Se você quiser participar da próxima grande onda de AI, obtenha um transformer.
Eles não são os robôs de brinquedo que mudam de forma que aparecem na TV nem os dispositivos presos nos postes telefônicos.
Então, o que é um Modelo Transformer?
Um modelo transformer é uma rede neural que aprende o contexto e, assim, o significado com o monitoramento de relações em dados sequenciais como as palavras desta frase.
Os modelos transformer aplicam um conjunto em evolução de técnicas matemáticas, chamadas de atenção ou autoatenção, para detectar as maneiras sutis como até mesmo elementos de dados distantes em uma série influenciam e dependem uns dos outros.
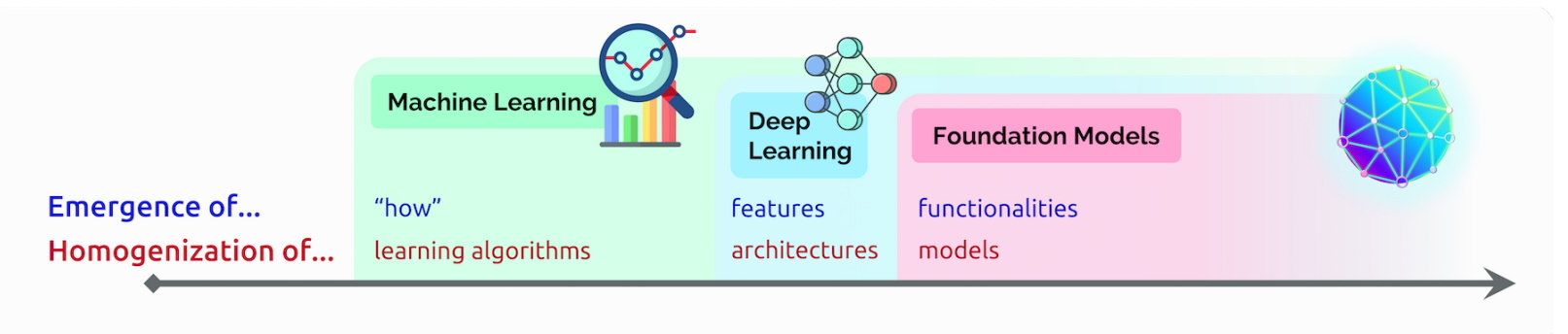
Descritos pela primeira vez em um artigo de 2017 do Google, os transformers estão entre os modelos mais novos e potentes já inventados até hoje. Eles estão impulsionando uma onda de avanços em machine learning, o que alguns chamam de AI de transformers.
Pesquisadores de Stanford chamaram os transformers de “modelos de fundação” em um artigo de agosto de 2021 porque os veem impulsionando uma mudança de paradigma na AI. A “escala e o escopo dos modelos de fundação nos últimos anos expandiram nosso entendimento do que é possível”, escreveram.
O que os Modelos Transformer Podem Fazer?
Transformers estão traduzindo texto e fala quase em tempo real, possibilitando que participantes diversos e com deficiências auditivas participem de reuniões e salas de aula.
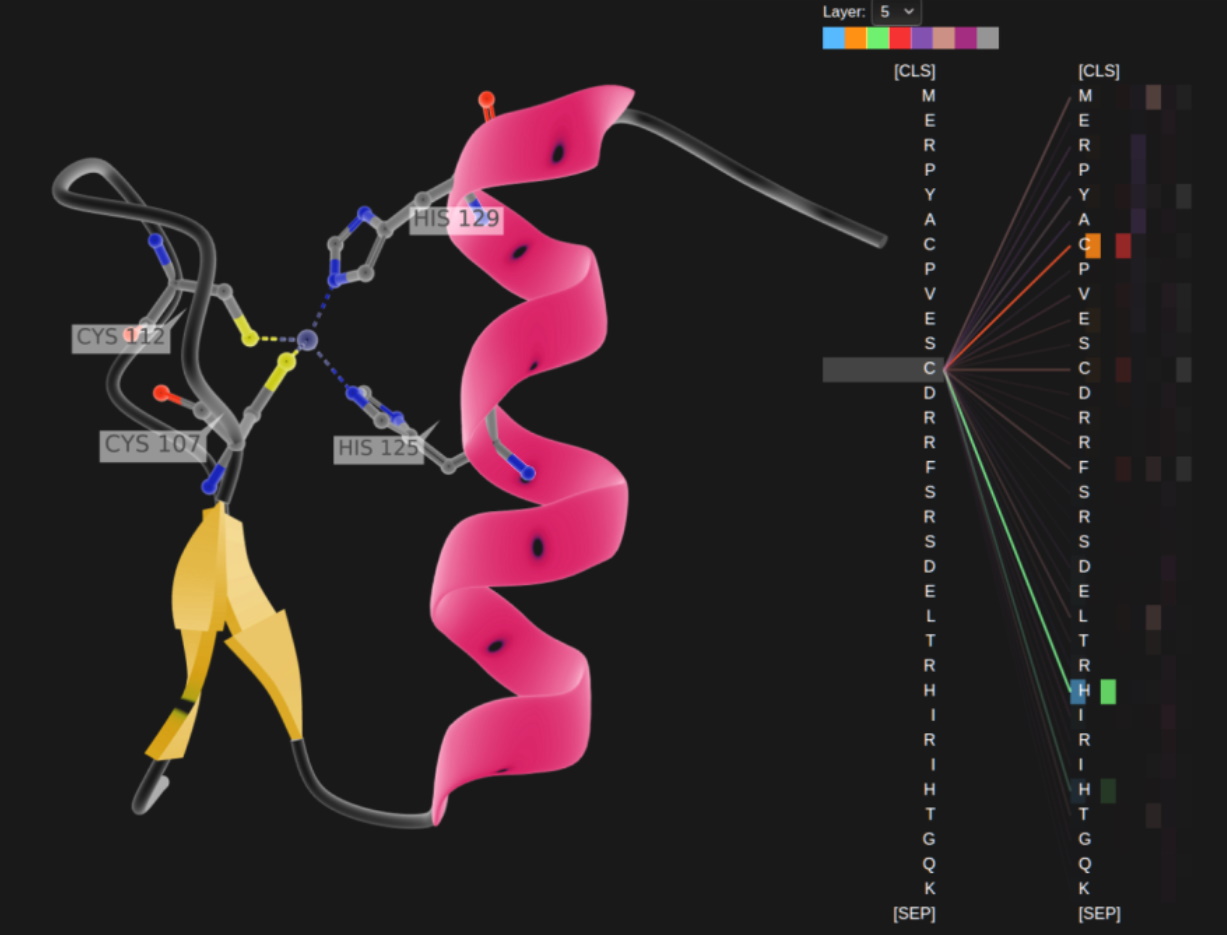
Eles estão ajudando os pesquisadores a entender as cadeias de genes no DNA e os aminoácidos nas proteínas de maneiras que podem acelerar a criação de medicamentos.
Os transformers podem detectar tendências e anomalias para evitar fraudes, simplificar a manufatura, fazer recomendações on-line ou melhorar a área da saúde.
As pessoas usam transformers toda vez que pesquisam no Google ou no Microsoft Bing.
O Círculo Virtuoso da AI de Transformer
Qualquer aplicação que use dados sequenciais de textos, imagens ou vídeos é uma candidata a modelos transformer.
Isso permite que esses modelos andem em um ciclo virtuoso na AI de transformers. Criados com grandes conjuntos de dados, os transformers fazem previsões precisas que impulsionam seu uso mais amplo, gerando mais dados que podem ser usados para criar modelos ainda melhores.
“Os transformers tornaram possível o aprendizado autossupervisionado, e a AI deu um salto na velocidade máxima”, disse o fundador e CEO da NVIDIA, Jensen Huang, na sua apresentação esta semana no GTC.
Transformers Substituem CNNs e RNNs
Em muitos casos, os transformers substituem as redes neurais convolucionais (CNNs – Convolutional Neural Networks) e as redes neurais recorrentes (RNNs – Recurrent Neural Networks), os tipos de modelos de deep learning que eram mais populares há apenas cinco anos.
De fato, 70% dos artigos do arXiv sobre AI publicados nos últimos dois anos mencionam transformers. Essa é uma mudança radical em relação a um estudo da IEEE de 2017 que relatou que RNNs e CNNs eram os modelos mais populares para reconhecimento de padrões.
Sem Rótulos, Mais Desempenho
Antes da chegada dos transformers, os usuários tinham que treinar redes neurais com grandes conjuntos de dados rotulados caros e demorados para produzir. Ao encontrar padrões entre elementos matematicamente, os transformers eliminam essa necessidade, disponibilizando os trilhões de imagens e petabytes de dados de texto na web e em bancos de dados corporativos.
Além disso, a matemática que os transformers usam pode ser usada também no processamento paralelo para que esses modelos sejam executados rapidamente.
Os transformers agora dominam as tabelas de líderes de desempenho populares, como o SuperGLUE, um benchmark desenvolvido em 2019 para sistemas de processamento de linguagem.
Como os Transformers Prestam Atenção
Como a maioria das redes neurais, os modelos transformer são basicamente grandes blocos de codificador/decodificador que processam dados.
Pequenas, mas estratégicas adições a esses blocos (mostradas no diagrama abaixo) tornam os transformers extremamente potentes.
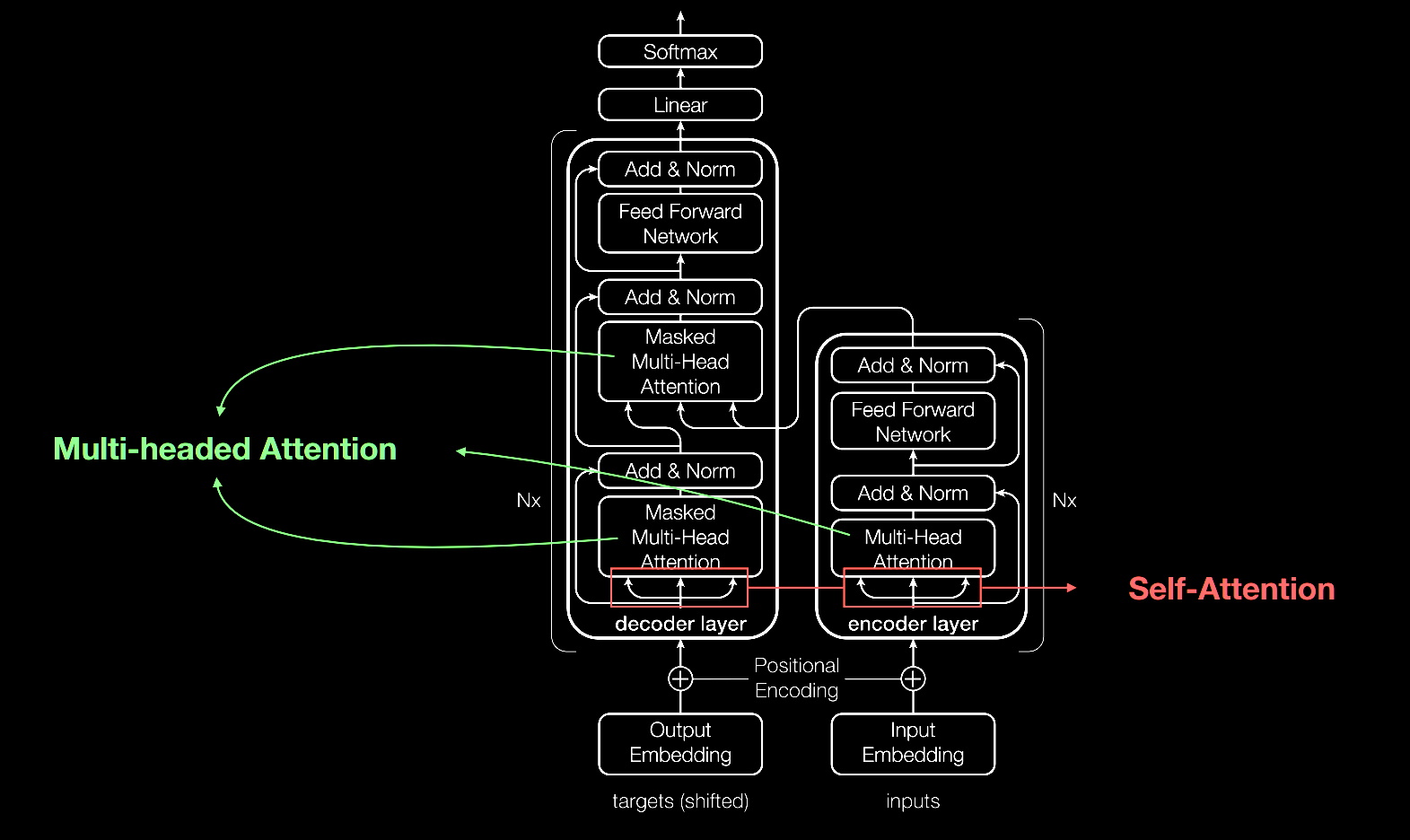
Os transformers usam codificadores posicionais para marcar elementos de dados que entram e saem da rede. As unidades de atenção seguem essas marcações, calculando uma espécie de mapa de álgebra de como cada elemento se relaciona com os outros.
As consultas de atenção costumam ser executadas paralelamente, calculando uma matriz de equações no que é chamado de atenção multi-head.
Com essas ferramentas, os computadores podem ver os mesmos padrões que os humanos veem.
A Autoatenção Encontra Significado
Por exemplo, na frase:
Ela derramou água da jarra para o copo até que ficasse cheio.
Sabemos que “cheio” se refere ao copo, enquanto na frase:
Ela derramou água da jarra para o copo até que ficasse vazia.
Sabemos que “vazia” se refere à jarra.
“O significado é o resultado de relações entre as coisas, e a autoatenção é uma maneira geral de aprender relações”, disse Ashish Vaswani, ex-Cientista Sênior de Pesquisa da equipe do Google Brain, que liderou o trabalho no artigo seminal de 2017.
“A tradução automática foi um bom veículo para validar a autoatenção porque você precisava de relações de curta e longa distância entre as palavras”, disse Vaswani.
“Agora vemos que a autoatenção é uma ferramenta poderosa e flexível para o aprendizado”, acrescentou.
Como os Transformers Receberam Seu Nome
Atenção é tão fundamental para os transformers que os pesquisadores do Google quase usaram o termo como nome para o modelo de 2017. Quase.
“O nome ‘Attention Net’ não soava muito empolgante”, disse Vaswani, que começou a trabalhar com redes neurais em 2011.
Jakob Uszkoreit, Engenheiro de Software Sênior da equipe, foi quem criou o nome Transformer.
“Eu falei que estávamos transformando representações, mas isso era só uma questão semântica”, disse Vaswani.
O Nascimento dos Transformers
No artigo da conferência NeurIPS de 2017, a equipe do Google descreveu seu transformer e os registros de precisão que ele estabeleceu para tradução automática.
Graças a um grupo de técnicas, eles treinaram seu modelo em apenas três dias e meio em oito GPUs NVIDIA, uma pequena fração do tempo e do custo do treinamento de modelos anteriores. Eles o treinaram em conjuntos de dados com até um bilhão de pares de palavras.
“Foi uma corrida intensa de três meses até a data de envio do artigo”, lembrou Aidan Gomez, estagiário do Google em 2017 que contribuiu para o trabalho.
“Na noite em que estávamos enviando, Ashish e eu ficamos uma noite toda no Google”, disse ele. “Consegui algumas horas de sono em uma das pequenas salas de conferência e acordei bem a tempo do envio, quando alguém que estava chegando cedo para trabalhar abriu a porta e bateu na minha cabeça.”
Acordei em mais de um sentido.
“Ashish me disse naquela noite que estava convencido de que isso seria grande, algo que mudaria o jogo. Eu não estava convencido, pensei que seria um ganho modesto em um benchmark, mas no fim ele estava muito certo”, disse Gomez, agora CEO da startup Cohere, que oferece um serviço de processamento de linguagem baseado em transformers.
Um Momento para o Machine Learning
Vaswani lembra da empolgação de ver os resultados superarem o trabalho semelhante publicado por uma equipe do Facebook usando CNNs.
“Eu acreditava que esse provavelmente seria um momento importante no machine learning”, disse ele.
Um ano depois, outra equipe do Google tentou processar sequências de textos para frente e para trás com um transformer. Isso ajudou a capturar mais relações entre as palavras, melhorando a capacidade do modelo de entender o significado de uma frase.
O modelo Bidirectional Encoder Representations from Transformers (BERT) estabeleceu 11 novos recordes e se tornou parte do algoritmo por trás da pesquisa do Google.
Em poucas semanas, pesquisadores de todo o mundo adaptaram o BERT para casos de uso em muitos idiomas e setores “porque o texto é um dos tipos de dados mais comuns que as empresas têm”, disse Anders Arpteg, um veterano de 20 anos na pesquisa em machine learning.
Colocando os Transformers para Trabalhar
Logo os modelos transformer estavam sendo adaptados para a ciência e a área da saúde.
A DeepMind, em Londres, avançou o entendimento das proteínas, os blocos de construção da vida, usando um transformer chamado AlphaFold2, descrito em um artigo recente da Nature. Ele processou cadeias de aminoácidos como cadeias de texto para definir uma nova marca para descrever como as proteínas se dobram, um trabalho que poderia acelerar a descoberta de medicamentos.
A AstraZeneca e a NVIDIA desenvolveram o MegaMolBART, um transformer adaptado para a descoberta de medicamentos. É uma versão do transformer MolBART da empresa farmacêutica, treinado em um banco de dados grande e não rotulado de compostos químicos usando o framework NVIDIA Megatron para a criação de modelos transformer de grande escala.
Leitura de Moléculas e Registros Médicos
“Assim como modelos de linguagem de AI podem aprender as relações entre palavras em uma frase, nosso objetivo é que as redes neurais treinadas com dados de estrutura molecular possam aprender as relações entre átomos em moléculas do mundo real”, disse Ola Engkvist, Chefe de AI Molecular, Ciências de Descoberta e P&D, AstraZeneca, quando o trabalho foi anunciado no ano passado.
Separadamente, o centro de saúde acadêmica da Universidade da Flórida colaborou com pesquisadores da NVIDIA para criar o GatorTron. Esse modelo transformer tem como objetivo extrair informações de volumes enormes de dados clínicos para acelerar pesquisas médicas.
Os Transformers Crescem
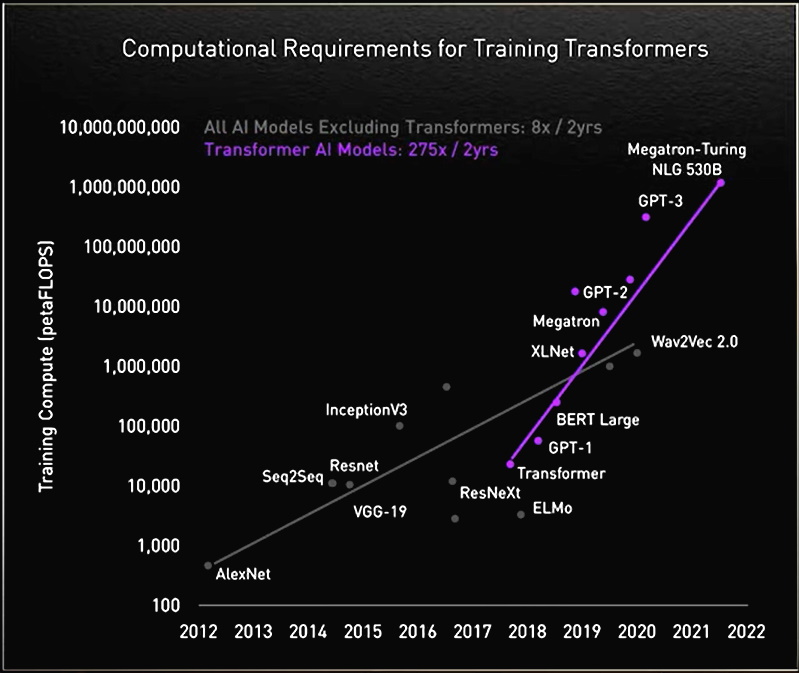
Ao longo do caminho, os pesquisadores descobriram que transformers maiores tinham melhor desempenho.
Por exemplo, pesquisadores do Rostlab da Universidade Técnica de Munique, que ajudaram a inovar o trabalho na interseção da AI e da biologia, usaram o processamento de linguagem natural para entender as proteínas. Em 18 meses, eles foram do uso de RNNs com 90 milhões de parâmetros para o uso de modelos de transformer com 567 milhões de parâmetros.
O laboratório OpenAI mostrou que maior é melhor com seu Generative Pretrained Transformer (GPT). A versão mais atual, GPT-3, tem 175 bilhões de parâmetros, contra 1,5 bilhão do GPT-2.
Com essa capacidade adicional, o GPT-3 pode responder à consulta de um usuário mesmo em tarefas em que não foi especificamente treinado. Ele já está sendo usado por empresas como Cisco, IBM e Salesforce.
A História de um Megatransformer
A NVIDIA e a Microsoft atingiram uma importante marca em novembro, anunciando o modelo Megatron-Turing Natural Language Generation (MT-NLG) com 530 bilhões de parâmetros. Ele foi lançado juntamente com um novo framework, o NVIDIA NeMo Megatron, que tem como objetivo permitir que qualquer empresa crie seus próprios transformers de bilhões ou trilhões de parâmetros para alimentar chatbots personalizados, assistentes pessoais e outras aplicações de AI que entendem a linguagem.
O MT-NLG teve sua estreia pública como o cérebro de TJ, o avatar de Toy Jensen que participou da apresentação no GTC de novembro de 2021 da NVIDIA.
“Foi empolgante ver o TJ responder a perguntas, o poder do nosso trabalho demonstrado pelo nosso CEO”, disse Mostofa Patwary, que liderou a equipe da NVIDIA que treinou o modelo.

Criar esses modelos não é para os fracos. O MT-NLG foi treinado usando centenas de bilhões de elementos de dados, um processo que exigiu que milhares de GPUs funcionassem por semanas.
“O treinamento de grandes modelos transformer é caro e demorado. Por isso, se você não conseguir na primeira ou segunda vez, os projetos poderão ser cancelados”, afirmou Patwary.
Transformers de Trilhões de Parâmetros
Hoje, muitos engenheiros de AI estão trabalhando em transformers e aplicações com trilhões de parâmetros para eles.
“Estamos sempre explorando como esses modelos grandes podem oferecer aplicações melhores. Também investigamos em que aspectos eles falham, para que possamos construir modelos ainda melhores e maiores”, disse Patwary.
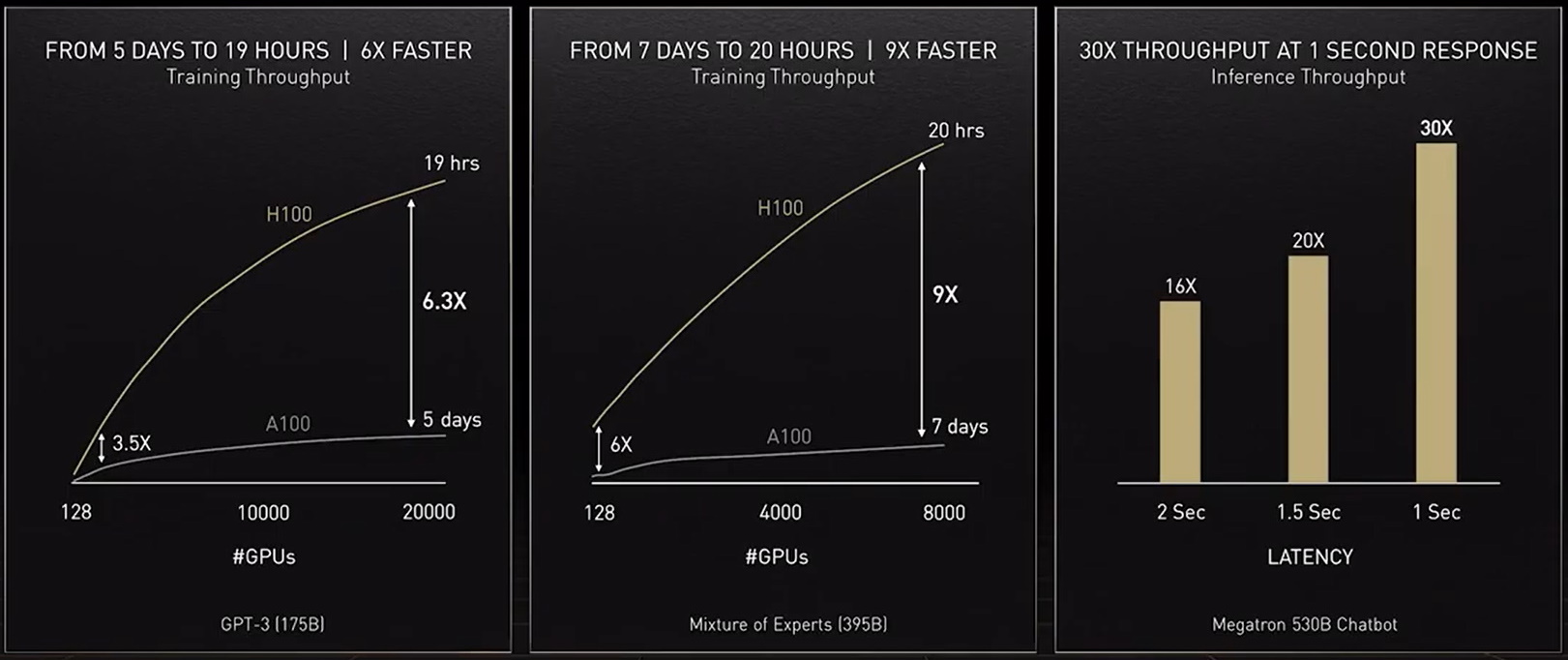
Para oferecer a potência computacional de que esses modelos precisam, nosso mais atual acelerador, a GPU NVIDIA H100 Tensor Core, tem um engine Transformer e é compatível com um novo formato FP8. Isso acelera o treinamento e preserva a precisão.
Com esses e outros avanços, “o treinamento de modelos transformer pode ser reduzido de semanas para dias”, afirmou Huang no GTC.
MoE Significa Mais para os Transformers
No ano passado, pesquisadores do Google descreveram o Switch Transformer, um dos primeiros modelos de trilhões de parâmetros. Ele usa a dispersão de AI, uma complexa arquitetura de mistura de especialistas (MoE – Mixture-of Experts) e outros avanços para impulsionar ganhos de desempenho no processamento de linguagem e aumentos de até 7 vezes na velocidade de pré-treinamento.
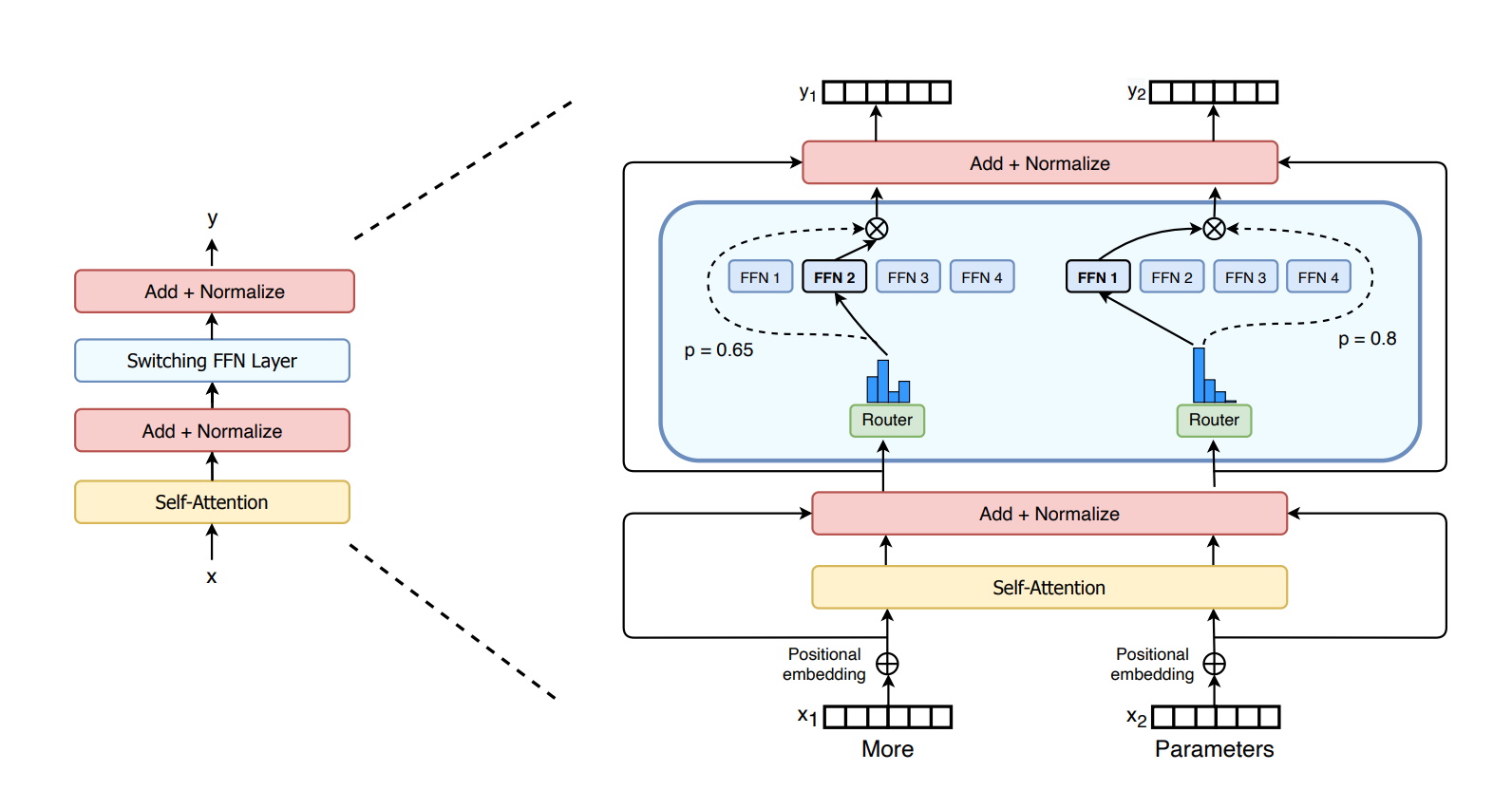
Por sua vez, a Microsoft Azure trabalhou com a NVIDIA para implementar um transformer MoE para seu serviço Translator.
Enfrentando os Desafios dos Transformers
Agora, alguns pesquisadores querem desenvolver transformers mais simples com menos parâmetros que ofereçam desempenho semelhante aos maiores modelos.
“Eu vejo potencial nos modelos baseados em recuperação, e estou muito animado porque eles podem ir além”, disse Gomez, da Cohere, observando o modelo retrô do DeepMind como exemplo.
Modelos baseados em recuperação aprendem enviando consultas a um banco de dados. “É legal porque você pode ser exigente sobre o que você coloca nessa base de conhecimento”, disse ele.
O objetivo final é “fazer com que esses modelos aprendam como humanos a partir do contexto no mundo real com muito poucos dados”, disse Vaswani, agora cofundador de uma startup de AI esquiva.
Ele imagina modelos futuros fazendo mais computação antecipadamente e, assim, precisando de menos dados e apresentando maneiras melhores de os usuários oferecerem feedback.
“Nosso objetivo é construir modelos que ajudem as pessoas no dia a dia”, disse ele sobre seu novo empreendimento.
Modelos Seguros e Responsáveis
Outros pesquisadores estão estudando maneiras de eliminar tendências ou toxicidade se os modelos amplificam linguagem errada ou nociva. Stanford, por exemplo, criou o Center for Research on Foundation Models para explorar essas questões.
“São problemas importantes que precisam ser resolvidos para uma implantação segura de modelos”, disse Shrimai Prabhumoye, Cientista Pesquisador, NVIDIA, e um dos muitos profissionais do setor que trabalham na área.
“Hoje, a maioria dos modelos procura certas palavras ou frases, mas na vida real essas questões podem sair sutilmente, então temos que considerar todo o contexto”, acrescentou Prabhumoye.
“Essa é uma preocupação primária para Cohere, também”, disse Gomez. “Ninguém usará esses modelos se forem prejudiciais às pessoas, então é um desafio tornar os modelos mais seguros e responsáveis.”
Além do Horizonte
Vaswani imagina um futuro em que transformers de autoaprendizagem e com atenção se aproximam do Santo Graal da AI.
“Temos a chance de alcançar alguns dos objetivos que as pessoas falaram quando cunharam o termo ‘inteligência artificial geral’ e acho essa meta muito inspiradora”, disse ele.
“Estamos em um momento em que métodos simples como redes neurais estão nos dando uma explosão de novos recursos.”