A IA generativa está transformando a computação, abrindo novos caminhos para os humanos interagirem com computadores de maneiras naturais e intuitivas. Para as empresas, a perspectiva de IA generativa é vasta. As empresas podem aproveitar seus conjuntos de dados avançados para simplificar tarefas demoradas, desde o resumo e a tradução de texto até a previsão de insights e a geração de conteúdo. Mas eles também devem enfrentar os desafios da adoção.
Por exemplo, os serviços de nuvem executados por grandes modelos de linguagem (LLMs) de uso geral simplificam a exploração. No entanto, esses recursos nem sempre podem estar alinhados com as necessidades da empresa, pois os modelos são treinados em conjuntos de dados amplos, em vez de dados específicos do domínio.
Como tal, as empresas estão construindo soluções personalizadas com inúmeras ferramentas de código aberto. Desde validar a compatibilidade até fornecer seu próprio suporte técnico, isso pode prolongar o tempo para adotar com sucesso a IA generativa nas empresas.
Projetado para desenvolvimento corporativo, o NVIDIA NeMo é uma plataforma de ponta a ponta para criar aplicações personalizadas de IA generativa em qualquer lugar. Ele oferece um conjunto de microsserviços de última geração para permitir um workflow completo, desde a automação do processamento distribuído de dados, passando pelo treinamento de modelos sob medida em grande escala usando técnicas sofisticadas de paralelismo 3D, até a conexão com seus dados privados usando a geração aumentada de recuperação (RAG).
Os modelos personalizados de IA generativa criados com o NeMo podem ser implantados no NVIDIA NIM, um conjunto de microsserviços fáceis de usar projetados para acelerar a implantação de IA generativa em qualquer lugar, no local ou na nuvem.
Para empresas que executam seus negócios em IA, o NVIDIA AI Enterprise é a plataforma de software de ponta a ponta que fornece o tempo de execução mais rápido e eficiente para modelos de base de IA generativa. Ele inclui NeMo e NIM para simplificar a adoção com segurança, estabilidade, capacidade de gerenciamento e suporte de classe empresarial.
Agora, as empresas podem integrar a IA em suas operações, simplificando processos, aprimorando os recursos de tomada de decisão e gerando maior valor.
IA Generativa Pronta para Produção com NVIDIA NeMo
O NeMo simplifica o caminho para a criação de modelos personalizados de IA generativa de nível empresarial, fornecendo recursos de ponta a ponta como microsserviços, bem como receitas para várias arquiteturas de modelo (Figura 1).
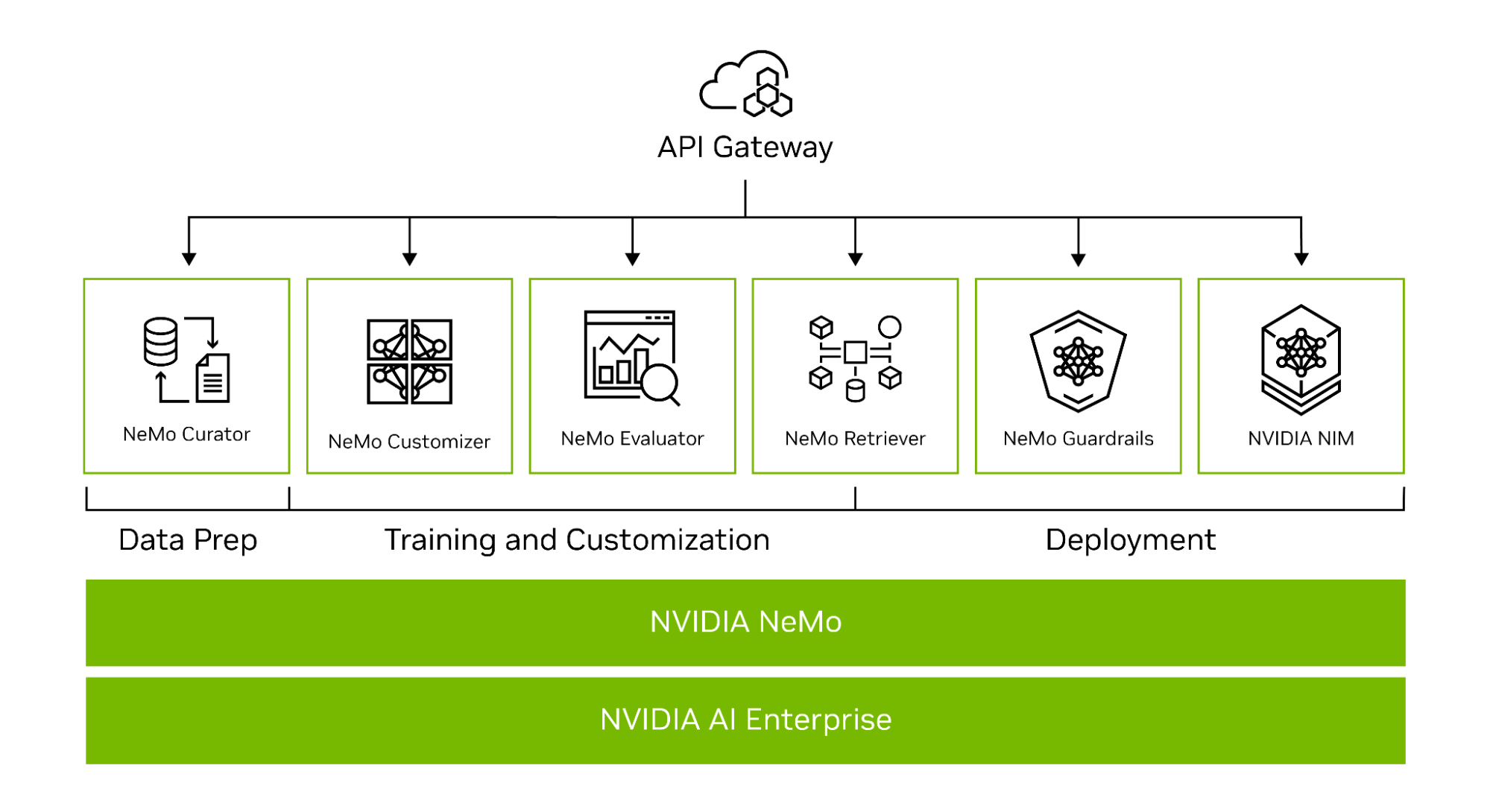
Para ajudá-lo a criar LLMs personalizados, a estrutura NeMo fornece ferramentas poderosas:
- NeMo Curator para curadoria de dados acelerada por GPU de conjuntos de dados de treinamento de alta qualidade
- NeMo Customizer para ajuste fino e alinhamento simplificados de LLMs
- NeMo Evaluator para avaliação automática da acurácia de LLMs
- NeMo Retriever para conectar modelos personalizados a dados de negócios proprietários usando RAG
- NeMo Guardrails para proteger os aplicativos de IA generativa de uma empresa
NeMo Curator
A demanda por conjuntos de dados de alta qualidade tornou-se um fator crítico na construção de LLMs funcionais.
O NeMo simplifica o processo muitas vezes complexo de curadoria de dados com o NVIDIA NeMo Curator, que aborda os desafios da curadoria de trilhões de tokens em conjuntos de dados multilíngues. Através de sua escalabilidade, essa ferramenta permite que você lide facilmente com tarefas como download de dados, extração de texto, limpeza, filtragem, eliminação exata ou difusa de duplicação e descontaminação de tarefas multilíngue a jusante. Para saber mais, consulte Dimensionar e Organizar Conjuntos de Dados de Alta Qualidade para Treinamento de LLM com o NeMo Curator.
Aproveitando o poder de tecnologias de ponta como Dask, RAPIDS cuDF, RAPIDS cuGraph e PyTorch, o NeMo Curator pode escalar processos de curadoria de dados em milhares de GPUs em rede, reduzindo significativamente os esforços manuais e acelerando o workflow de desenvolvimento.
Um dos avanços mais marcantes é no processo de desduplicação de dados, onde a aceleração da GPU demonstrou superar significativamente os métodos tradicionais de CPU. Usar uma GPU para eliminação de duplicação é até 26 vezes mais rápido e 6,5 vezes mais barato do que confiar em uma abordagem baseada em CPU. Essa melhoria notável não apenas reduz custos, mas também aumenta a eficiência, permitindo que os desenvolvedores processem dados em um ritmo sem precedentes.
A escalabilidade da tecnologia NVIDIA é incomparável, com a capacidade de utilizar milhares de GPUs. Essa escalabilidade é crucial para preparar grandes conjuntos de dados de pré-treinamento dentro de prazos realistas, uma tarefa que está se tornando cada vez mais importante à medida que os modelos de IA crescem em complexidade e tamanho.
Quando se trata de desempenho, os LLMs se beneficiam significativamente quando treinados em tokens preparados pelo NeMo Curator. Essa ferramenta garante que os dados direcionados aos LLMs sejam da mais alta qualidade, levando a modelos de melhor desempenho.
Em um futuro próximo, o NeMo Curator também dará suporte à curadoria de dados para personalização de modelos, como ajuste fino supervisionado (SFT) e abordagens de ajuste fino eficiente de parâmetros (PEFT), incluindo LoRA e P-tuning.
Solicite acesso antecipado aos microsserviços NVIDIA NeMo para obter o microsserviço NeMo Curator mais recente. Ele também vem empacotado no contêiner do framework NeMo, disponível através do catálogo NVIDIA NGC.
Treinamento Distribuído em Larga Escala
Há desafios distintos de aceleração e escala ao treinar LLMs de bilhões de parâmetros do zero. A tarefa requer poder de computação extenso e distribuído, clusters de hardware e memória baseados em aceleração, frameworks de machine learning (ML) confiáveis e escaláveis e sistemas tolerantes a falhas.
No centro do framework NeMo está a unificação do treinamento distribuído e do paralelismo avançado. O NeMo usa habilmente recursos de GPU e memória em todos os nós, resultando em ganhos de eficiência inovadores. Ao dividir o modelo e os dados de treinamento, o NeMo permite o treinamento contínuo de vários nós e várias GPUs, reduzindo significativamente o tempo de treinamento e aumentando a produtividade geral.
Técnicas de Paralelismo
Uma característica notável do NeMo é a incorporação de várias técnicas de paralelismo:
- Paralelismo de Dados
- Paralelismo de Dados Totalmente Fragmentado (FSDP)
- Paralelismo Tensorial
- Paralelismo de Dutos
- Paralelismo de Sequência
- Paralelismo Especializado
- Paralelismo de Contexto
Técnicas de Economia de Memória
Além disso, o NeMo suporta várias abordagens de economia de memória:
- Recálculo de Ativação Seletiva (SAR)
- Descarregamento da CPU (ativação, pesos)
- Atenção Flash (FA), Atenção de Consulta Agrupada (GQA), Atenção Multiconsulta (MQA), Atenção de Janela Deslizante (SWA)
O NeMo é a solução líder para apoiar o treinamento multimodalidade em escala. A plataforma suporta linguagem e modelos multimodais, incluindo Llama 2, Falcon, CLIP, Stable Diffusion, LLaVA e várias arquiteturas de IA generativa baseadas em texto, incluindo GPT, T5, BERT, Mixture of Experts (MoE) e RETRO. Além dos LLMs, o NeMo suporta vários modelos pré-treinados para visão computacional, reconhecimento automático de fala, processamento de linguagem natural e conversão de texto em fala.
O contêiner do framework NeMo disponível por meio do catálogo NGC fornece todas as ferramentas para as empresas treinarem modelos por conta própria.
Modelos NVIDIA AI Foundation
Embora algumas aplicações de IA generativa exijam o treinamento de um LLM do zero, a maioria das empresas usa modelos pré-treinados para criar seus LLMs personalizados. Essa abordagem acelera o processo, economizando tempo e recursos.
Ao ignorar as fases de coleta e limpeza de dados necessárias no vasto conjunto de dados usado para treinar um LLM do zero, você pode se concentrar em ajustar o modelo usando um conjunto de dados muito menor e específico para suas necessidades. Isso acelera o tempo até a solução final. Além disso, a carga de configuração de infraestrutura e treinamento de modelos é bastante reduzida, pois os modelos pré-treinados vêm com conhecimento pré-existente, prontos para serem personalizados.
A precisão é uma das medidas mais comuns usadas para avaliar modelos pré-treinados, mas também há outras considerações, incluindo tamanho do modelo, custo para ajustar, latência, taxa de transferência e opções de licenciamento comercial.
A NVIDIA torna mais fácil para os desenvolvedores alcançarem o melhor desempenho em infraestrutura acelerada e simplificam a transição para a IA de produção com os modelos NVIDIA AI Foundation.
Os modelos NVIDIA AI Foundation incluem modelos de comunidade líderes otimizados para desempenho e modelos NVIDIA de nível empresarial criados a partir de dados de origem responsável.
O NVIDIA TensorRT-LLM otimiza os modelos NVIDIA AI Foundation para latência e taxa de transferência para oferecer o mais alto desempenho. O treinamento é realizado com dados de origem responsável. Esses modelos oferecem resultados semelhantes aos modelos maiores, tornando-os ideais para aplicações corporativas.
Esses modelos são formatados para aproveitar as técnicas de personalização e paralelismo do NeMo e ajustar mais rapidamente com dados proprietários.
Com o recém-lançado catálogo de API da NVIDIA, os desenvolvedores podem experimentar os modelos diretamente de um navegador ou protótipo com endpoints de API hospedados pela NVIDIA para esses modelos. E quando prontos para implantação automática, os modelos básicos podem ser baixados e executados em qualquer data center, nuvem ou workstation acelerada por GPU.
NeMo Customizer
Empresas em vários setores exigem recursos exclusivos, e a personalização do modelo de IA generativa está evoluindo para acomodar suas necessidades. O NeMo oferece uma variedade de técnicas de personalização de LLM para refinar LLMs genéricos e pré-treinados para casos de uso especializados. O NVIDIA NeMo Customizer é um novo microsserviço escalável e de alto desempenho que ajuda os desenvolvedores a simplificar o ajuste fino e o alinhamento de LLMs.
O NeMo Customizer traz um conjunto de recursos avançados para a vanguarda do desenvolvimento de modelos de machine learning. Uma de suas características de destaque é o suporte a técnicas de ajuste fino e alinhamento de última geração, o que permite aos usuários alcançar um desempenho superior do modelo ajustando precisamente os modelos às necessidades específicas.
O NeMo Customizer utiliza técnicas avançadas de paralelismo, que não apenas melhoram o desempenho do treinamento, mas também reduzem consideravelmente o tempo necessário para treinar modelos complexos. Esse aspecto é particularmente benéfico nos ambientes de desenvolvimento acelerados de hoje, onde a velocidade e a eficiência são primordiais.
Projetado para suportar o ajuste fino de modelos maiores, dimensionando várias GPUs e vários nós, o NeMo Customizer aborda um dos desafios significativos no campo do deep learning.
Essa escalabilidade garante que até mesmo os modelos mais exigentes possam ser treinados de forma eficaz, tornando o NeMo Customizer uma ferramenta inestimável para pesquisadores e profissionais que desejam ultrapassar os limites do que é possível com IA. Para saber mais, consulte Ajustar e Alinhar LLMs Facilmente com o NVIDIA NeMo Customizer.
As empresas podem solicitar acesso antecipado aos microsserviços NVIDIA NeMo para começar a usar o microsserviço NeMo Customizer. Os desenvolvedores podem começar a personalizar modelos imediatamente usando o contêiner do framework NeMo disponível no catálogo NGC.
NeMo Evaluator
À medida que as empresas adaptam cada vez mais os LLMs para atender às suas necessidades operacionais exclusivas, surge um requisito crítico para avaliar e otimizar continuamente esses modelos para garantir que eles ofereçam o mais alto nível de precisão e capacidade de resposta.
Esse processo de avaliação contínua é vital não apenas para manter o desempenho dos modelos em tarefas para as quais foram originalmente treinados, mas também para garantir que eles se adaptem efetivamente aos novos requisitos específicos da aplicação.
O NeMo Evaluator simplifica essa tarefa complexa por meio de recursos de benchmarking automatizados, permitindo a avaliação abrangente de LLMs pré-treinados e ajustados. Esta ferramenta suporta uma ampla gama de modelos, incluindo modelos base, modelos alinhados, LLMs específicos para tarefas, entre outros, oferecendo versatilidade na avaliação para diversas aplicações.
O microsserviço fornece um design aberto e extensível, permitindo a avaliação de modelos em relação a muitos benchmarks acadêmicos populares e conjuntos de dados personalizados. O NeMo Evaluator foi projetado para garantir eficiência e flexibilidade para LLMs executados localmente, em qualquer nuvem ou data center. Para obter mais detalhes, consulte Simplificar a Avaliação de LLMs para Precisão com o NVIDIA NeMo Evaluator.
O NeMo Evaluator estende os recursos do NeMo Curator e do NeMo Customizer para oferecer um conjunto completo de ferramentas para ajudar as empresas a construir modelos personalizados de IA generativa. Solicite acesso antecipado aos microsserviços NVIDIA NeMo.
NeMo Retriever
O NeMo Retriever é uma coleção de microsserviços que permite a pesquisa semântica acelerada de dados corporativos para fornecer respostas altamente precisas por meio do aumento da recuperação. Para obter mais detalhes, consulte Traduza Seus Dados Corporativos em Insights Acionáveis com o NVIDIA NeMo Retriever.
Esses microsserviços são adaptados para lidar com tarefas específicas, incluindo:
- Ingestão de grandes volumes de documentos na forma de arquivos PDF, documentos de escritório e outros arquivos rich text.
- Codificação e armazenamento desses documentos para pesquisa semântica.
- Interagindo com bancos de dados relacionais existentes.
- Procurar informações relevantes para responder a perguntas.
Com o NeMo Retriever, as empresas podem acessar recursos de recuperação de informações de classe mundial com a menor latência, maior taxa de transferência e máxima privacidade de dados, permitindo um melhor uso de dados proprietários para gerar insights de negócios em tempo real.
Comece hoje mesmo com os microsserviços NeMo Retriever no catálogo da API da NVIDIA. Para obter mais informações, confira os exemplos de código e exemplos de IA Generativa da NVIDIA.
NeMo Guardrails
No cenário em rápida evolução da IA generativa, a importância de implementar medidas de segurança robustas não pode ser exagerada. À medida que essas aplicações de IA se tornam cada vez mais integradas em uma ampla gama de indústrias, garantir sua operação segura e protegida é fundamental.
Os guardrails servem como um mecanismo crucial nesse sentido, atuando como restrições programáveis ou regras que regulam a interação entre usuários e LLMs. Semelhante à maneira como os guardrails físicos nas rodovias impedem que os veículos se desviem do curso, esses guardrails digitais são projetados para monitorar, influenciar e controlar as interações de um usuário com sistemas de IA.
Eles ajudam a manter o foco das interações de IA dentro de limites predeterminados, impedindo a geração de conteúdo alucinatório, tóxico ou enganoso e bloqueando comandos maliciosos ou acesso não autorizado a aplicações de terceiros. Esse sistema de freios e contrapesos é essencial para preservar a integridade e a segurança de aplicações de IA generativa em vários domínios.
O NeMo Guardrails aborda esses desafios oferecendo um sofisticado sistema de gerenciamento de diálogos que prioriza a precisão, a adequação e a segurança em aplicações impulsionadas por LLMs. Ele fornece às empresas as ferramentas necessárias para aplicar os protocolos de segurança de forma eficaz, garantindo que seus sistemas de IA operem dentro dos parâmetros desejados.
Os Guardrails NeMo facilitam a fácil programação e implementação dessas medidas de segurança, oferecendo guardrails programáveis difusos que permitem interações flexíveis e controladas com o usuário. Seus recursos de integração com soluções prontas para empresas, incluindo Langchain e outras aplicações de terceiros, reforçam a segurança dos sistemas LLM contra ameaças potenciais.
Ao se integrar profundamente ao ecossistema LLM mais amplo e oferecer suporte a frameworks populares, o NeMo Guardrails garante que as aplicações de IA generativa permaneçam seguras e alinhadas com os valores, políticas e objetivos organizacionais. Para obter mais detalhes, consulte NVIDIA Habilita Sistemas de Conversação de Grandes Modelos de Linguagem Confiáveis, Seguros e Protegidos.
O NeMo Guardrails é um kit de ferramentas de código aberto para desenvolver facilmente sistemas de conversação LLM seguros e confiáveis que funcionam com todos os LLMs, incluindo o ChatGPT da OpenAI e o NVIDIA NeMo. Para começar, visite NVIDIA/NeMo-Guardrails no GitHub.
NVIDIA NIM
Para suportar a inferência de IA em ambientes de produção, a infraestrutura e os sistemas de suporte devem ser robustos, escaláveis e eficientes para facilitar a transição. As empresas estão agora reconhecendo a necessidade de investir e desenvolver essas infraestruturas para se manterem competitivas e aproveitarem todo o potencial da IA generativa.
Os microsserviços de inferência NVIDIA NIM simplificam o caminho para implantar modelos otimizados de IA generativa em ambientes corporativos. O NIM oferece suporte a um amplo espectro de modelos de IA, desde modelos de comunidade de código aberto até modelos NVIDIA AI Foundation, bem como modelos de IA personalizados. Para obter mais detalhes, consulte NVIDIA NIM Oferece Microsserviços de Inferência Otimizados para Implantar Modelos de IA em Escala.
Aproveitando as APIs padrão do setor, os desenvolvedores podem criar rapidamente aplicações de IA de nível empresarial com apenas algumas linhas de código. Construído sobre bases robustas, incluindo mecanismos de inferência de código aberto como o Servidor de Inferência NVIDIA Triton, NVIDIA TensorRT-LLM e PyTorch, o NIM facilita a inferência de IA em escala, garantindo que as aplicações de IA possam ser implantadas em escala com confiança na produção.
Para começar a usar o NIM, explore os modelos otimizados no catálogo de APIs da NVIDIA.
Alcançando IA Generativa de Nível Empresarial Perfeita
Como parte do NVIDIA AI Enterprise, o NeMo oferece compatibilidade em várias plataformas, incluindo nuvens, data centers e, agora, workstations e PCs com NVIDIA RTX. Isso permite uma verdadeira experiência de desenvolvimento e implantação em qualquer lugar, elimina as complexidades da integração e maximiza a eficiência operacional.
Adotantes de IA da Indústria
O NeMo já ganhou força significativa entre as empresas com visão de futuro que buscam construir LLMs personalizados. ServiceNow, Amdocs, Dropbox, Writer e Korea Telecom adotaram o NeMo, alavancando seus recursos para impulsionar suas iniciativas orientadas por IA.
Devido à sua flexibilidade e suporte incomparáveis, o NeMo abre um mundo de possibilidades. As empresas podem projetar, treinar e implantar soluções sofisticadas de LLM adaptadas a necessidades específicas e verticais do setor. Ao aproveitar o NVIDIA AI Enterprise e integrar o NeMo em seus workflows, sua empresa pode desbloquear novos caminhos de crescimento, obter insights valiosos e fornecer aplicações de ponta impulsionadas por IA para clientes, clientes e funcionários.
Introdução ao NVIDIA NeMo
Uma solução revolucionária, o NVIDIA NeMo está preenchendo a lacuna entre o vasto potencial da IA generativa e as realidades práticas enfrentadas pelas empresas. Como uma plataforma abrangente para desenvolvimento e implantação de LLM, o NeMo ajuda as empresas a adotar a tecnologia de IA de forma eficiente e econômica.
Com os poderosos recursos do NVIDIA NeMo, as empresas podem integrar a IA às operações, simplificar processos, aprimorar os recursos de tomada de decisão e desbloquear novos caminhos para o crescimento e o sucesso.
Comece a usar o NVIDIA NeMo para criar IA generativa pronta para produção para sua empresa. Para acessar os microsserviços NVIDIA NeMo, solicite agora o acesso antecipado. Você também pode obter pacotes no contêiner do framework NeMo, disponível através do catálogo NVIDIA NGC.