Quando solicitamos que a IA generativa responda a uma pergunta ou crie uma imagem, grandes modelos de linguagem geram tokens de inteligência que se combinam para fornecer o resultado.
Um prompt. Um conjunto de tokens para a resposta. Isso é chamado de inferência de IA
A IA baseada em agentes usa o raciocínio para concluir tarefas. Os agentes de IA não estão apenas fornecendo respostas únicas. Eles dividem as tarefas em uma série de etapas, cada uma com uma técnica de inferência diferente.
Um prompt. Muitos conjuntos de tokens para concluir o trabalho
Os mecanismos de inferência de IA são chamados de fábricas de IA: infraestruturas massivas que fornecem IA a milhões de usuários ao mesmo tempo.
As fábricas de IA geram tokens de IA. Seu produto é inteligência. Na era da IA, essa inteligência aumenta a receita e os lucros. O aumento da receita ao longo do tempo depende de quão eficiente a fábrica de IA pode ser à medida que cresce.
As fábricas de IA são as máquinas da próxima revolução industrial.

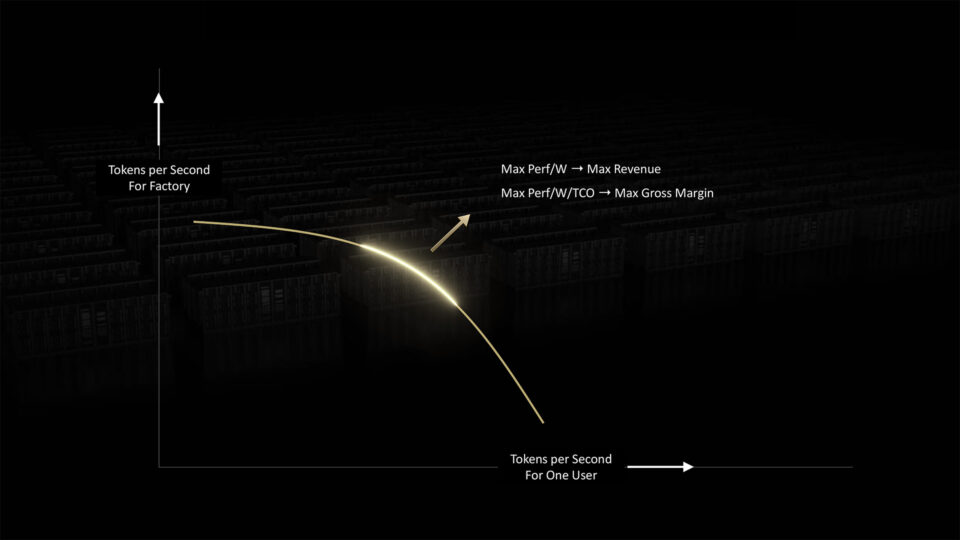
As fábricas de IA precisam equilibrar duas demandas concorrentes para fornecer inferência ideal: velocidade por usuário e taxa de transferência geral do sistema.

As fábricas de IA podem melhorar ambos os fatores escalando para mais FLOPS e maior largura de banda. Eles podem agrupar e processar cargas de trabalho de IA para maximizar a produtividade.
Mas, em última análise, as fábricas de IA são limitadas pelo poder que podem acessar.
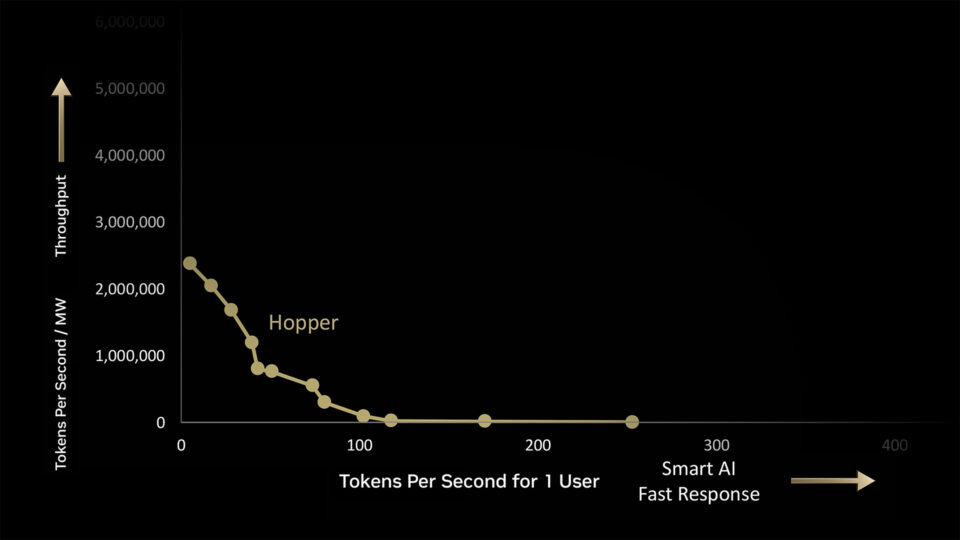
Em uma fábrica de IA de 1 megawatt, o NVIDIA Hopper gera 180.000 tokens por segundo (TPS) no volume máximo ou 225 TPS para um usuário no mais rápido.
Mas o verdadeiro trabalho acontece no espaço intermediário. Cada ponto ao longo da curva representa lotes de cargas de trabalho para a fábrica de IA processar, cada uma com sua própria combinação de demandas de desempenho.
As GPUs NVIDIA têm a flexibilidade de lidar com todo esse espectro de cargas de trabalho porque podem ser programadas usando o software NVIDIA CUDA.
A arquitetura NVIDIA Blackwell pode fazer muito mais com 1 megawatt do que a arquitetura Hopper, e há mais por vir. Otimizar os stacks de software e hardware significa que a Blackwell se torna mais rápida e eficiente ao longo do tempo.
A Blackwell recebe outro impulso quando os desenvolvedores otimizam as cargas de trabalho da fábrica de IA de forma autônoma com o NVIDIA Dynamo, o novo sistema operacional para fábricas de IA.
O Dynamo divide as tarefas de inferência em componentes menores, roteando e redirecionando dinamicamente as cargas de trabalho para os recursos de computação mais ideais disponíveis naquele momento.
As melhorias são notáveis. Em um único salto geracional da arquitetura do processador de Hopper para Blackwell, podemos alcançar uma melhoria de 50 vezes no desempenho do raciocínio de IA usando a mesma quantidade de energia.
É assim que a integração full-stack da NVIDIA e o software avançado oferecem aos clientes grandes aumentos de velocidade e eficiência no tempo entre as gerações da arquitetura do chip.
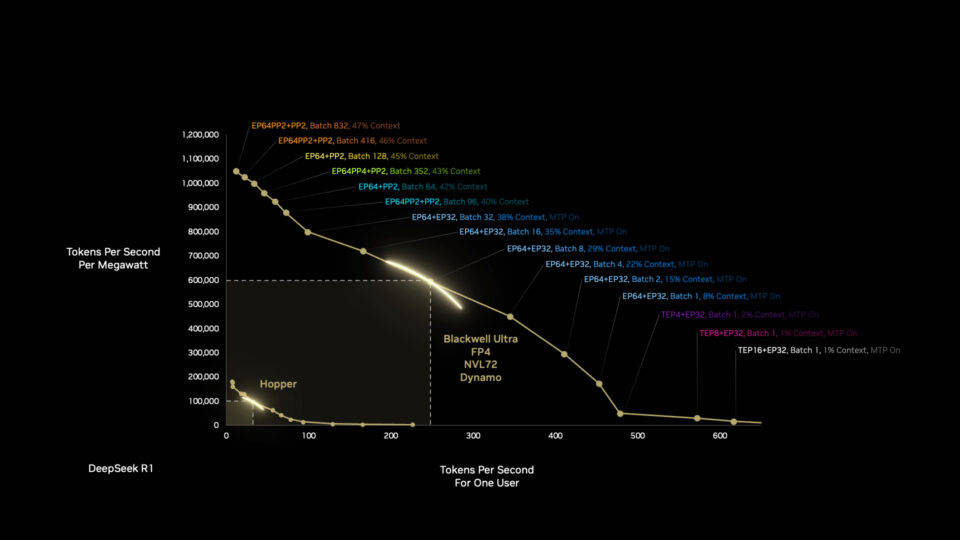
Empurramos essa curva para fora a cada geração, do hardware ao software, da computação à rede.
E a cada avanço no desempenho, a IA pode criar trilhões de dólares em produtividade para os parceiros e clientes da NVIDIA em todo o mundo, ao mesmo tempo em que nos deixa um passo mais perto de curar doenças, reverter as mudanças climáticas e descobrir alguns dos maiores segredos do universo.
Isso é computação se transformando em capital e progresso.