A plataforma NVIDIA Blackwell foi amplamente adotada pelos principais provedores de inferência, como Baseten, DeepInfra, Fireworks IA e Together IA para reduzir o custo por token em até dez vezes. Agora, a plataforma NVIDIA Blackwell Ultra está aproveitando o impulso para aprimorar a IA baseada em agentes.
Os agentes de IA e assistentes para programadores estão apresentando um crescimento explosivo em consultas de IA relacionadas à programação de software: de 11% para cerca de 50% no ano passado, de acordo com o relatório sobre o Relatório OpenRouter’s State of Inference. Essas aplicações exigem baixa latência para manter a capacidade de resposta em tempo real em workflows de várias etapas e contexto longo ao raciocinar em bases de código inteiras.
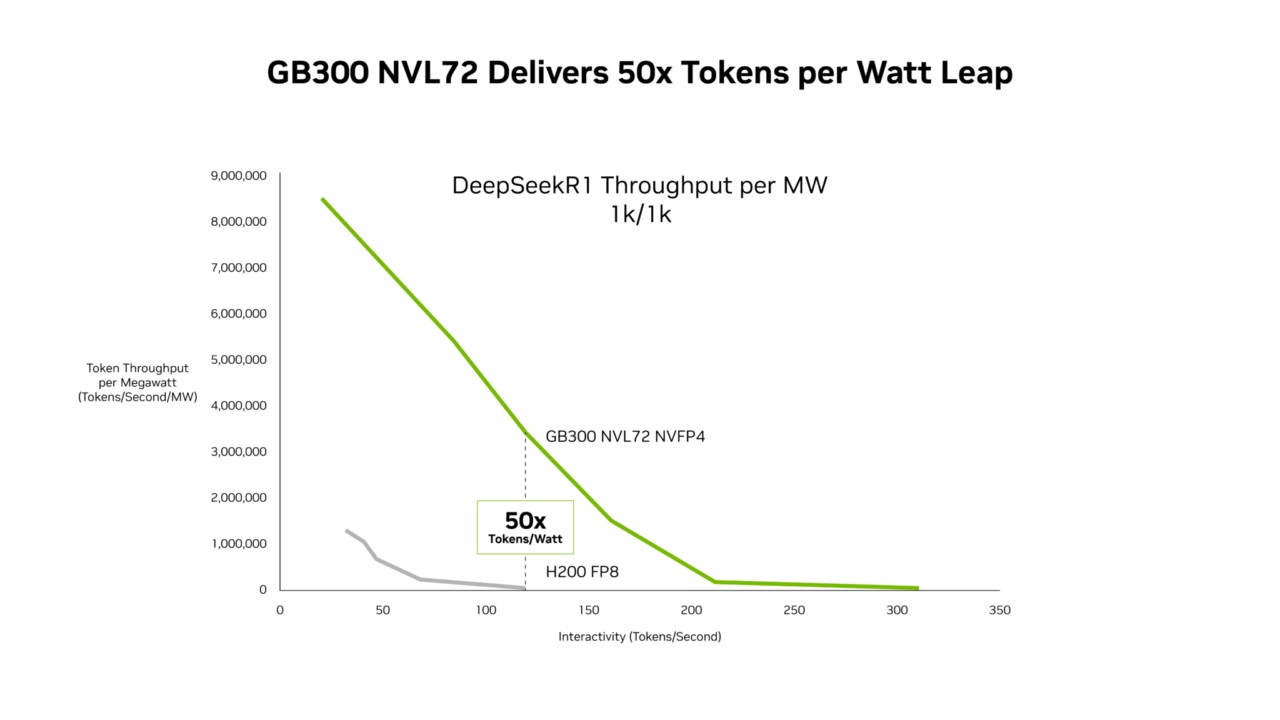
Os novos dados de desempenho do SemiAnalysis InferenceX mostram que a combinação das otimizações de software e da plataforma NVIDIA Blackwell Ultra ofereceu avanços em ambas as frentes. Os sistemas NVIDIA GB300 NVL72 agora oferecem uma taxa de processamento por megawatt até 50 vezes maior, resultando em um custo por token 35 vezes menor em comparação com a plataforma NVIDIA Hopper.
Ao inovar em chips, arquitetura de sistemas e software, o codesign extremo da NVIDIA acelera o desempenho em todas as cargas de trabalho de IA, desde programação baseada em agentes até assistentes interativos, ao mesmo tempo em que reduz os custos em escala.

GB300 NVL72 Oferece Desempenho até 50 Vezes Maior para Cargas de Trabalho de Baixa Latência
Uma análise recente do Signal65 mostra que o NVIDIA GB200 NVL72 com codesign extremo de hardware e software oferece 10x mais tokens por watt, resultando em um décimo do custo por token em comparação com a plataforma NVIDIA Hopper. Esses ganhos de desempenho continuam a se expandir à medida que o stack melhora.
As otimizações contínuas das equipes de NVIDIA TensorRT-LLM, NVIDIA Dynamo, Mooncake e SGLang continuam a aumentar significativamente a taxa de processamento do Blackwell NVL72 para inferência de mistura de especialistas (MoE) em todos os alvos de latência. Por exemplo, as melhorias na biblioteca NVIDIA TensorRT-LLM ofereceram desempenho até 5 vezes melhor no GB200 para cargas de trabalho de baixa latência em comparação com apenas quatro meses atrás.
- Os kernels de GPU de maior desempenho, otimizados para eficiência e baixa latência, ajudam a aproveitar ao máximo os recursos de computação da Blackwell e aumentam a taxa de processamento.
- A Memória Simétrica NVIDIA NVLink permite acesso direto à memória de GPU a GPU para uma comunicação mais eficiente.
- O lançamento PDL minimiza o tempo de inatividade ao lançar a fase de configuração do próximo kernel antes da conclusão do anterior.
Com base nesses avanços de software, o GB300 NVL72, que apresenta a GPU Blackwell Ultra, eleva a taxa de processamento por megawatt em 50x, quando comparada com a plataforma Hopper.
Esse ganho de desempenho se traduz em economia, com o NVIDIA GB300 reduzindo os custos em comparação com a plataforma Hopper em todo o espectro de latência. A redução mais drástica ocorre em baixa latência, onde as aplicações baseadas em agentes operam: custo até 35x menor por milhão de tokens em comparação com a plataforma Hopper.
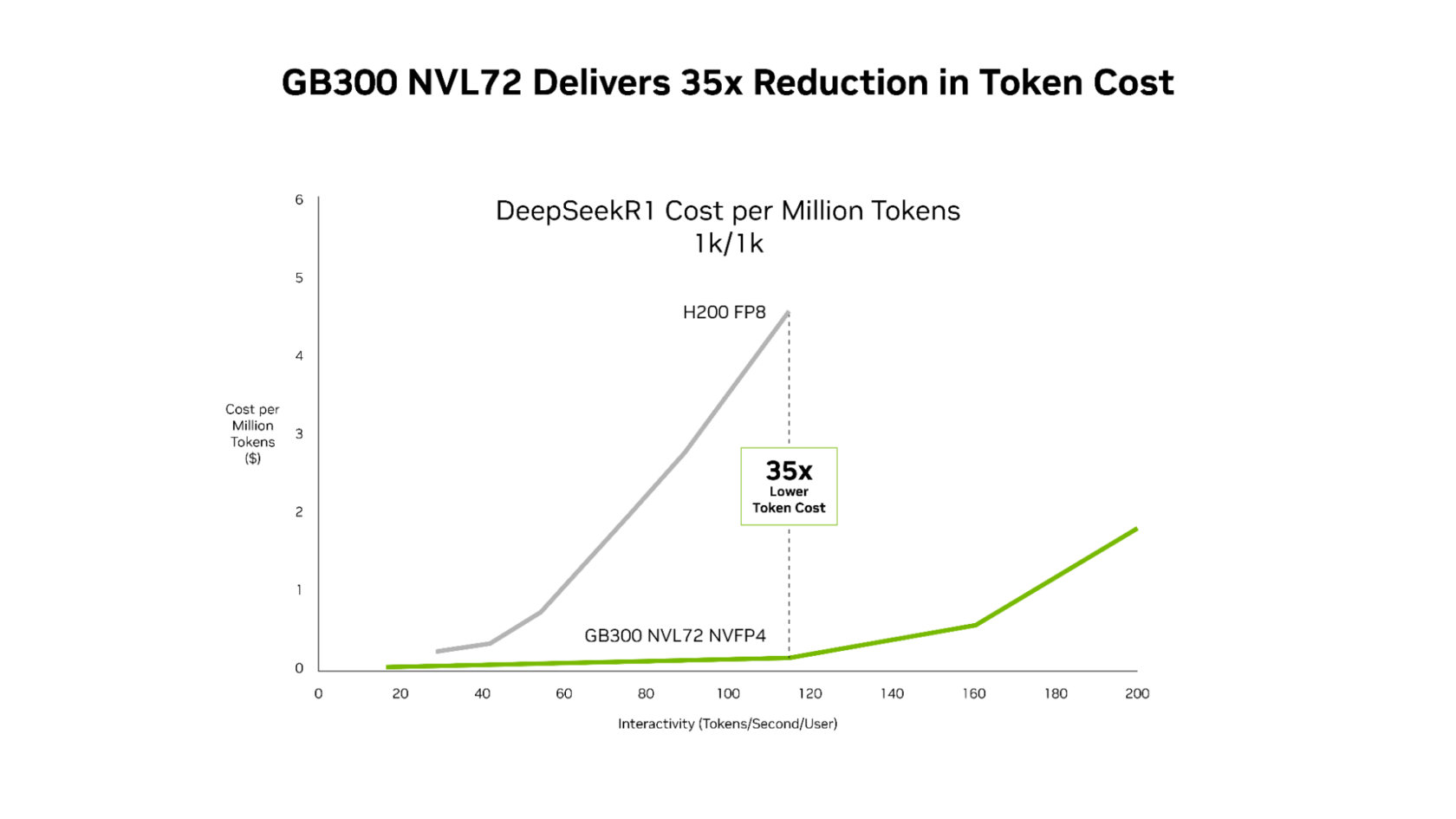
O NVIDIA GB300 NVL72 e o Stack de software projetado em conjunto, incluindo o NVIDIA Dynamo e o TensorRT-LLM, oferecem custo por token 35 vezes menor em comparação com a plataforma NVIDIA Hopper.
Para cargas de trabalho baseadas em agentes e assistentes interativos para programadores, em que cada milissegundo se compõe em workflows de várias etapas, essa combinação de otimização de software e hardware permite que as plataformas de IA executem experiências interativas em tempo real para um grande número de usuários.
GB300 NVL72 Oferece Economia Superior para Cargas de Trabalho de Longo Contexto
Embora o GB200 NVL72 e o GB300 NVL72 ofereçam latência ultrabaixa com eficiência, as vantagens distintas do GB300 NVL72 se tornam mais aparentes em cenários de contexto longo. Para cargas de trabalho com entradas de 128 mil tokens e saídas de 8 mil tokens, como assistentes de programação raciocinando em bases de código, o GB300 NVL72 oferece um custo por token até 1,5x menor em comparação com o GB200 NVL72.
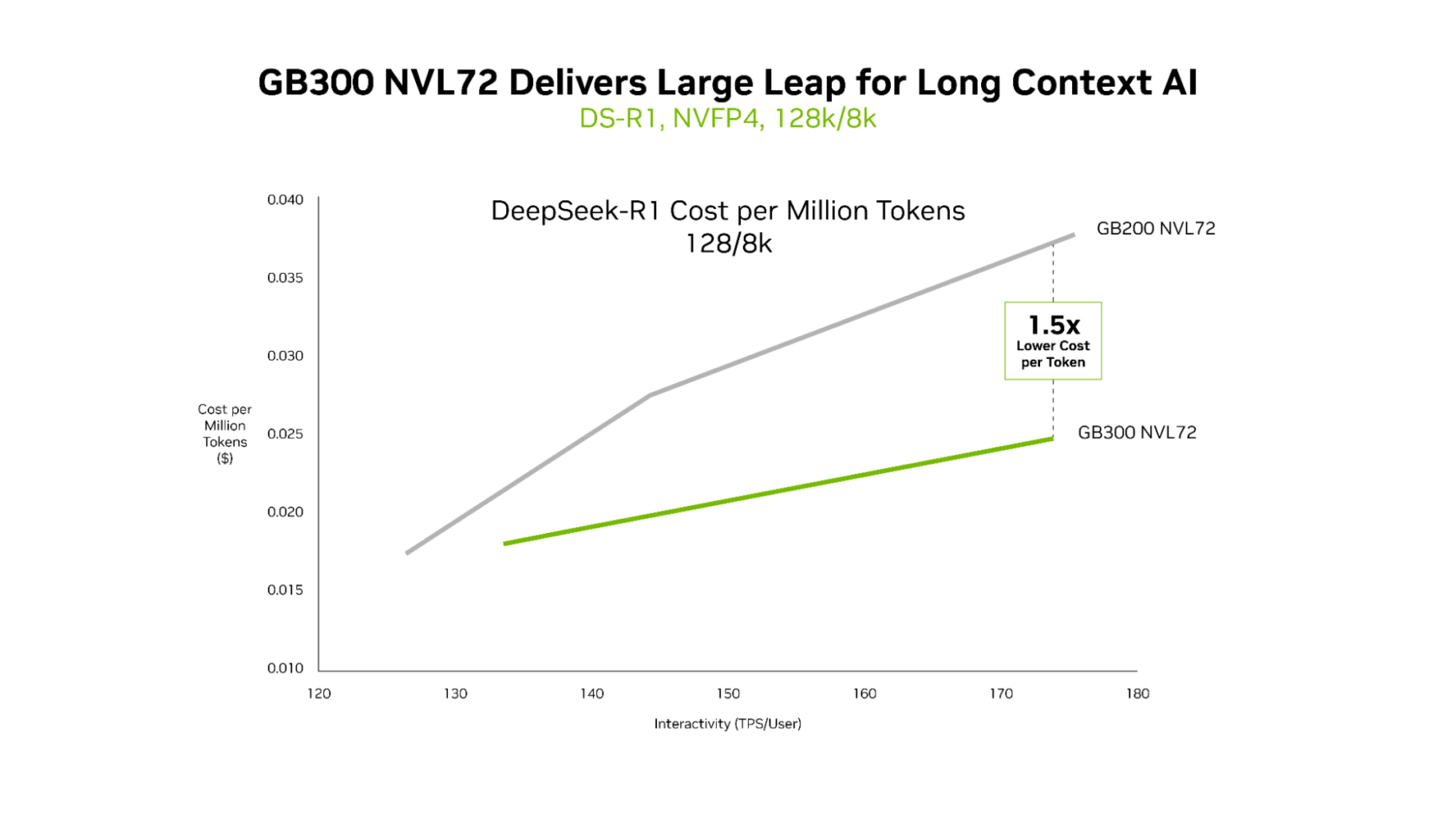
O NVIDIA GB300 NVL72 é ideal para cargas de trabalho de baixa latência e longo contexto.
O contexto cresce à medida que o agente lê mais código. Isso permite que ele entenda melhor a base de código, mas também requer muito mais computação. O Blackwell Ultra tem desempenho de computação NVFP4 1,5 vezes maior e processamento de atenção 2x mais rápido, permitindo que o agente entenda bases de código inteiras com eficiência.
Infraestrutura para IA Baseada em Agentes
Os principais provedores de Cloud e inovadores de IA já implantaram o NVIDIA GB200 NVL72 em escala e também estão implantando o GB300 NVL72. A Microsoft, a CoreWeave e a OCI estão implantando o GB300 NVL72 para casos de uso de baixa latência e longo contexto, como programação baseada em agentes e assistentes de programação. Ao reduzir os custos de tokens, o GB300 NVL72 possibilita uma nova classe de aplicações que podem raciocinar em grandes bases de código em tempo real.
“À medida que a inferência se move para o centro da produção de IA, o desempenho de longo contexto e a eficiência dos tokens se tornam críticos”, disse Chen Goldberg, vice-presidente sênior de engenharia da CoreWeave. “O Grace Blackwell NVL72 aborda esse desafio diretamente, e a Cloud de IA da CoreWeave, incluindo CKS e SUNK, foi projetada para traduzir os ganhos dos sistemas GB300, com base no sucesso do GB200, em desempenho previsível e eficiência de custo. O resultado é mais economia de tokens e inferência mais utilizável para clientes executando cargas de trabalho em grande escala”.
NVIDIA Vera Rubin NVL72 para Desempenho de Última Geração
Com os sistemas NVIDIA Blackwell implantados em escala, as otimizações contínuas de software continuarão desbloqueando melhorias de desempenho e custo em toda a base instalada.
Olhando para o futuro, a plataforma NVIDIA Rubin — que combina seis novos chips para criar um supercomputador de IA — está pronta para oferecer outra rodada de grandes saltos de desempenho. Para inferência de MoE, ele oferece uma taxa de processamento por megawatt até 10x maior em comparação com o Blackwell, traduzindo-se em um décimo do custo por milhão de tokens. E para a próxima onda de modelos de IA, Rubin pode treinar grandes modelos MoE usando apenas um quarto do número de GPUs em comparação com Blackwell.
Saiba mais sobre a plataforma NVIDIA Rubin e o sistema Vera Rubin NVL72.