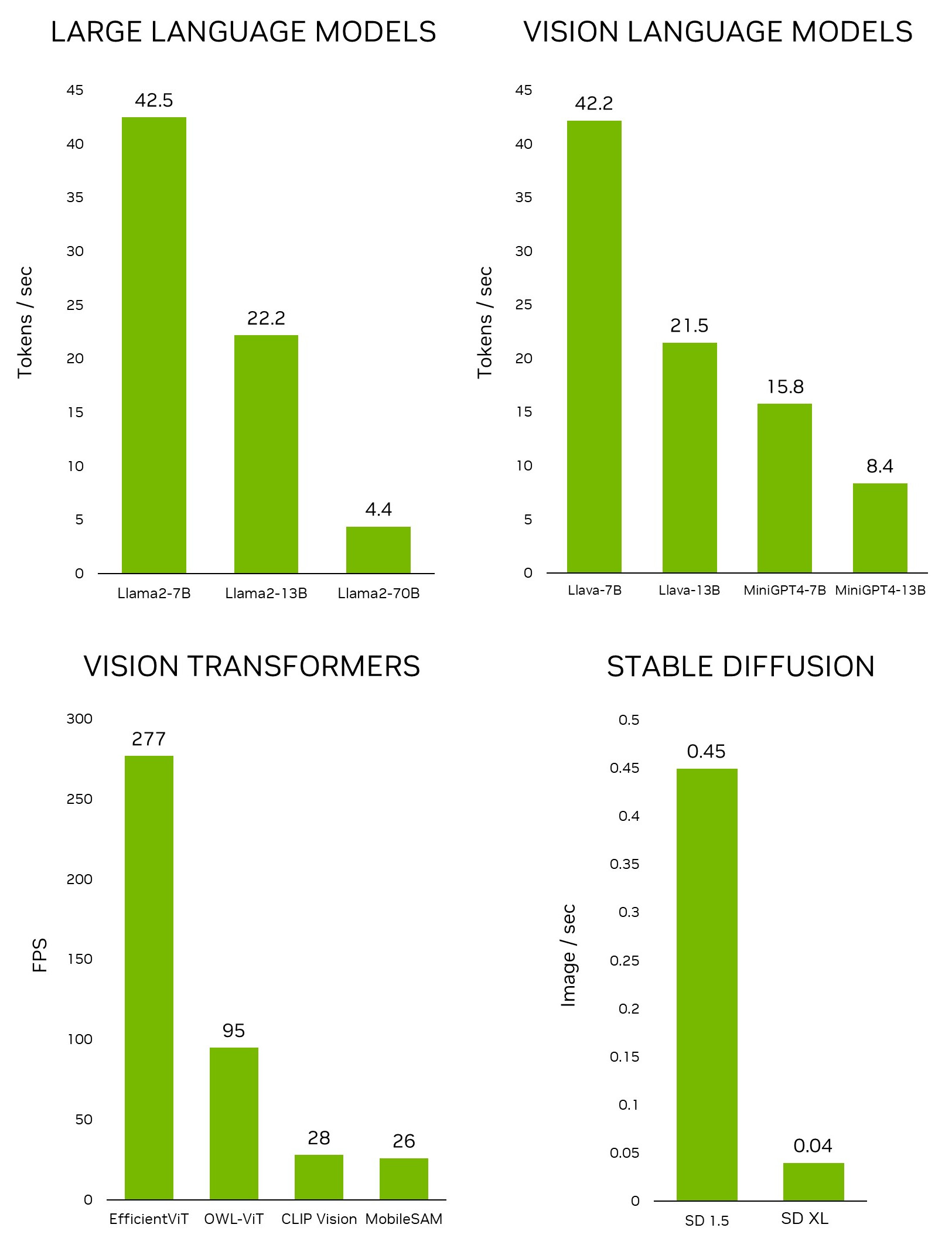
Recentemente, a NVIDIA revelou o Jetson Generative AI Lab, que capacita os desenvolvedores a explorar as possibilidades ilimitadas da IA generativa em um cenário do mundo real com dispositivos de edge NVIDIA Jetson. Ao contrário de outras plataformas embarcadas, o Jetson é capaz de executar grandes modelos de linguagem (LLMs), transformadores de visão e difusão estável localmente. Isso inclui o maior modelo Llama-2-70B no Jetson AGX Orin a taxas interativas.
Para testar rapidamente os modelos e aplicações mais recentes no Jetson, use os tutoriais e recursos fornecidos no Jetson Generative AI Lab. Agora você pode se concentrar em descobrir o potencial inexplorado das IAs generativas no mundo físico.
Neste post, exploramos as empolgantes aplicações de IA generativa que você pode executar e experimentar em dispositivos Jetson, todos os quais são amplamente abordados nos tutoriais de laboratório.
IA Generativa no Edge
No cenário em rápida evolução da IA, os holofotes brilham nos modelos generativos e no seguinte, em particular:
- LLMs que são capazes de se envolver em conversas semelhantes às humanas.
- Modelos de linguagem de visão (VLMs) que fornecem aos LLMs a capacidade de perceber e entender o mundo real através de uma câmera.
- Modelos de difusão que podem transformar prompts de texto simples em criações visuais impressionantes.
Esses notáveis avanços da IA capturaram a imaginação de muitos. No entanto, se você se aprofundar na infraestrutura que suporta essa inferência de modelo de ponta, muitas vezes os encontrará presos à nuvem, dependentes de data centers para seu poder de processamento. Essa abordagem centrada na nuvem deixa certas aplicações de edge, exigindo processamento de dados de alta largura de banda e baixa latência, em grande parte inexplorados.
A tendência emergente de executar LLMs e outros modelos generativos em ambientes locais está ganhando força dentro das comunidades de desenvolvedores. Comunidades online prósperas, como o r/LocalLlama no Reddit, fornecem uma plataforma para entusiastas discutirem os mais recentes desenvolvimentos em tecnologias de IA generativa e suas aplicações do mundo real. Numerosos artigos técnicos publicados em plataformas como a Medium se aprofundam nos meandros da execução de LLMs de código aberto em configurações locais, com alguns aproveitando o NVIDIA Jetson.
O Jetson Generative AI Lab serve como um hub para descobrir os mais recentes modelos e aplicações de IA generativa e aprender a executá-los em dispositivos Jetson. À medida que o campo evolui em um ritmo rápido, com novos LLMs surgindo quase diariamente e avanços em bibliotecas de quantização remodelando os benchmarks da noite para o dia, a NVIDIA reconhece a importância de oferecer as informações mais atualizadas e ferramentas eficazes. Oferecemos tutoriais fáceis de seguir e contêineres pré-construídos.
A força habilitadora são os Jetson-Containers, um projeto de código aberto cuidadosamente projetado e meticulosamente mantido para construir contêineres para dispositivos Jetson. Usando o GitHub Actions, ele está construindo 100 contêineres em formato de CI/CD. Isso permite que você teste rapidamente os mais recentes modelos, bibliotecas e aplicações de IA na Jetson sem o incômodo de configurar ferramentas e bibliotecas subjacentes.
O Jetson Generative AI Lab e os Jetson-Containers permitem que você se concentre em explorar as possibilidades ilimitadas da IA generativa em ambientes do mundo real com a Jetson.
Passo a Passo
Aqui estão algumas das empolgantes aplicações de IA generativa que são executadas no dispositivo NVIDIA Jetson disponíveis no Jetson Generative AI Lab.
stable-diffusion-webui
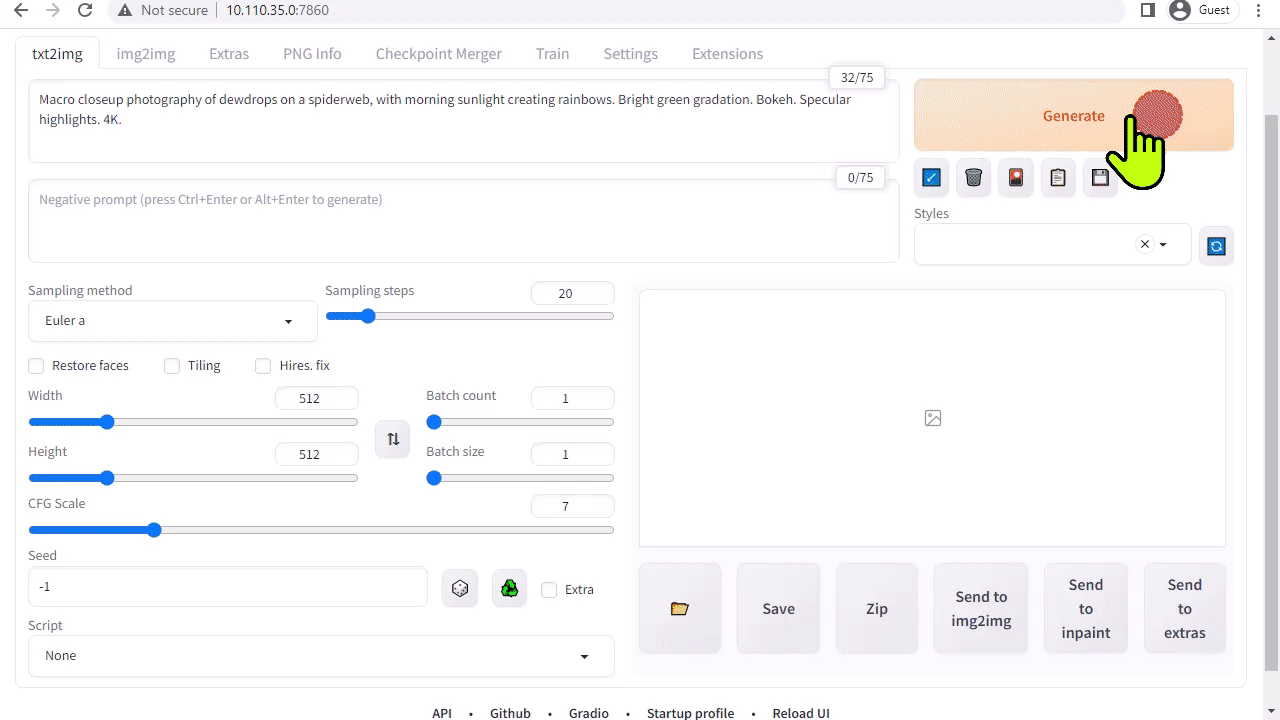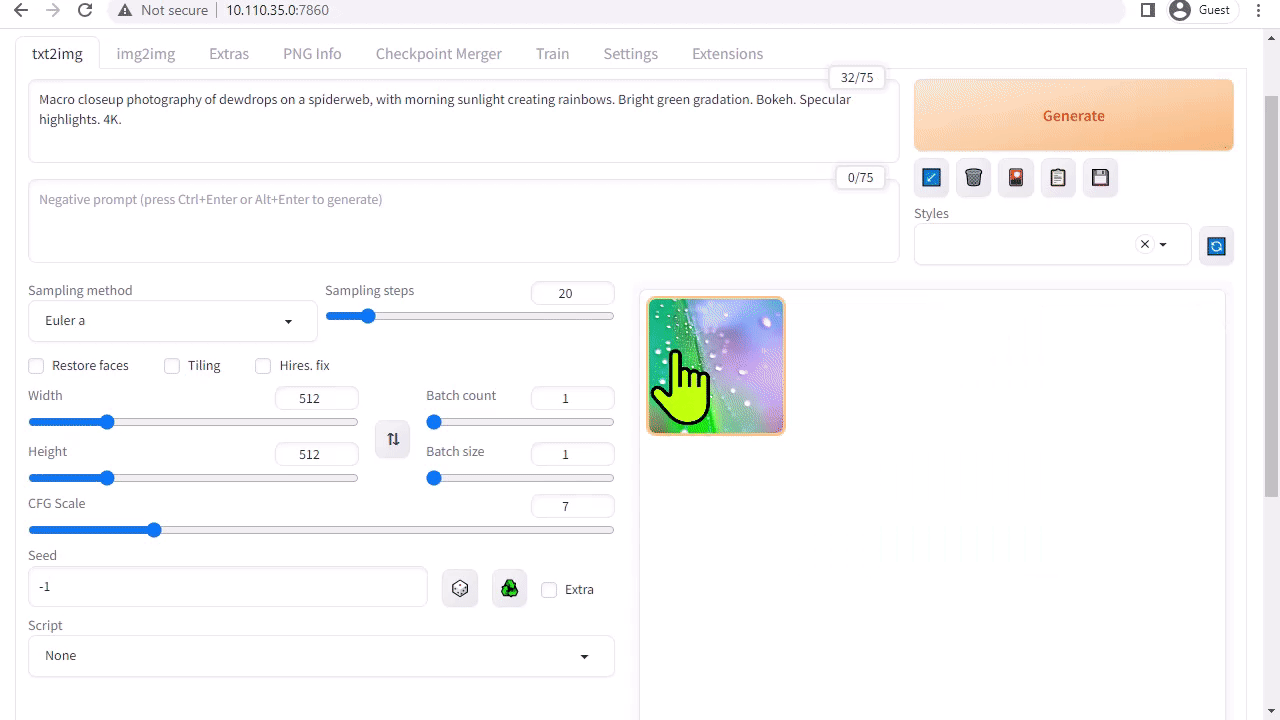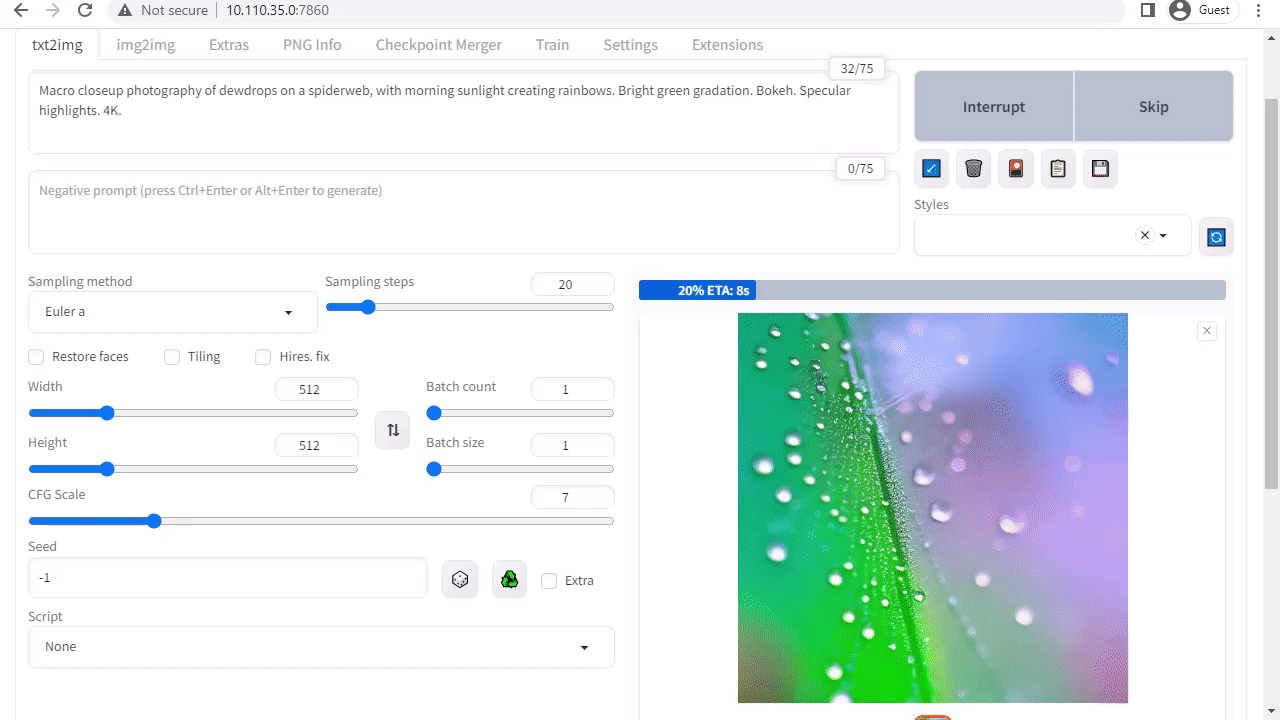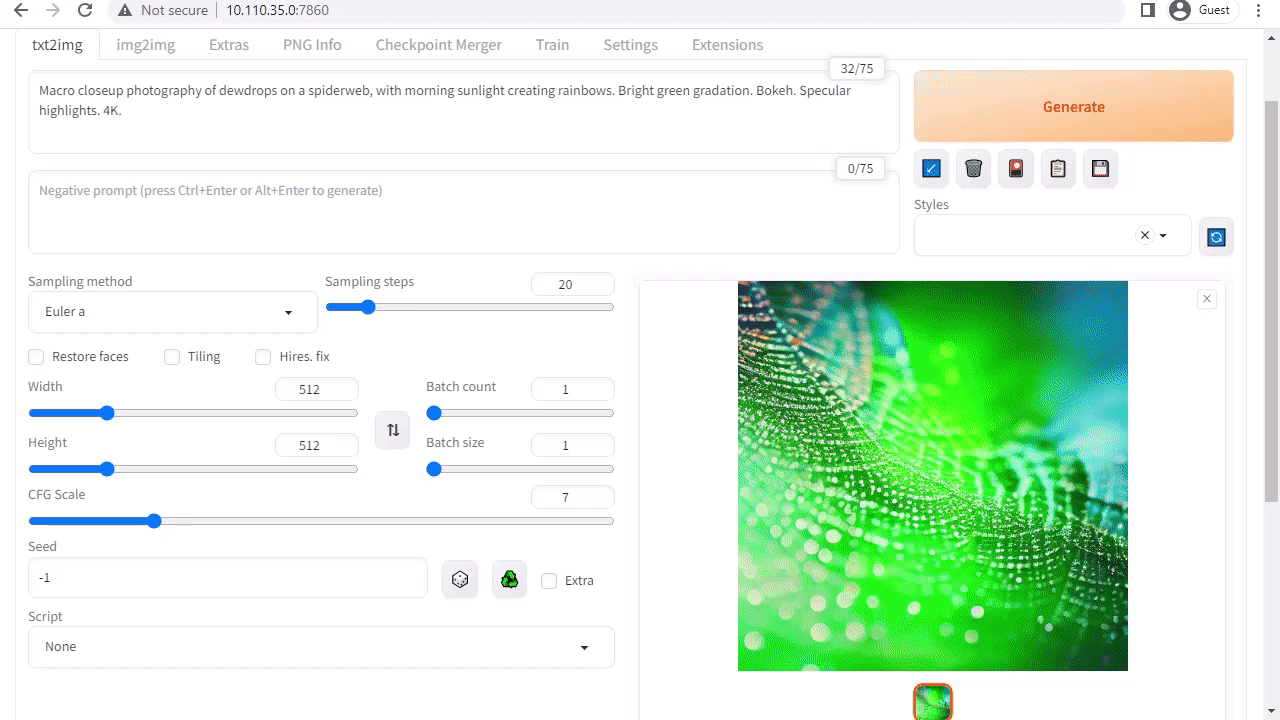
O stable-diffusion-webui do A1111 fornece uma interface amigável para a Stable Diffusion lançada pela Stability AI. Ele permite que você execute muitas tarefas, incluindo o seguinte:
- Txt2img: Gera uma imagem com base em um prompt de texto.
- img2img: Gera uma imagem a partir de uma imagem de entrada e um prompt de texto correspondente.
- inpainting: preenche as partes ausentes ou mascaradas da imagem de entrada.
- outpainting: expande a imagem de entrada além de suas bordas originais.
A aplicação web faz o download do modelo Stable Diffusion v1.5 automaticamente durante o primeiro acesso, para que você possa começar a gerar sua imagem imediatamente. Se você tem um dispositivo Jetson Orin, é tão fácil quanto executar os seguintes comandos, conforme explicado no tutorial.
git clone https://github.com/dusty-nv/jetson-containerscd jetson-containers./run.sh $(./autotag stable-diffusion-webui)Para obter mais informações sobre como executar stable-diffusion-webui, consulte o tutorial do Jetson Generative AI LAb. O Jetson AGX Orin também é capaz de rodar os novos modelos Stable Diffusion XL (SDXL), que geraram a imagem em destaque no topo deste post.
text-generation-webui
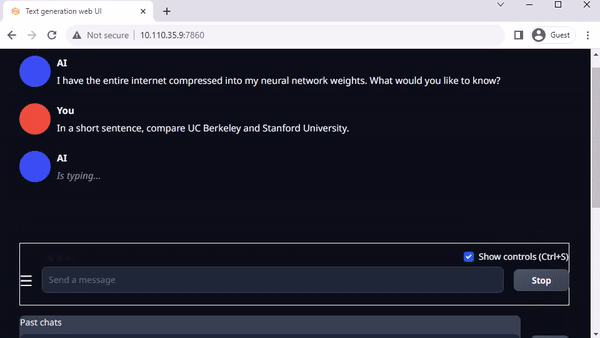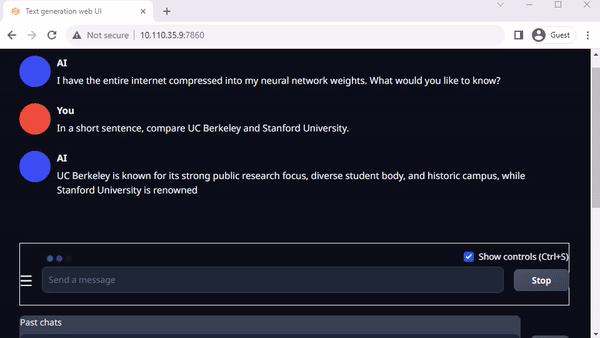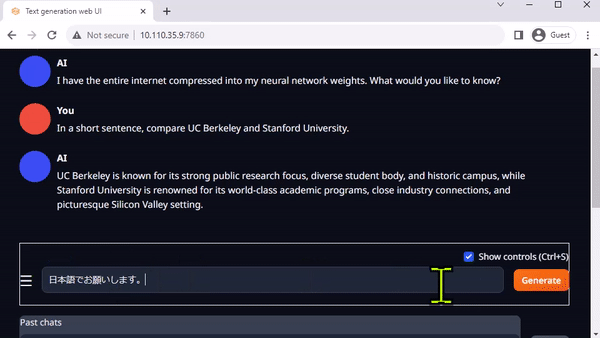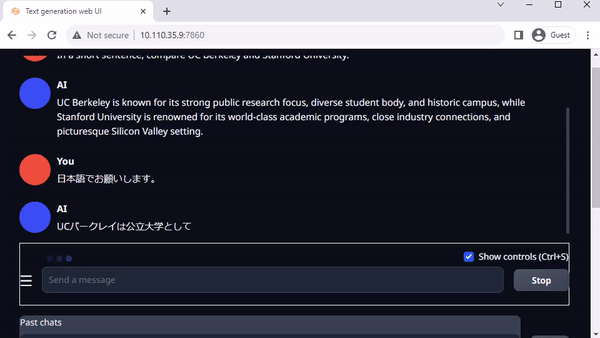
O text-generation-webui do Oobabooga é outra interface web popular baseada em Gradio para executar LLMs em um ambiente local. O repositório oficial fornece instaladores de um clique para plataformas, mas os Jetson-Containers oferecem um método ainda mais fácil.
Usando a interface, você pode facilmente fazer o download de um modelo do repositório de modelos do Hugging Face. Com a quantização de 4 bits, a regra geral é que o Jetson Orin Nano geralmente pode acomodar um modelo de parâmetro 7B, o Jetson Orin NX 16GB pode executar um modelo de parâmetro 13B e o Jetson AGX Orin 64GB pode executar modelos de parâmetros 70B.
Muitas pessoas estão agora trabalhando no Llama-2, o modelo de linguagem de código aberto da Meta, disponível gratuitamente para pesquisa e uso comercial. Existem modelos baseados em Llama-2 também treinados usando técnicas como giro fino supervisionado (SFT) e aprendizado por reforço a partir do feedback humano (RLHF). Alguns até afirmam que ele está superando o GPT-4 em alguns benchmarks.
Text-generation-webui fornece extensões e permite que você desenvolva suas próprias extensões. Isso pode ser usado para integrar sua aplicação, como você verá mais tarde no exemplo llamaspeak. Ele também tem suporte para VLMs multimodais como Llava e bate-papo sobre imagens.
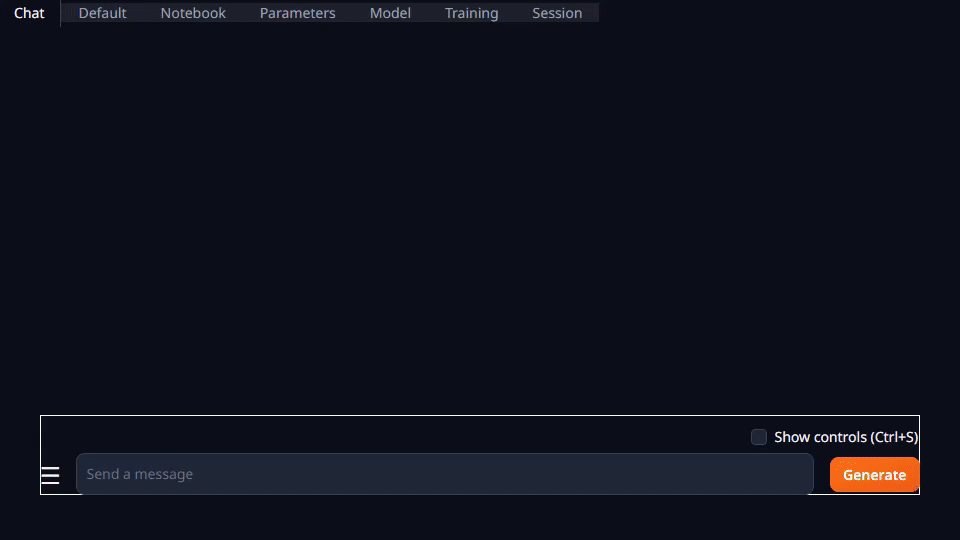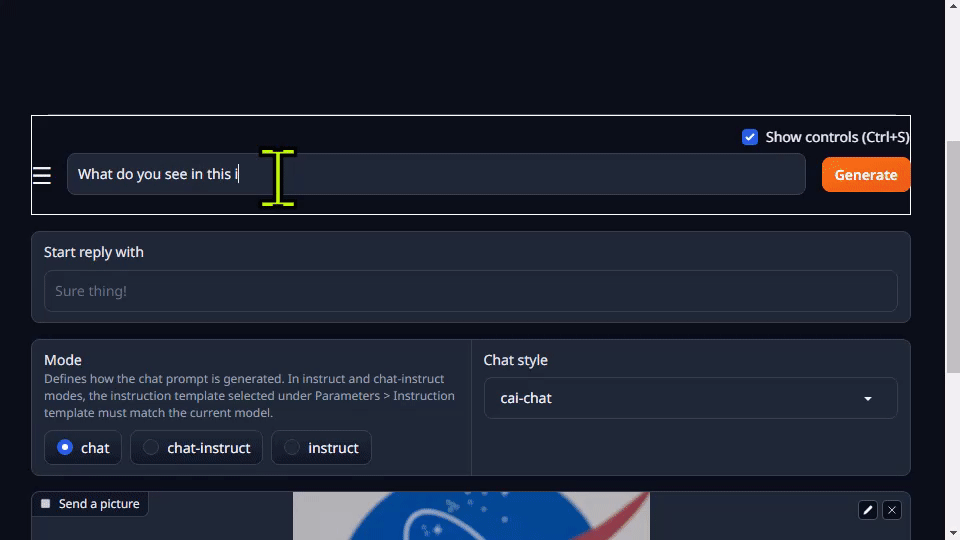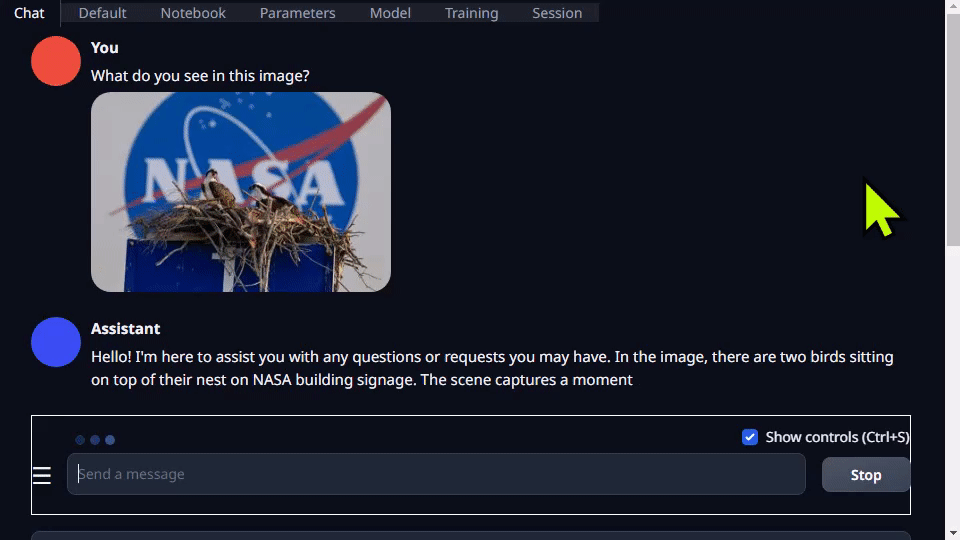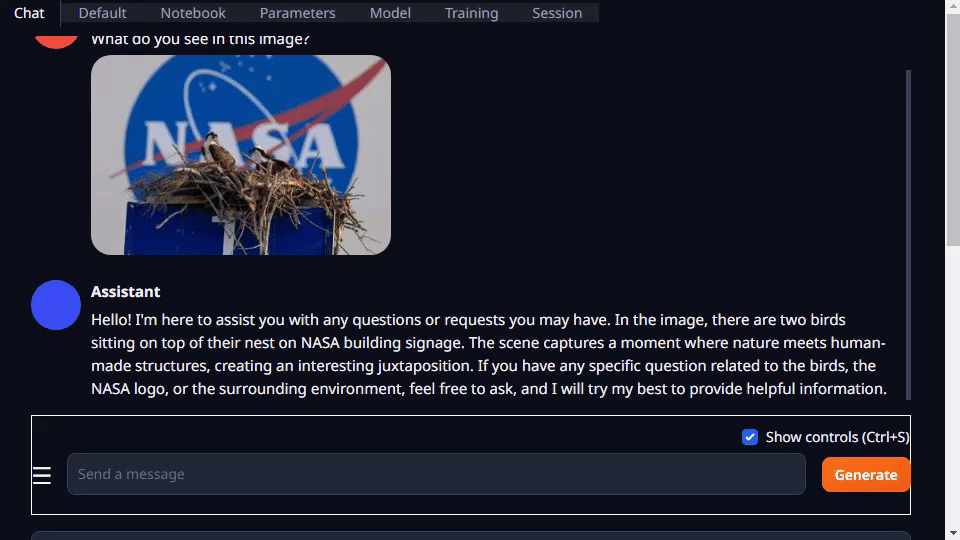
Para obter mais informações sobre como executar o text-generation-webui, consulte o tutorial do Jetson Generative AI Lab.
Llamaspeak
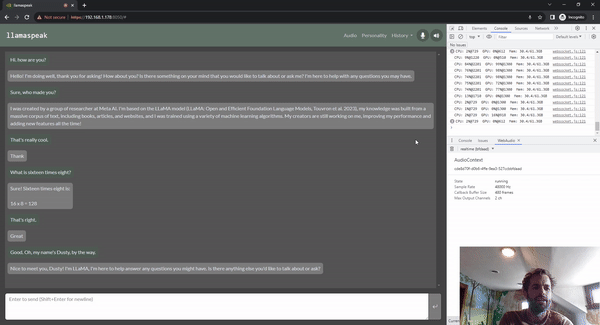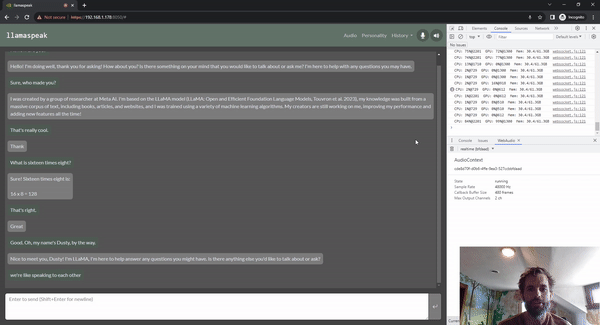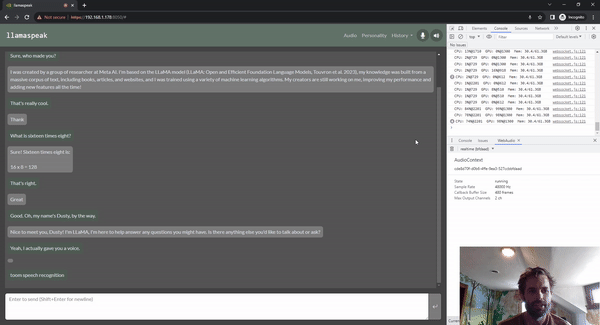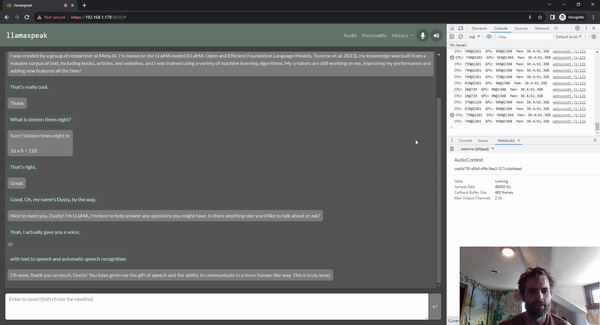
Llamaspeak é uma aplicação de bate-papo interativo que emprega NVIDIA Riva ASR/TTS ao vivo para permitir que você realize conversas verbais com um LLM em execução local. Atualmente, é oferecido como parte do Jetson-Containers.
Para realizar uma conversa de voz suave e perfeita, minimizar o tempo até o primeiro token de saída de um LLM é fundamental. Além disso, o llamaspeak foi projetado para lidar com a interrupção da conversação para que você possa começar a falar enquanto o llamaspeak ainda está bloqueando a resposta gerada. Os microsserviços de contêiner são usados para o Riva, o LLM e o servidor de bate-papo.
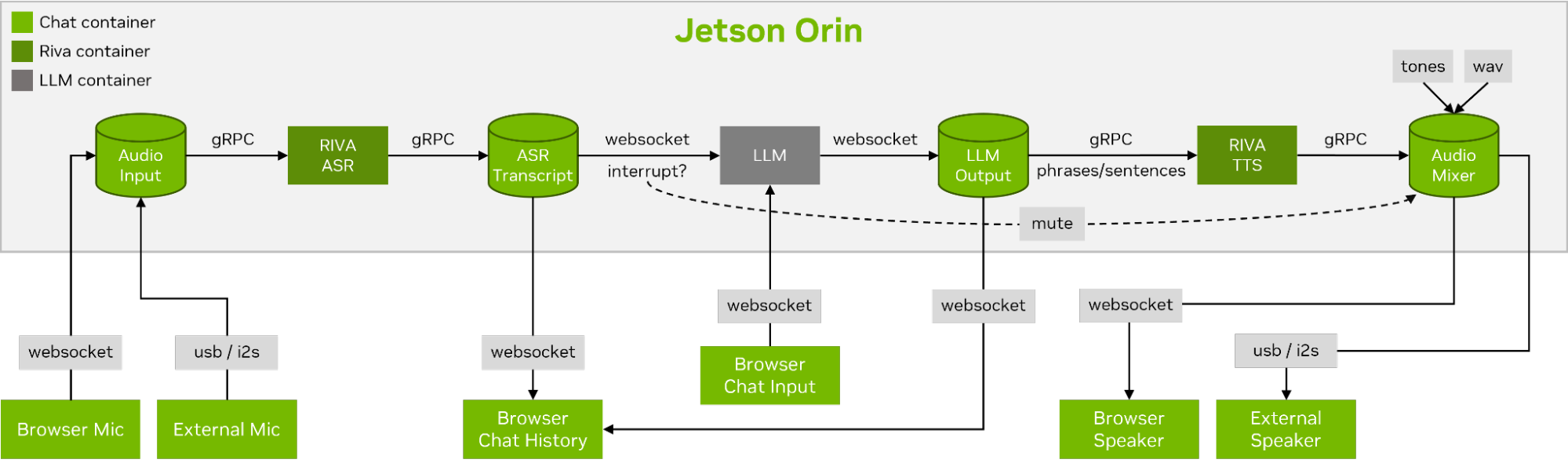
O llamaspeak tem uma interface responsiva com streaming de áudio de baixa latência a partir de microfones do navegador ou de um microfone conectado ao seu dispositivo Jetson. Para obter mais informações sobre como executá-lo sozinho, consulte a documentação Jetson-Containers.
NanoOWL

Open World Localization with Vision Transformers (OWL-ViT) é uma abordagem para detecção de vocabulário aberto, desenvolvida pelo Google Research. Esse modelo permite que você detecte objetos fornecendo prompts de texto para esses objetos.
Por exemplo, para detectar pessoas e carros, avise o sistema com texto descrevendo as classes:
prompt = “a person, a car”
Isso é incrivelmente valioso para o desenvolvimento rápido de novas aplicações, sem a necessidade de treinar um novo modelo. Para desbloquear aplicações no edge, nossa equipe desenvolveu um projeto, NanoOWL, que otimiza este modelo com NVIDIA TensorRT para obter desempenho em tempo real em plataformas NVIDIA Jetson Orin (~95FPS velocidade de codificação em Jetson AGX Orin). Esse desempenho significa que você pode executar o OWL-ViT bem acima das taxas de quadros comuns da câmera.
O projeto também contém um novo pipeline de detecção de árvore que permite combinar o modelo OWL-ViT acelerado com o CLIP para permitir a detecção e classificação de tiro zero em qualquer nível. Por exemplo, para detectar rostos e classificá-los como felizes ou tristes, use o seguinte prompt:
prompt = “[a face (happy, sad)]”
Para detectar rostos e, em seguida, detectar características faciais em cada região de interesse, use o seguinte prompt:
prompt = “[a face [an eye, a nose, a mouth]]”
Combine-os:
prompt = “[a face (happy, sad)[an eye, a nose, a mouth]]”
A lista continua. Embora a precisão desse modelo possa ser melhor para alguns objetos ou classes do que para outros, a facilidade de desenvolvimento significa que você pode experimentar rapidamente diferentes prompts e descobrir se ele funciona para você. Estamos ansiosos para ver que aplicações incríveis que você desenvolve!
Modelo Segment Anything
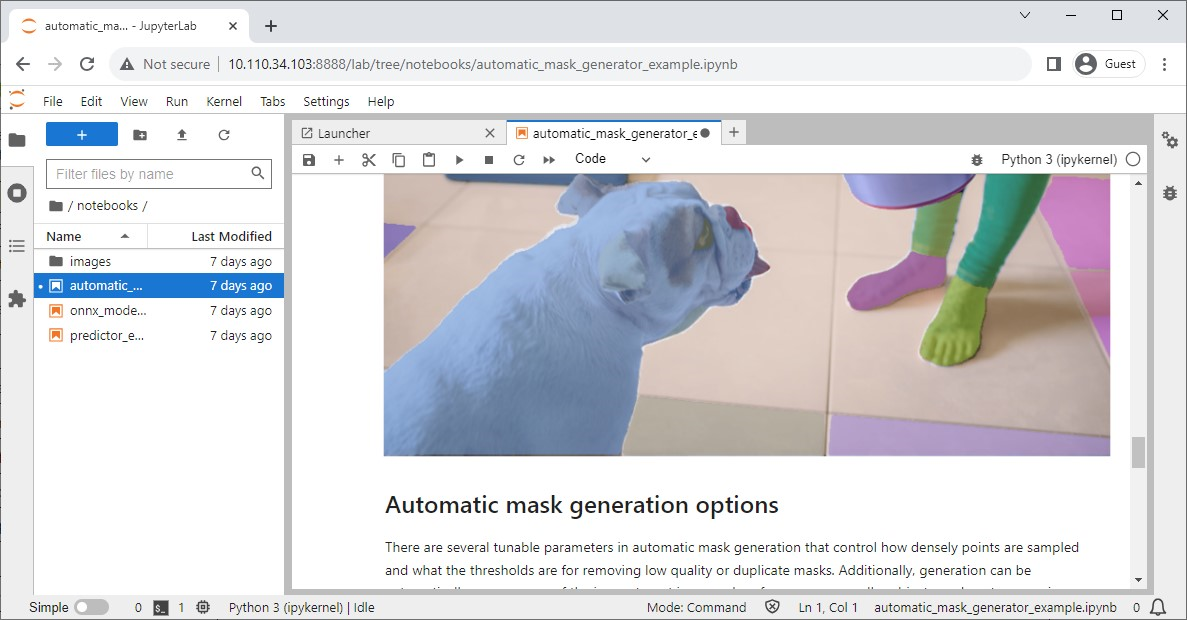
A Meta lançou o modelo Segment Anything (SAM), um modelo avançado de segmentação de imagens projetado para identificar e segmentar objetos com precisão dentro de imagens, independentemente de sua complexidade ou contexto.
Seu repositório oficial também tem notebooks Jupyter para verificar facilmente o impacto do modelo, e os Jetson-Containers oferecem um contêiner conveniente que tem o Jupyter Lab integrado.
NanoSAM

Segment Anything (SAM) é um modelo incrível que é capaz de transformar pontos em máscaras de segmentação. Infelizmente, ele não é executado em tempo real, o que limita sua utilidade em aplicações de borda.
Para superar essa limitação, lançamos recentemente um novo projeto, o NanoSAM, que destila o codificador de imagem SAM em um modelo leve. Ele também otimiza o modelo com NVIDIA TensorRT para permitir desempenho em tempo real em plataformas NVIDIA Jetson Orin. Agora, você pode facilmente transformar sua caixa delimitadora ou detector de ponto de chave existente em um modelo de segmentação de instância, sem a necessidade de qualquer treinamento.
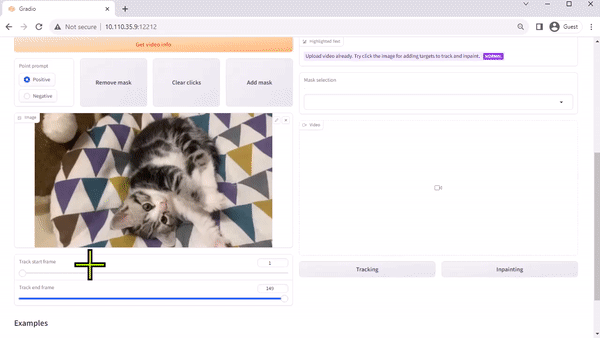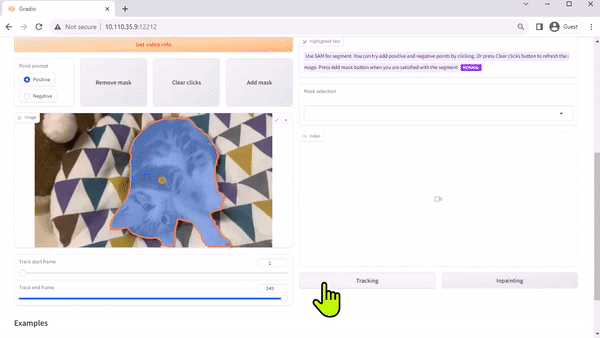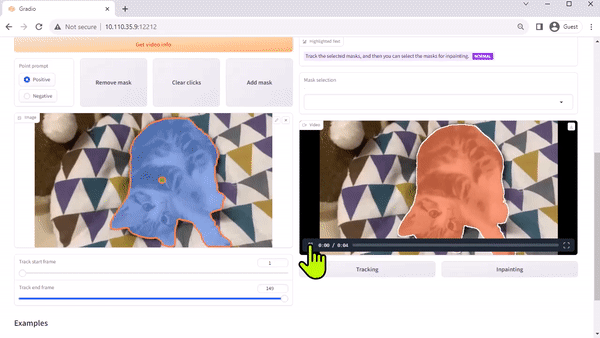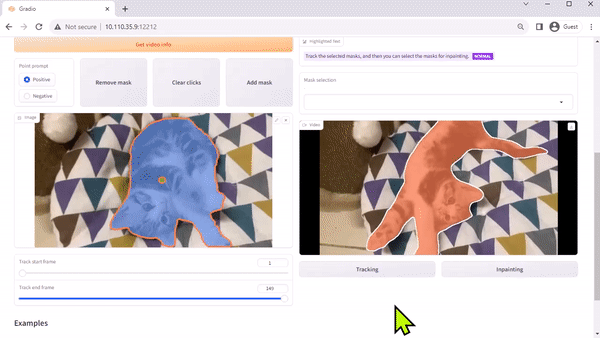
Modelo Track Anything
O Modelo Track Anything (TAM) é, como explica o artigo da equipe, “Segment Anything meets videos”. Sua interface de código aberto, baseada em Gradio, permite que você clique em um quadro de um vídeo de entrada para especificar qualquer coisa para rastrear e segmentar. Ele ainda mostra uma capacidade adicional de remover o objeto rastreado por inpainting.
NanoDB
Além de indexar e pesquisar efetivamente seus dados no edge, esses bancos de dados vetoriais são frequentemente usados em conjunto com LLMs para geração aumentada de recuperação (RAG) para memória de longo prazo além de seu comprimento de contexto interno (4096 tokens para modelos Llama-2). Os modelos de linguagem de visão também usam as mesmas incorporações que as entradas.
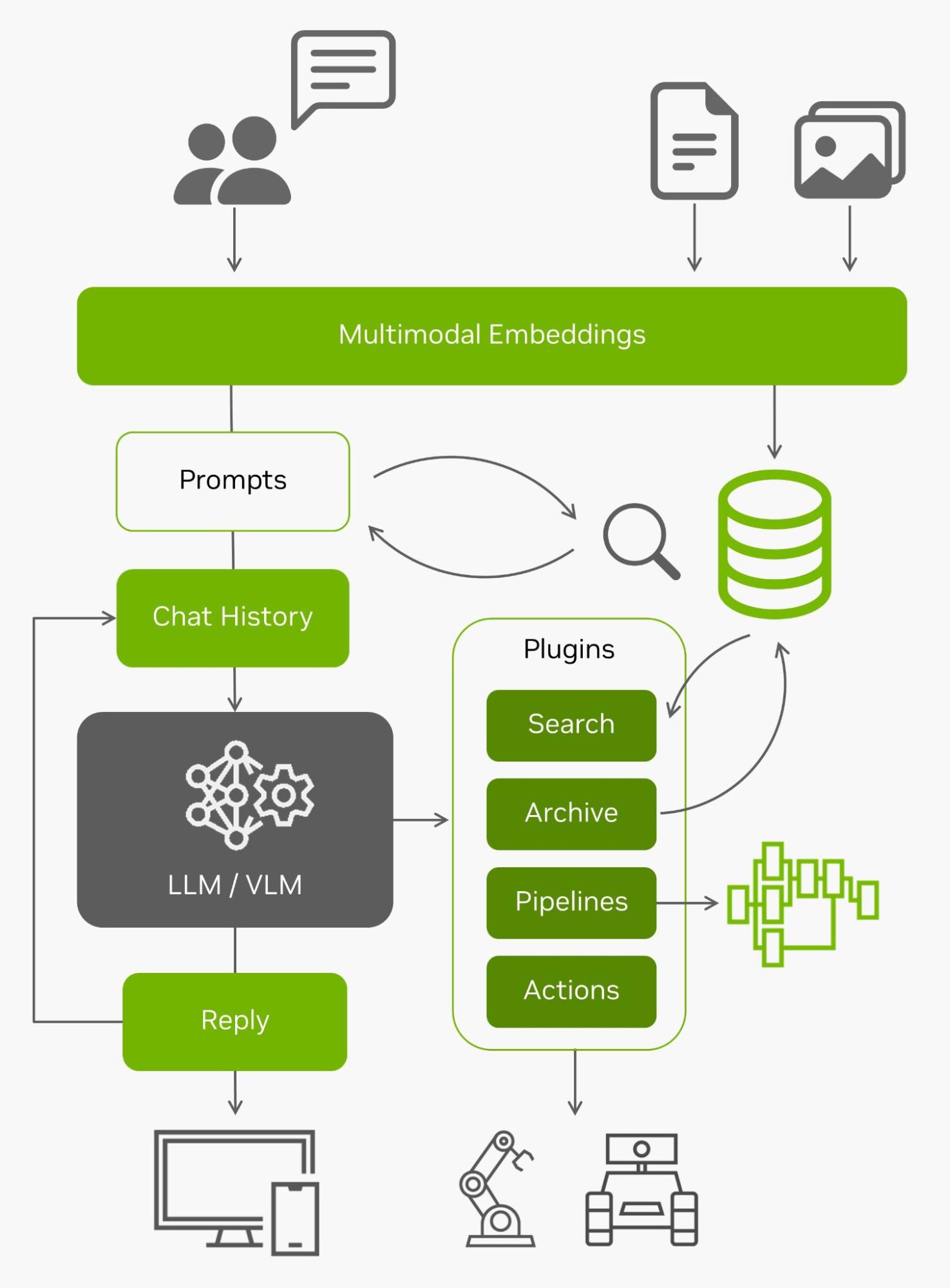
Com todos esses dados ao vivo vindos do edge e a capacidade de entendê-los, eles se tornam agentes capazes de interagir com o mundo real. Para obter mais informações sobre como experimentar o uso do NanoDB em suas próprias imagens e conjunto de dados, consulte o tutorial de laboratório.
Conclusão
Aí está! Inúmeras aplicações de IA generativa empolgantes estão surgindo, e você pode executá-las facilmente no Jetson Orin seguindo estes tutoriais. Para testemunhar os incríveis recursos das IA generativas rodando localmente, explore o Jetson Generativa AI Lab.
Se você constrói sua própria aplicação de IA generativa na Jetson e está interessado em compartilhar suas ideias, certifique-se de mostrar sua criação no fórum Jetson Projects.