
Os dados são o petróleo da era atual da AI, mas poucos têm a sorte de encontrar um poço para explorar. Por isso, muitos estão criando seu próprio combustível para ter uma opção que seja barata e eficaz ao mesmo tempo. São os dados sintéticos.
O que São Dados Sintéticos?
Os dados sintéticos são informações comentadas que simulações ou algoritmos de computador geram como uma alternativa aos dados reais.
Em outras palavras, os dados sintéticos são criados em mundos digitais em vez de coletados ou medidos no mundo real.
Elas podem ser artificiais, mas refletem os dados reais, tanto matemática quanto estatisticamente. Pesquisas mostram que eles são tão eficientes ou até melhores para treinar um modelo de AI do que dados baseados em objetos, eventos ou pessoas reais.

É por isso que desenvolvedores de redes neurais profundas usam cada vez mais dados sintéticos para treinar seus modelos. Na verdade, uma pesquisa de 2019 na área chama o uso de dados sintéticos de “uma das técnicas gerais mais promissoras em ascensão no deep learning moderno, principalmente a visão computacional”, que se baseia em dados não estruturados, como imagens e vídeos.
O relatório de 156 páginas de Sergey I. Nikolenko do Instituto de Matemática Steklov em São Petersburgo, na Rússia, cita 719 artigos sobre dados sintéticos. Nikolenko conclui que “os dados sintéticos são essenciais para o desenvolvimento do deep learning, e ainda há muitos outros possíveis casos de uso” para descobrir.
Além de os dados sintéticos estarem crescendo, o pioneiro da AI Andrew Ng reforça que é preciso adotar uma abordagem de machine learning mais centrada nos dados. Ele está pedindo apoio para criar um benchmark ou uma competição referente à qualidade dos dados, que muitos afirmam que representa 80% das tarefas de AI.
“A maioria dos benchmarks apresenta um conjunto fixo de dados, e são os pesquisadores que precisam fazer iterações no código. Talvez esteja na hora de manter o código fixo e pedir que os pesquisadores aprimorem os dados”, ele escreveu no jornal The Batch.
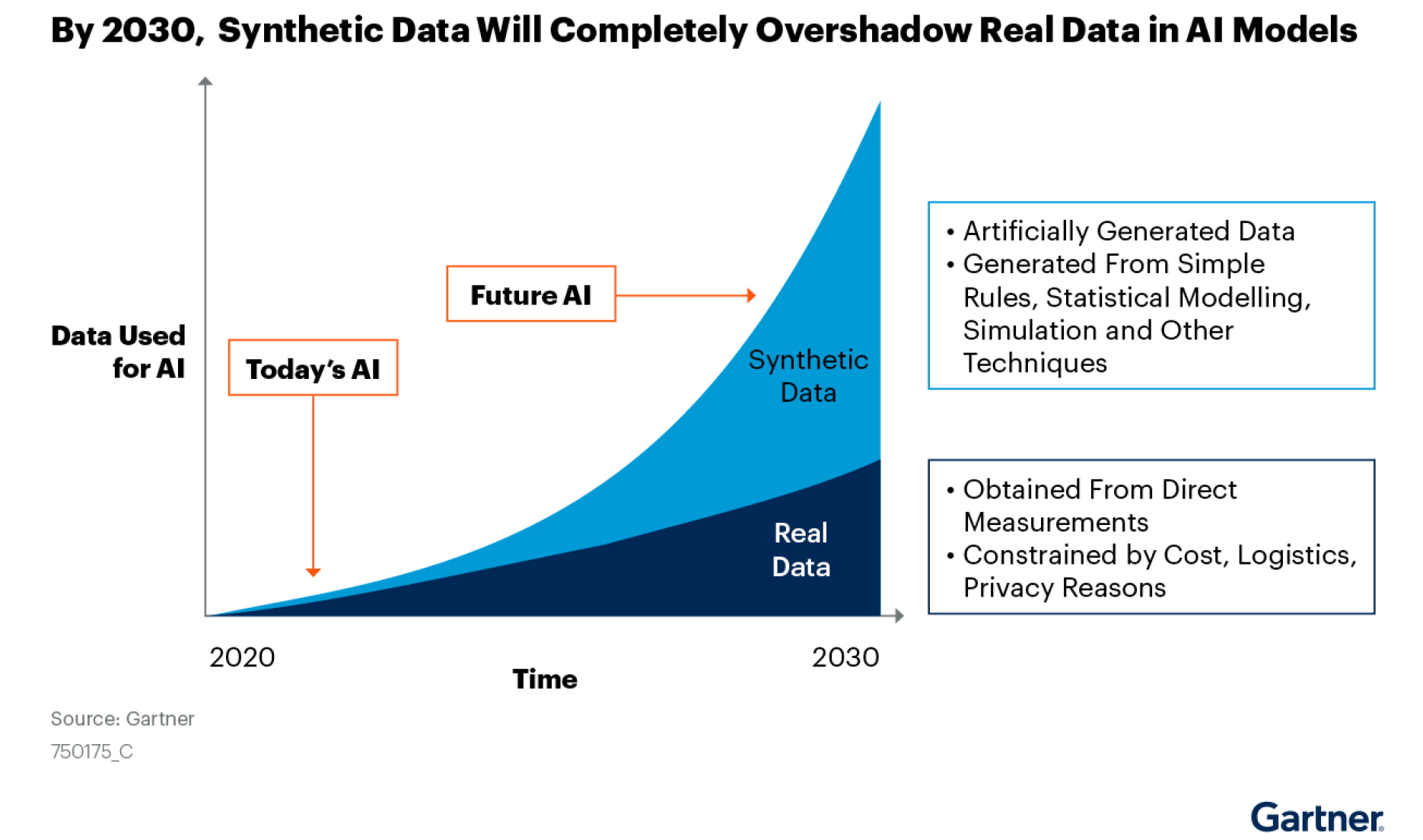
Em um relatório de junho de 2021 sobre dados sintéticos, a Gartner previu que até 2030 a maioria dos dados usados em AI serão gerados artificialmente por regras, modelos estatísticos, simulações ou outras técnicas.
“O fato é que você não será capaz de construir modelos de AI de alta qualidade e alto valor sem dados sintéticos”, disse o relatório.
Dados Aumentados e Anonimizados em Vez de Sintéticos
A maioria dos desenvolvedores já conhece o aumento de dados, uma técnica que consiste na adição de novos dados a um conjunto existente de dados reais. Eles podem, por exemplo, girar ou clarear uma imagem existente para criar outra.
Devido às preocupações e políticas governamentais sobre a privacidade, a remoção de informações pessoais de um conjunto de dados é uma prática cada vez mais comum. É o que se chama de anonimização de dados, e ela é comum principalmente em textos, uma espécie de dado estruturado usada na área da saúde e nos serviços financeiros.
Os dados aumentados e anonimizados geralmente não são considerados dados sintéticos. No entanto, é possível criar dados sintéticos usando essas técnicas. Os desenvolvedores pode, por exemplo, unir duas imagens de carros reais para criar uma imagem sintética com dois carros.
Por que os Dados Sintéticos São Tão Importantes?
Os desenvolvedores precisam de conjuntos de dados grandes e cuidadosamente identificados para treinar redes neurais. A diversificação dos dados de treinamento geralmente aumenta a precisão dos modelos de AI.
O problema é que reunir e identificar conjuntos de dados que podem conter de milhares a dezenas de milhões de elementos é uma tarefa demorada e muitas vezes extremamente cara.
É aí que entram os dados sintéticos. Uma única imagem que pode custar US$6 de um serviço de identificação pode ser gerada artificialmente por US$0,06, estima Paul Walborsky, um dos cofundadores dos primeiros serviços dedicados a dados sintéticos, o AI.Reverie.
A redução de custos é só o começo. “Os dados sintéticos são fundamentais para lidar com as questões de privacidade e reduzir a parcialidade, garantindo a diversidade de dados para representar o mundo real”, acrescentou Walborsky.
Como os conjuntos de dados sintéticos são identificados automaticamente e podem conter casos extremos raros, mas cruciais, se for o desejado, às vezes eles são melhores do que os dados reais.
Qual é a História dos Dados Sintéticos?
Os dados sintéticos existem há décadas, mas de formas diferentes. Eles estão nos games de computador, como simuladores de voo, e em simulações científicas de todos os tipos, dos átomos às galáxias.
Donald B. Rubin, Professor de Estatística de Harvard, estava ajudando setores do governo dos EUA a resolver questões como um número muito pequeno de pessoas pobres em um censo quando teve uma ideia. Ele a apresentou em um artigo de 1993 que geralmente é considerado o nascimento dos dados sintéticos.
“Usei o termo dados sintéticos no artigo para me referir a vários conjuntos de dados simulados.
Cada um parece ter sido criado pelo mesmo processo que criou o conjunto de dados reais, mas nenhum revela esses dados. Isso é muito vantajoso para estudar conjuntos de dados pessoais e confidenciais”, explicou Rubin.

Com o Big Bang da AI, quando uma rede neural reconheceu objetos mais rápido que um humano na competição ImageNet de 2012, os pesquisadores começaram a levar a sério a procura por dados sintéticos.
Poucos anos depois, “os pesquisadores já estavam usando imagens renderizadas em experimentos, e estava valendo tanto a pena que as pessoas começaram a investir em produtos e ferramentas para gerar dados com mecanismos 3D e pipelines de conteúdo”, afirmou Gavriel State, Diretor Sênior de Tecnologia de Simulação e AI da NVIDIA.
Ford e BMW Geram Dados Sintéticos
Atualmente, bancos, montadoras, drones, fábricas, hospitais, varejistas, robôs e cientistas usam dados sintéticos.
Em um podcast recente, pesquisadores da Ford explicaram como combinam engines de games e redes generativas adversariais (GANs – Generative Adversarial Networks) para criar dados sintéticos para o treinamento de AI.
Para otimizar o processo de fabricação de carros, a BMW criou uma fábrica virtual com o NVIDIA Omniverse, uma plataforma de simulação que permite que as empresas colaborem usando várias ferramentas. Os dados que a BMW gera ajudam a alinhar a colaboração entre funcionários e robôs de montagem na produção eficiente de carros.
Dados Sintéticos nos Hospitais, Bancos e Lojas
Os profissionais da saúde de áreas como diagnósticos por imagens usam dados sintéticos para treinar modelos de AI, protegendo a privacidade dos pacientes. A startup Curai, por exemplo, treinou um modelo de diagnóstico com 400 mil casos médicos simulados.
“As arquiteturas baseadas em GANs para diagnósticos por imagens, que geram dados sintéticos ou adaptam dados reais de outros domínios, definirão o estado da arte na área nos próximos anos”, afirmou Nikolenko em sua pesquisa de 2019.
As GANs também estão ganhando força nos serviços financeiros. A American Express investigou formas de usar GANs para criar dados sintéticos, refinando seus modelos de AI que detectam fraudes.
No varejo, empresas como a startup Caper usam simulações 3D para capturar apenas cinco imagens de um produto e criar um conjunto de dados sintéticos de mil imagens. Esses conjuntos de dados possibilitam a criação de lojas inteligentes onde os clientes pegam o que precisam e pagam sem precisar esperar na fila do caixa.
Como Se Criam Dados Sintéticos?
“Há milhões de técnicas” para gerar dados sintéticos, declarou State da NVIDIA. Os autocodificadores de variação, por exemplo, compactam um conjunto de dados para reduzi-lo e usam um decodificador para gerar um conjunto de dados sintético relacionado.
Embora as GANs estejam em evolução, principalmente nas pesquisas, as simulações continuam sendo uma opção comum por dois motivos. Elas podem ser usadas com uma série de ferramentas para segmentar e classificar imagens estáticas e dinâmicas, proporcionando a identificação perfeita. Elas também podem gerar versões de objetos e ambientes rapidamente com diferentes cores, iluminação, materiais e poses.
Essa capacidade oferece os dados sintéticos que são fundamentais para a randomização de domínio, uma técnica cada vez mais usada para aumentar a precisão dos modelos de AI.
Dica Profissional: Use a Randomização de Domínio
A randomização de domínio usa milhares de variações de um objeto e seu ambiente para que um modelo de AI possa identificar o padrão geral com mais facilidade. O vídeo abaixo mostra como um armazém inteligente usa a randomização de domínio para treinar um robô com tecnologia fornecida por AI.
A randomização de domínio contribui para que os modelos de AI façam as previsões perfeitas que fariam se fossem treinados na situação exata da realidade. É por isso que a NVIDIA está desenvolvendo uma randomização de domínio para ferramentas de geração de dados sintéticos no Omniverse, e uma parte do trabalho é descrita em uma palestra recente no GTC.
Essas técnicas ajudam as aplicações de visão computacional a ir além da detecção e da classificação de objetos em imagens: elas passam a observar e assimilar atividades em vídeos.
“O mercado está seguindo essa direção, mas a tecnologia é mais complexa. Os dados sintéticos são ainda mais valiosos nesse caso, porque permitem criar frames de vídeo repletos de comentários”, contou Walborsky, da AI.Reverie.
Onde Posso Obter Dados Sintéticos?
Embora o setor exista há poucos anos, mais de 50 empresas já disponibilizam dados sintéticos. Cada uma tem um toque especial, geralmente com foco em um determinado mercado vertical ou técnica.
Algumas, por exemplo, são especializadas em usos na área da saúde. Seis dessas empresas oferecem ferramentas ou conjuntos de dados livres, como o Synthetic Data Vault, um conjunto de bibliotecas, projetos e tutoriais desenvolvidos no MIT.
A NVIDIA tem como objetivo trabalhar com vários serviços de dados sintéticos e identificação de dados. Estes são alguns dos parceiros mais atuais:
- A AI.Reverie fica em Nova York e oferece ambientes de simulação com sensores configuráveis que permitem que os usuários coletem seus próprios conjuntos de dados. A empresa também participa de projetos de grande escala em áreas como agricultura, cidades inteligentes, segurança e manufatura.
- A Sky Engine, com sede em Londres, desenvolve aplicações de visão computacional de todos os mercados e pode ajudar os usuários a projetar seu próprio workflow de ciência de dados.
- A Datagen, sediada em Israel, cria conjuntos de dados sintéticos a partir de simulações para diversos mercados, como lojas inteligentes, robótica e interiores para carros e edifícios.
- A CVEDIA tem como clientes a Airbus, a Honeywell e a Siemens, que usam as ferramentas personalizáveis baseadas em dados sintéticos da empresa para visão computacional.
Criando um Mercado com o Omniverse
Com o Omniverse, a NVIDIA pretende contribuir para o aumento do número de designers e programadores de todos os setores que têm interesse em criar ou colaborar em mundos virtuais. A geração de dados sintéticos é um dos muitos serviços que a empresa espera hospedar na plataforma.
A NVIDIA criou o Isaac Sim como uma aplicação para robótica no Omniverse. Nesse mundo virtual, os usuários podem treinar robôs com dados sintéticos e randomização de domínio, além de implantar o software criado em robôs que funcionam no mundo real.
O Omniverse é compatível com várias aplicações para mercados verticais, como o NVIDIA DRIVE Sim para automóveis autônomos. Ele permite que os desenvolvedores testem carros autônomos na segurança de uma simulação realista, gerando conjuntos de dados úteis até mesmo no meio da pandemia.
Essas aplicações estão entre os exemplos mais atuais que mostram como as simulações cumprem a promessa dos dados sintéticos para a AI.
Saiba Mais Sobre Dados Sintéticos
Para obter mais informações sobre dados sintéticos, confira estes recursos:
- Um eBook de O’Reilly e da NVIDIA sobre o uso de dados sintéticos na AI
- Uma palestra sobre dados sintéticos no GTC 2019 apresentada por Rev Lebaredian, vice-presidente de tecnologia de simulação da NVIDIA (inscrição gratuita obrigatória)
- Quatro posts sobre dados sintéticos do blog para desenvolvedores da NVIDIA publicados em 2021
- Uma apresentação do Scotiabank e da Universidade de Alberta no GTC 2021 sobre pesquisas que usam modelos generativos para criar dados sintéticos (inscrição gratuita necessária)
- Exemplos de código para a geração de dados sintéticos no Omniverse