A simulação de reservatórios ajuda os engenheiros de reservatórios a otimizar a exploração de recursos naturais, simulando cenários complexos e comparando com dados de campo. Isso se estende à simulação de reservatórios exauridos que poderiam ser reaproveitados para armazenamento de carbono. A simulação de reservatórios é crucial para empresas de energia que buscam aumentar a eficiência operacional na exploração e produção.
Este post demonstra como a CPU NVIDIA Grace se destaca na resolução de sistemas lineares dentro do workflow da Petrobras, alcançando um tempo de solução até 4,5 vezes mais rápido, eficiência energética 4,3 vezes maior e escalabilidade 1,5 vezes maior em comparação com CPUs baseadas em x86.
A Petrobras é uma empresa brasileira líder em energia, em transição para novas fontes de energia mantendo seu negócio principal de exploração e produção de petróleo e gás (O&G). De acordo com as listas Top500 e Green500, a Petrobras possui a maior infraestrutura de HPC da América Latina, impulsionada pela plataforma de computação acelerada full-stack da NVIDIA. Suas principais cargas de trabalho são o processamento sísmico e simulação de reservatórios.
A empresa foi pioneira na exploração em águas ultraprofundas, com operações que atingem profundidades de até 7 km. Com uma única perfuração de poço custando até US$ 100 milhões, a computação de alto desempenho (HPC) ajuda a reduzir a incerteza da exploração de recursos e melhorar as taxas de sucesso da produção.
Simulação de Reservatórios e o Projeto SolverBR
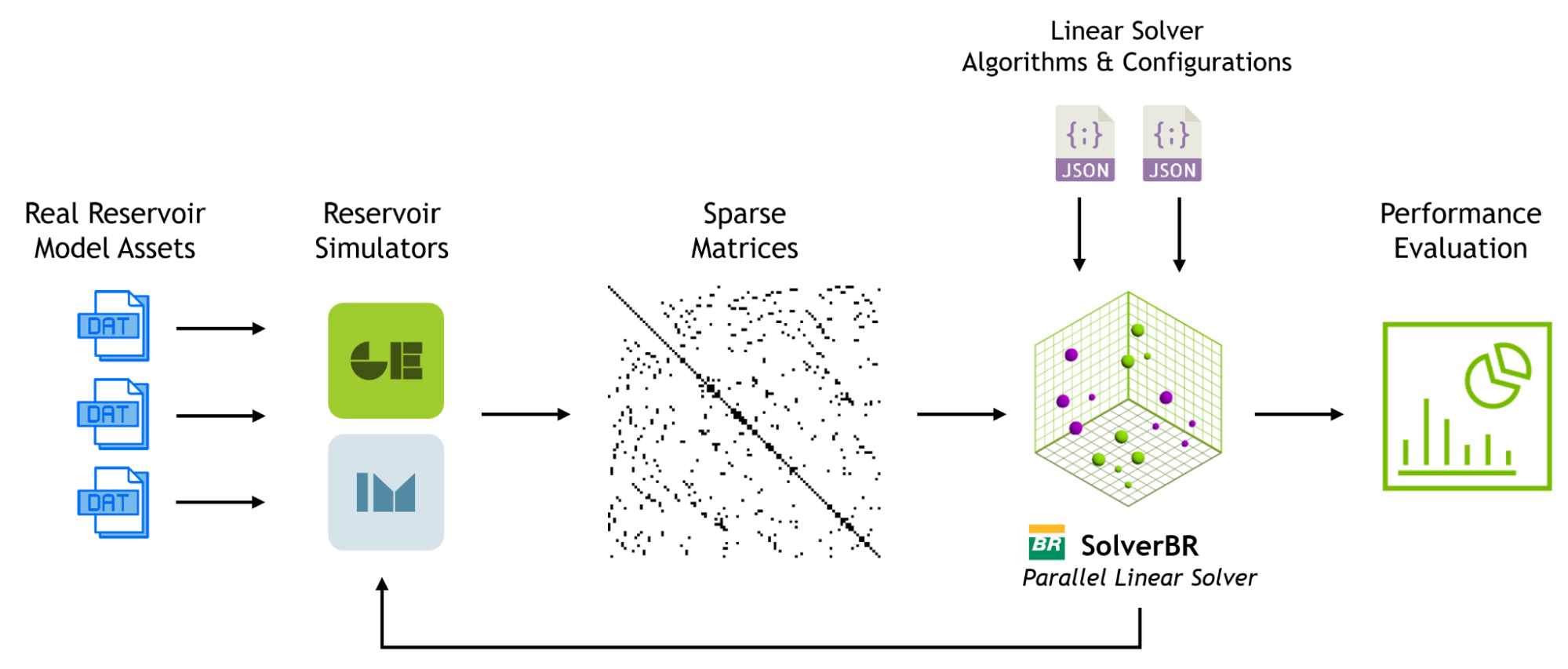
A resolução de sistemas lineares é a tarefa mais demorada em simulações de reservatórios (Figura 1). Esse processo pode representar até 70% do tempo computacional total dentro do pipeline de simulação da Petrobras. Portanto, otimizar solucionadores lineares esparsos mantendo alta precisão é crucial para estudos confiáveis de reservatórios.
A Petrobras colaborou com a UFRJ e outros institutos de pesquisa e inovação no Brasil para desenvolver o SolverBR, um solucionador de equações lineares baseado em CPU que usa novas técnicas de paralelização computacional com uma implementação multicore eficiente. O SolverBR é integrado a simuladores de fluxo geomecânicos e de terceiros, incluindo o Computer Modelling Group (CMG) IMEX e GEM, amplamente utilizados para simulação composicional de reservas do pré-sal.
Portabilidade do SolverBR de x86 para o Arm
Processadores baseados em Arm, como a CPU NVIDIA Grace, estão ganhando força em soluções de HPC, inclusive no setor de energia. A Petrobras, a NVIDIA e o Centro de Inovação CESAR estão fazendo uma parceria para portar e comparar o SolverBR com a CPU NVIDIA Grace em uma iniciativa para medir os principais benefícios das CPUs baseadas em Arm.
A CPU NVIDIA Grace possui Arm Neoverse V2 de 72 núcleos, conectada por uma malha de coerência escalável NVIDIA de alta largura de banda, com alta largura de banda e baixa potência de memória LPDDR5X.
Os resultados iniciais demonstraram que a NVIDIA Grace oferece as melhores taxas de desempenho da categoria em tempo de solução (TTS) e energia estimada para solução (ETS), em comparação com os principais processadores baseados em x86 disponíveis em infraestruturas on-premises e na nuvem.
O projeto se concentra na manutenção de um sistema de compilação multiplataforma, permitindo que uma única base de código e scripts de compilação funcionem perfeitamente em várias plataformas. Isso garante testes consistentes e comparações de desempenho confiáveis ao portar a base de códigos x86 para o Arm com o mínimo de esforço necessário. O robusto ecossistema Arm, com compiladores e depuradores de código aberto facilitaram significativamente essa transição.
O GCC 12.3 foi escolhido como compilador de teste devido ao seu excelente desempenho. O GCC 12.3 ou superior é recomendado devido ao seu suporte a otimizações automáticas para os cores Arm Neoverse V2. O processo de portabilidade para o Arm envolveu as seguintes etapas:
- Remoção de todas as flags específicas da arquitetura x86, como -maxv, -march e -mtune, que têm significados diferentes no Arm.
- Use o nível de otimização -O3 para acionar otimizações automáticas, como function inlining, vetorização, desenrolamento de loop, intercharge e fusão. Para obter ainda mais desempenho, considere utilizar a flag -Ofast.
- Acrescente o -mcpu=native ao CFLAGS para garantir que o compilador detecte automaticamente a CPU do sistema de compilação.
- Por fim, use -flto como um sinalizador opcional para otimização de tempo de linkagem. Dependendo da aplicação, -fsigned-char ou -funsigned-char também podem ser necessários.
Um esforço mínimo foi necessário para resolver erros de compilação, substituindo as funções Intel Intrinsics por funções específicas do Arm usando a biblioteca somente de cabeçalho sse2neon. Erros de tempo de execução foram corrigidos, incluindo problemas de sincronização de memória causados por otimizações específicas do compilador anterior, o que resultou em reordenação de instruções e subsequentes divergências de precisão de ponto flutuante.
Para este experimento inicial, a Petrobras usou um conjunto fixo de flags de compilação para cada arquitetura (x86_64 e aarch64) sem ajustes específicos do processador. Isto foi feito com o objetivo de compreender o comportamento de desempenho out-of-the-box. A Tabela 1 ilustra as flags de compilação utilizadas.
Arquitetura |
Sinalizadores do Compilador |
x86_64 |
-std=c++17 -O3 -lrt -fPIC -m64 -march=nativo -mtune=nativo -fopenmp-simd -fopenmp |
aarch64 |
-std=c++17 -O3 -lrt –fPIC -mcpu=nativo -fopenmp-simd -fopen |
Tabela 1. Sinalizadores de compilação para arquiteturas baseadas em x86 e Arm
Medindo o Desempenho e a Eficiência Energética
Contêineres Singularity foram empregados para replicar o stack de computação do SolverBR em várias plataformas para garantir a reprodutibilidade. Um único arquivo de definição foi utilizado para gerar vários contêineres de tempo de execução, resultando em arquivos .sif únicos, um para cada arquitetura de CPU. A Tabela 2 especifica todas as CPUs testadas, baseadas em x86 e em Arm, locais e na nuvem. A NVIDIA conduziu os experimentos na arquitetura Grace, enquanto a Petrobras e o CESAR executaram os benchmarks nas demais arquiteturas.
Ambiente |
Processador |
Arquitetura |
Núcleos Físicos |
No local |
Intel Xeon Gold 6248* |
x86_64 |
20 |
No local |
CPU NVIDIA Grace** |
Armv9 |
72 |
AWS EC2 R7g |
AWS Graviton3 |
Armv8 |
64 |
AWS EC2 R7i |
Intel Xeon Platinum 8488C (Sapphire Rapids) |
x86_64 |
48 |
AWS EC2 R7a |
AMD EPYC 9R14 (Gênova) |
x86_64 |
96 |
Tabela 2. Especificações em processadores baseados em x86 e ARM no local e na nuvem
*Intel Xeon Gold 6248 é o principal cluster de CPU on-premises do Centro de Pesquisas da Petrobras (CENPES)
**Dados de CPU NVIDIA Grace calculados em um único NVIDIA Grace SoC usando a plataforma GH200 Superchip
O teste da porção linear do pipeline de simulação do reservatório mostrado na Figura 1 envolveu a extração das matrizes esparsas geradas pelo CMG dos conjuntos de dados de campos de petróleo e gás do pré-sal (Búzios, Proxy 100, Proxy 200, Sapinhoá) e do modelo de referência SPE10. O exemplo estabelece como os simuladores CMG podem ser modularizados e estendidos com componentes ou software de terceiros. Os engenheiros do CMG estão atualmente explorando oportunidades adicionais para portar componentes e recursos de seus simuladores, com o objetivo de otimizar o desempenho em várias plataformas e arquiteturas de hardware.
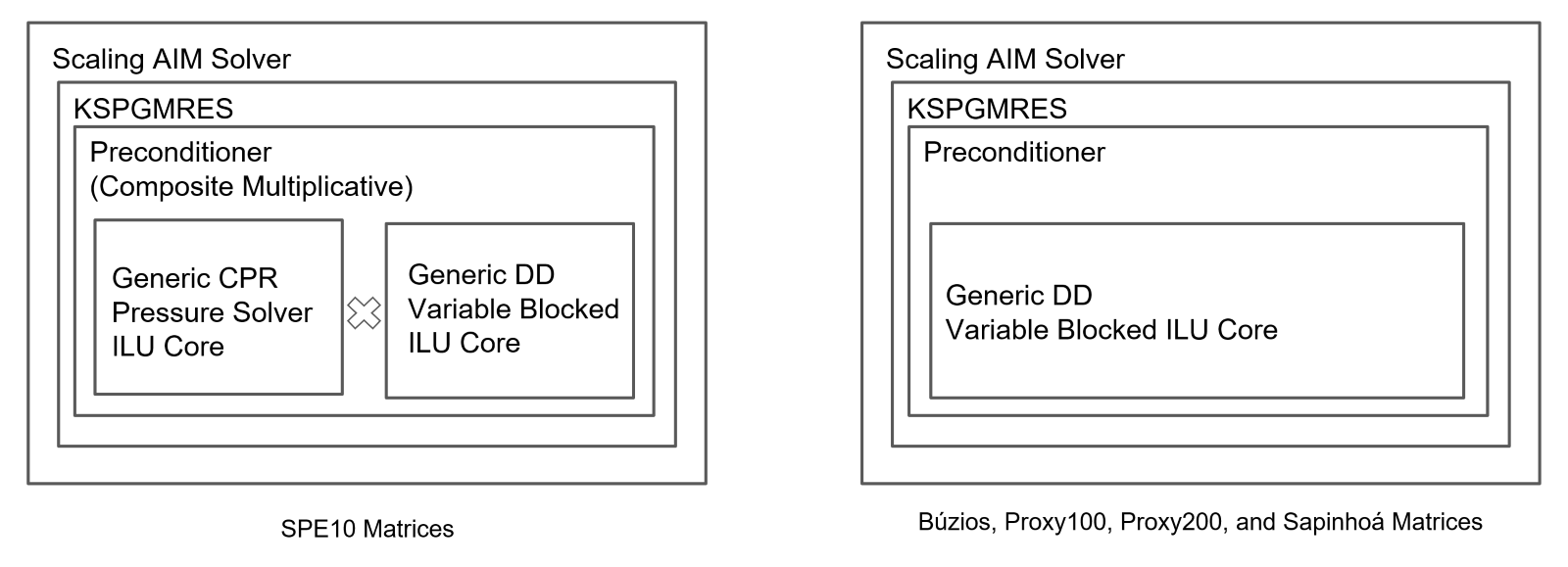
A Figura 2 exibe as configurações dos métodos lineares: Método Implícito Adaptativo (AIM), Residual Mínimo Generalizado de Projeção de Subespaço de Krylov (KSPGMRES), Resíduo de Pressão Restrita (CPR), Decomposição de Domínio (DD), Fatoração de LU Incompleta (ILU). Cada sistema de equações foi resolvido 50 vezes para todos os modelos ao longo de 3 anos, resultando em milhares de execuções.
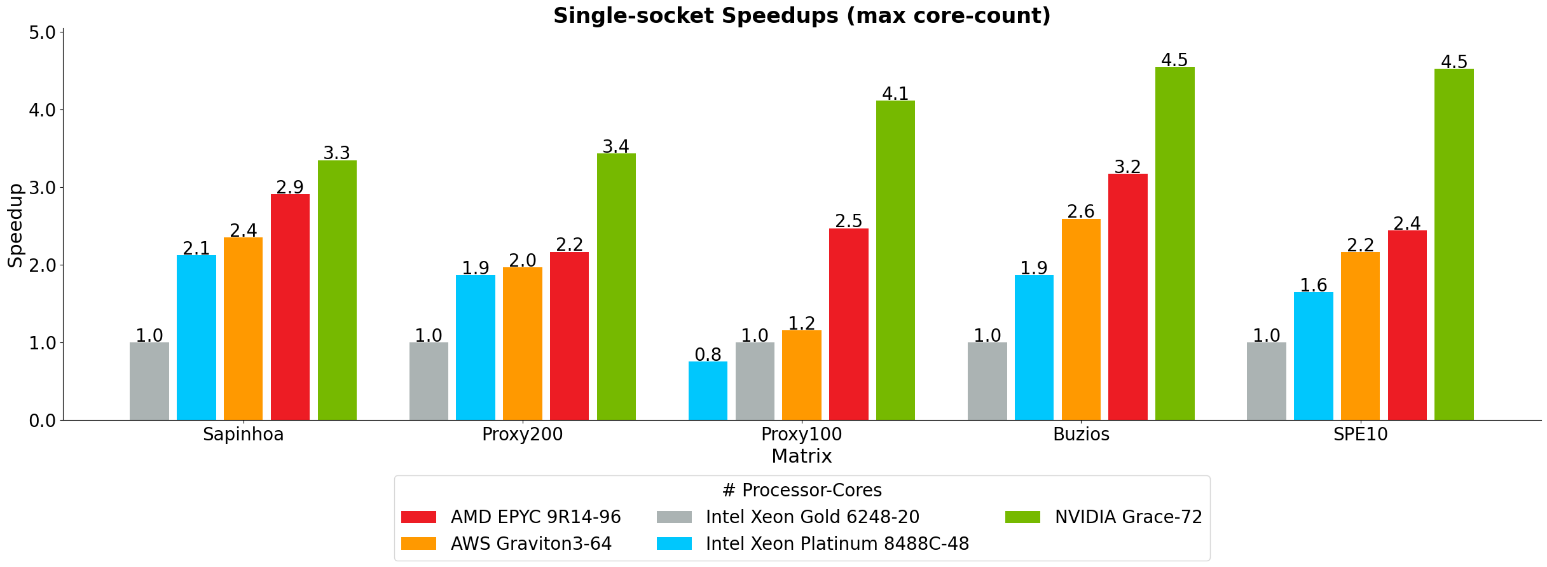
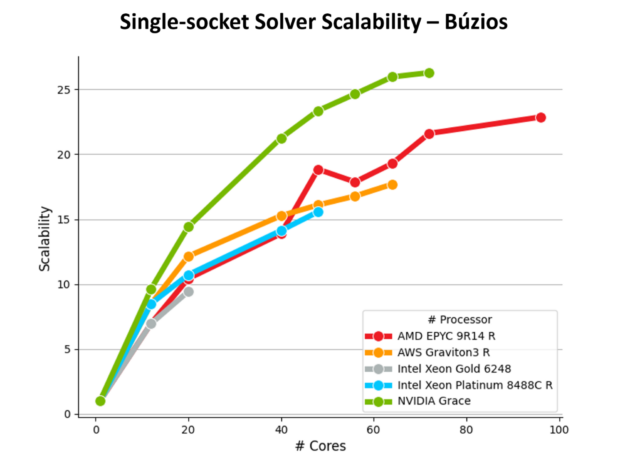
A Figura 3 apresenta os resultados de aceleração para cada modelo, utilizando o máximo de núcleos disponíveis em processadores de soquete único. Atualmente, a Petrobras utiliza a plataforma Intel Xeon Gold 6248 em seu cluster de CPU de produção on-premises, que serve como ponto de referência para a normalização dos resultados.
A arquitetura NVIDIA Grace demonstra desempenho superior, alcançando as mais altas taxas de desempenho em todos os modelos, incluindo:
- Aceleração de até 4,5 vezes em relação ao Intel Xeon Gold 6248 (CPU de linha de base da Petrobras)
- Aceleração de até 2,9 vezes em relação ao Intel Xeon Platinum 8488C
- Aceleração de até 1,9 vezes em relação ao AMD EPYC 9R14
A Figura 4 mostra que a CPU NVIDIA Grace tem a melhor escalabilidade ao variar o número total de núcleos até o máximo disponível em cada processador, com resultados até 53% melhores em relação à opção menos escalável. A CPU NVIDIA Grace demonstra desempenho excepcional para essa carga de trabalho específica devido às suas características exclusivas, que incluem alta largura de banda de memória efetiva, uma malha coerente escalável de CPU avançada (NVIDIA SCF) e a adoção de núcleos Arm Neoverse V2 de classe de servidor.
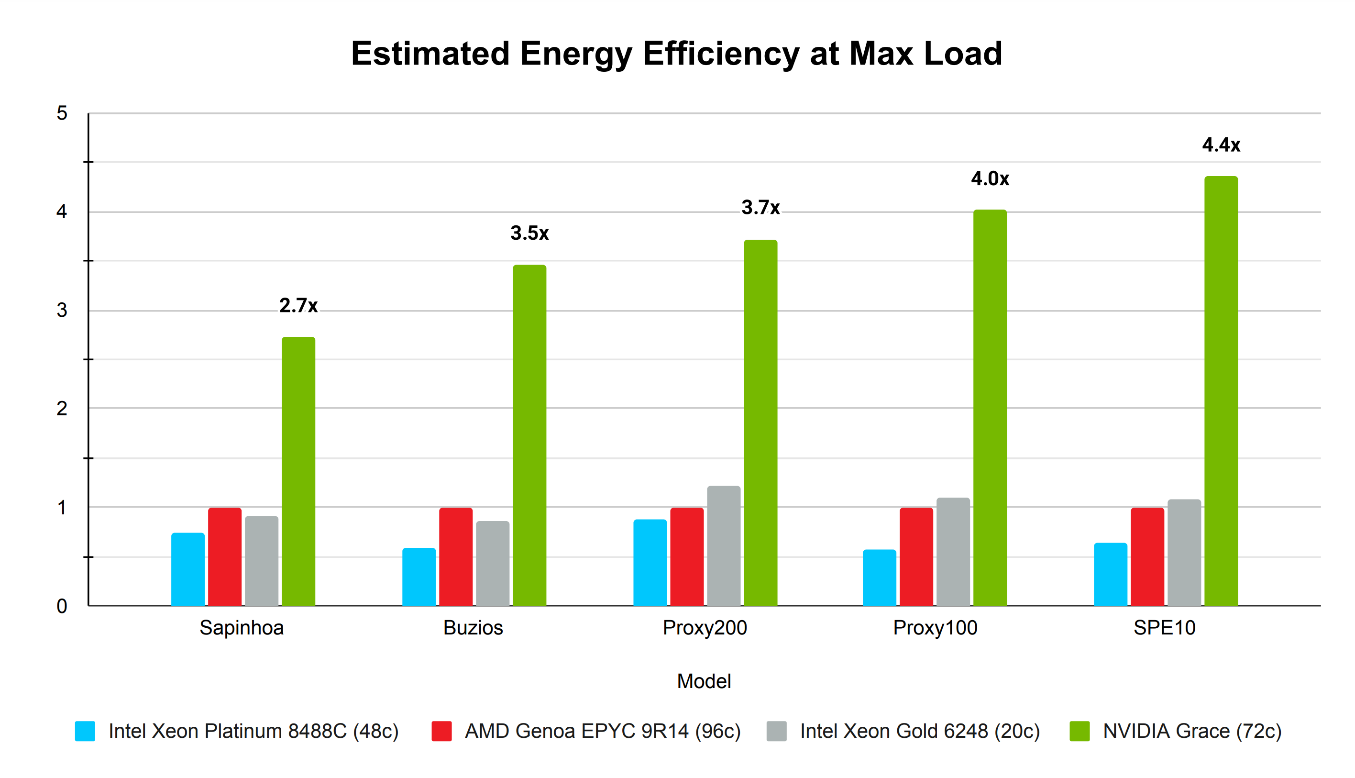
Para estimar a eficiência energética da CPU NVIDIA Grace em comparação com as CPUs locais, a potência máxima de design térmico (TDP) de cada CPU foi avaliada em carga total com um consumo de memória estimado com base na capacidade do processador e na geração tecnológica. Para a CPU NVIDIA Grace SoC, o consumo de memória da CPU foi de aproximadamente 250W, e as acelerações foram relatadas usando o AMD EPYC 9R14 como referência.
A NVIDIA Grace demonstrou a maior eficiência energética estimada em todos os testes de solucionador linear com carga máxima, com eficiência energética até 4,3 vezes maior (Figura 5).
Conclusão
A CPU NVIDIA Grace superou todas as CPUs testadas baseadas em x86 e Arm em TTS, escalabilidade e eficiência energética. Esse sucesso se deve principalmente à arquitetura NVIDIA Grace, que se concentra em combinar eficiência energética com alta performance e demanda por aplicações de HPC. Recursos como memória LPDDR5X, design do cache coerente unificado (SCF) e um stack de software otimizado com base no GCC contribuíram para esses resultados.
Como próximos passos, a Petrobras planeja portar e comparar seus simuladores geomecânicos e de reservatórios para Arm e explorar todo o potencial de vários superchips NVIDIA Grace para melhorar ainda mais o tempo de solução.
Para saber mais sobre a CPU NVIDIA Grace, assista à sessão on demand do NVIDIA GTC, Acelerando Solucionadores Lineares na NVIDIA Grace.
Informações Adicionais
Este trabalho foi executado pelos seguintes engenheiros e analistas: Felipe Portella (Petrobras), José Roberto Pereira Rodrigues (Petrobras), Leonardo Gasparini (Petrobras), Vitor Aquino (CESAR), Luigi Marques da Luz (CESAR).