O gargalo no avanço da AI deve ser a geração de ideias, não o hardware ou o software, afirmou Bryan Catanzaro, vice-presidente de pesquisa aplicada de deep learning na NVIDIA, no AI Hardware Summit nesta semana.
“Queremos que inventores, pesquisadores e engenheiros trabalhando na AI do futuro sejam limitados exclusivamente pelos próprios pensamentos”, disse Catanzaro ao público.
Catanzaro é líder de uma equipe de pesquisadores dedicados a aplicar o poder do deep learning a todas as áreas, dos videogames ao design de chips. No evento anual realizado no Vale do Silício, ele apresentou o trabalho que a NVIDIA está realizando para permitir avanços na AI, com foco na criação de grandes modelos de linguagem.
A CUDA é Para Quem Sonha
O treinamento e a implantação de grandes redes neurais são grandes desafios computacionais, e, por isso, um hardware extremamente rápido e altamente eficiente é uma necessidade, segundo Catanzaro.
Porém, o software que acompanha esse hardware pode ser ainda mais importante para desbloquear novos avanços na AI, explicou.
“No centro do nosso trabalho está a otimização conjunta de hardware e software, envolvendo desde chips até sistemas, softwares, frameworks, bibliotecas, compiladores, algoritmos e aplicações. Tudo isso é otimizado para oferecer recursos transformadores a cientistas, pesquisadores e engenheiros do mundo todo”, afirmou.
Essa abordagem de ponta a ponta assegura um desempenho excelente nos benchmarks padrão do setor, como o MLPerf. Ela também garante que os desenvolvedores não sejam limitados pela plataforma enquanto trabalham para desenvolver a AI.
“A CUDA é para quem sonha. A CUDA é para quem está sempre pensando em inovação”, disse Catanzaro. “Como as pessoas têm essas ideias e como podem testá-las com eficiência? Elas precisam de uma ferramenta geral e flexível, e é por isso que criamos o que criamos.”
Grandes Modelos de Linguagem Estão Mudando o Mundo
Uma das áreas mais interessantes da AI é a criação de modelos de linguagem, que está viabilizando aplicações inovadoras na compreensão da linguagem natural e na AI conversacional.
A complexidade de grandes modelos de linguagem está crescendo rapidamente, e o número de parâmetros dobra a cada dois meses.
Um exemplo conhecido de um modelo de linguagem grande e potente é o GPT-3, desenvolvido pela OpenAI. Com 175 bilhões de parâmetros, o modelo exigiu 314 zettaflops (1.021 operações de ponto flutuante) para o treinamento.
“É um nível absurdo de poder computacional. Ou seja, a criação de modelos de linguagem está começando a ficar restrita por aspectos econômicos”, disse Catanzaro.
As estimativas indicam que o treinamento do GPT-3 custaria cerca de US$12 milhões e, conforme observou Catanzaro, o rápido crescimento da complexidade do modelo significa que, apesar do trabalho incansável da NVIDIA para melhorar o desempenho e a eficiência de seu hardware e software, o custo do treinamento desses modelos continuará subindo.
Segundo Catanzaro, essa tendência sugere que, em pouco tempo, o treinamento de um único modelo poderá custar mais de US$1 bilhão em tempo de computação.
“Como seria construir um único modelo cujo treinamento custou US$1 bilhão? Ele precisaria representar a reinvenção de toda uma empresa e ser utilizável em muitos contextos diferentes”, explicou Catanzaro.
Catanzaro espera que esses modelos gerem muito valor, promovendo a inovação continuada. Durante a palestra, ele mostrou um exemplo dos recursos surpreendentes de grandes modelos de linguagem que resolvem novas tarefas sem terem recebido treinamentos específicos.
Depois de inserir alguns poucos exemplos em um grande modelo de linguagem (quatro frases, sendo duas em inglês e as outras duas, traduções para o espanhol), ele inseriu uma nova frase em inglês, que o modelo traduziu para o espanhol corretamente.
Embora nunca tivesse sido treinado para tradução, o modelo realizou a tarefa. Na verdade, ele foi treinado com “um enorme volume de dados da internet”, como descrito por Catanzaro, para prever a próxima palavra a aparecer em uma determinada sequência de texto.
Para realizar essa tarefa muito genérica, o modelo precisou conceber representações abstratas de conceitos, como a existência de idiomas em geral, os vocabulários e a gramática do inglês e do espanhol e a noção de uma tarefa de tradução, para entender a solicitação e responder de acordo.
“Esses modelos de linguagem são o primeiro passo em direção à inteligência artificial generalizada com aprendizado com poucos dados, o que é extremamente valioso e empolgante”, explicou Catanzaro.
Uma Abordagem Full-Stack da Criação de Modelos de Linguagem
Catanzaro também falou sobre o NVIDIA Megatron, um framework criado pela NVIDIA com PyTorch “para treinar os maiores modelos de linguagem baseados em transformadores do mundo eficientemente”.
Uma característica-chave do NVIDIA Megatron, que já foi usado por várias empresas e organizações para treinar grandes modelos baseados em transformadores, como destacado por Catanzaro, é o paralelismo de modelo.
O Megatron é compatível com o paralelismo intercamada (pipeline), que permite que diferentes camadas de um modelo sejam processadas em diferentes dispositivos, e com o paralelismo intracamada (tensor), que permite que uma única camada seja processada por vários dispositivos diferentes.
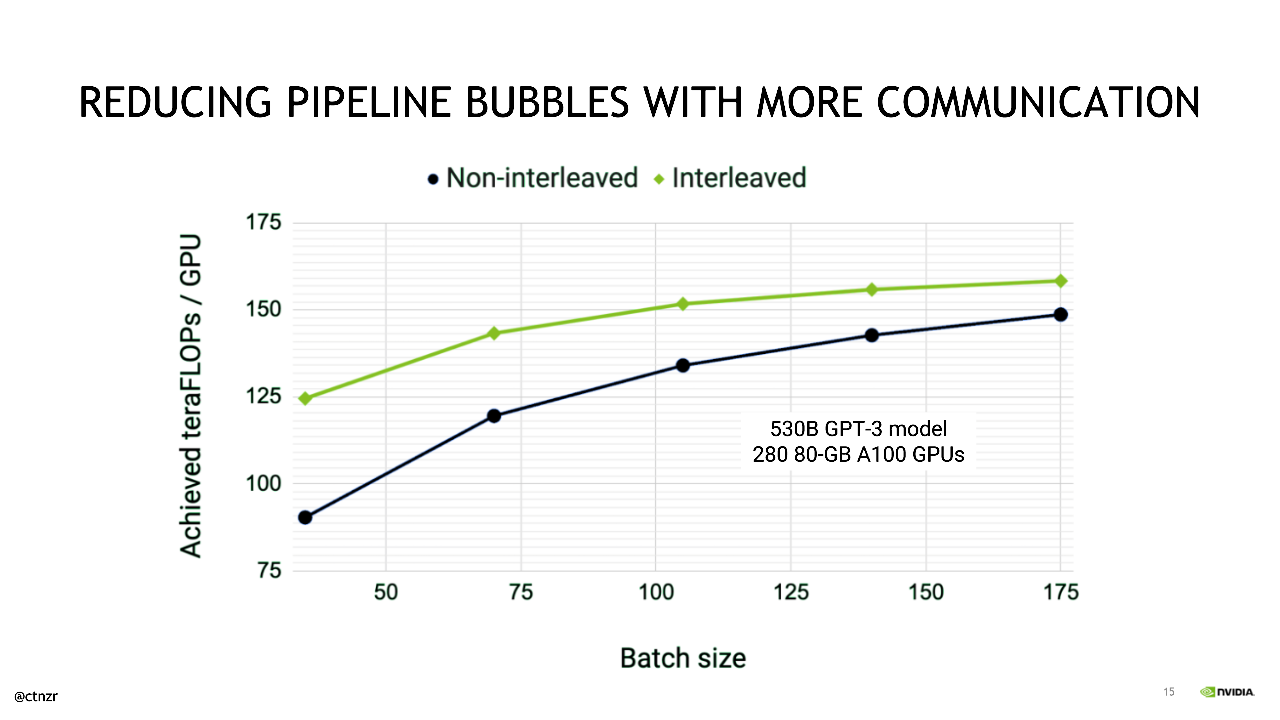
Catanzaro descreveu outras otimizações que a NVIDIA aplica para maximizar a eficiência do paralelismo de pipeline e minimizar as chamadas “bolhas de pipeline”, que ocorrem quando uma GPU não está realizando tarefas úteis.
Um lote é dividido em microlotes, cuja execução é feita com pipeline. Esse processo aumenta a utilização dos recursos da GPU em um sistema durante o treinamento. Com mais otimizações, é possível reduzir ainda mais as bolhas de pipeline.
Catanzaro apresentou uma otimização (publicada recentemente) que envolve a “distribuição igual de cada etapa (de pipeline) entre múltiplas GPUs para reduzir ainda mais a sobrecarga de bolhas de pipeline no escalonamento”.
Catanzaro mostrou que, embora exija mais do fabric de comunicação do sistema, essa otimização fornece uma aceleração significativa no treinamento de modelos estilo GPT-3 com o pacote completo de tecnologias de interconexão de alta largura de banda e baixa latência da NVIDIA.
Catanzaro então destacou o impressionante escalonamento de desempenho do Megatron no NVIDIA DGX SuperPOD, alcançando 502 petaflops sustentados em 3.072 GPUs, representando impressionantes 52 por cento do pico do Tensor Core em escala.
“Isso representa uma conquista de todos os NVIDIA e nossos parceiros na indústria: para ser capaz de fornecer esse nível de desempenho de ponta a ponta, é necessário otimizar toda a pilha de computação, de algoritmos a interconexões, de frameworks a processadores”, disse Catanzaro.