
O NVIDIA Groq 3 LPX é um novo acelerador de inferência em escala de rack para a plataforma NVIDIA Vera Rubin, projetado para as demandas de baixa latência e grandes contextos de sistemas baseados em agentes. Projetado em parceria com o NVIDIA Vera Rubin NVL72, o LPX equipa a fábrica de IA com um mecanismo otimizado para geração de tokens rápida e previsível, enquanto o Vera Rubin NVL72 continua sendo a máquina flexível e de uso geral para treinamento e inferência, oferecendo alta taxa de processamento em tarefas de prefill e decode, incluindo processamento de contextos longos, atenção no decode e serviço de alta concorrência em escala.
Essa combinação é importante porque o futuro baseado em agentes exige uma nova categoria de inferência. À medida que as velocidades de geração se aproximam de 1.000 tokens por segundo por usuário, os modelos se movem para além da interação na velocidade de conversação em direção à velocidade da computação do pensamento. Nessa taxa, os sistemas de IA podem raciocinar, simular e responder continuamente, viabilizando experiências que se parecem menos com bate-papo em turnos e mais com colaboração em tempo real.
Essa mudança também eleva o limite para sistemas de vários agentes. Os agentes individuais podem ser poderosos por conta própria, mas grupos coordenados de agentes podem realizar muito mais, assim como as sociedades humanas escalam sua capacidade por meio de inteligência coletiva e coordenação.
O suporte a essas cargas de trabalho emergentes requer infraestrutura que possa oferecer alta taxa de processamento e latência extremamente baixa. A combinação do Vera Rubin NVL72 e do LPX viabiliza essa arquitetura heterogênea, combinando desempenho de fábricas de IA em larga escala com a geração rápida de tokens necessária para impulsionar sistemas baseados em agentes em execução contínua e aplicações de IA de última geração.
Apresentando o NVIDIA Groq 3 LPX
O Vera Rubin e o LPX combinam o desempenho extremo das GPUs Rubin e das LPUs para oferecer uma taxa de processamento de inferência por megawatt até 35 vezes maior e uma oportunidade de receita até dez vezes maior para modelos de trilhões de parâmetros. Integrado à arquitetura de rack NVIDIA MGX ETL e alinhado com a plataforma Vera Rubin mais ampla, o LPX oferece aos data centers uma maneira de implantar um caminho de inferência de baixa latência dedicado juntamente com o Vera Rubin NVL72 dentro de um design de infraestrutura comum.
O sistema foi desenvolvido em torno de 256 aceleradores NVIDIA Groq 3 LPU interconectados. Sua arquitetura enfatiza a execução determinística, alta largura de banda de SRAM on-chip e comunicação de expansão vertical fortemente coordenada, permitindo que a inferência interativa permaneça responsiva mesmo com o aumento da concorrência e a variação dos formatos de solicitação.
Implantado juntamente com o Vera Rubin NVL72, o LPX acelera as partes sensíveis à latência do loop de decode, incluindo a execução de FFN e de especialistas MoE, enquanto as GPUs Rubin continuam responsáveis por prefill e atenção no decode. Juntos, eles oferecem um caminho de atendimento heterogêneo que melhora a capacidade de resposta interativa sem sacrificar a taxa de processamento das fábricas de IA.

Em escala de rack, o LPX oferece:
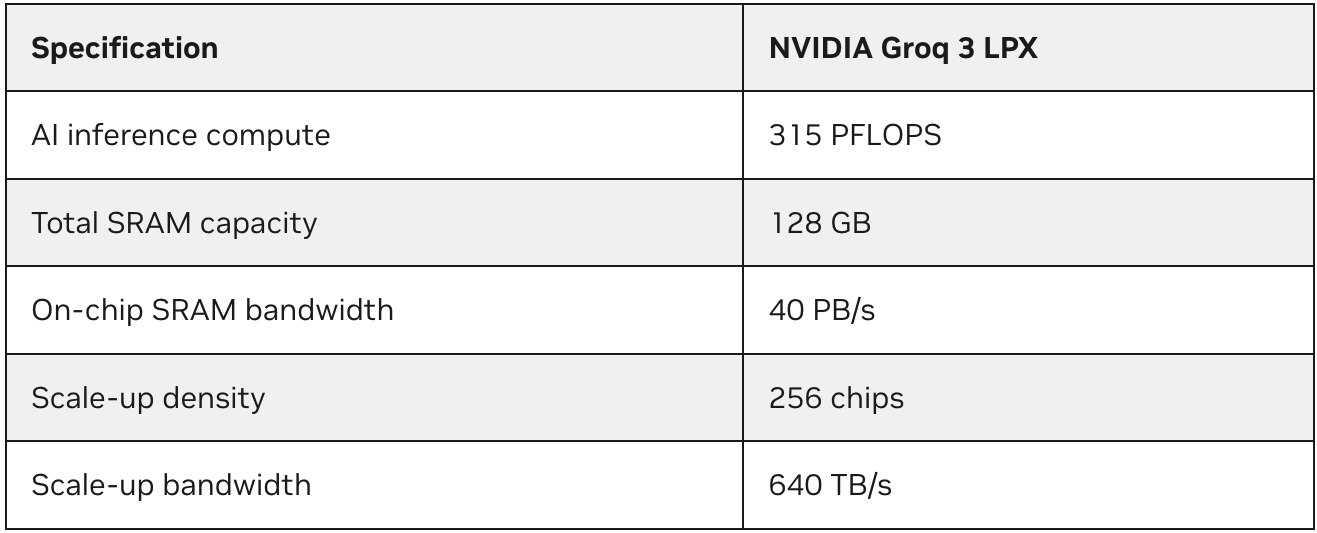
O Vera Rubin NVL72 e o LPX criam uma arquitetura de inferência mais heterogênea para a fábrica de IA, que pode suportar alta produção agregada de tokens e experiências de IA interativas responsivas.
Por dentro da bandeja de computação do NVIDIA Groq 3 LPX
O acelerador em escala de rack LPX abriga 32 bandejas de computação 1U com resfriamento líquido, cada uma projetada para suportar inferência de baixa latência em escala. Cada bandeja integra oito aceleradores LPU, um processador host e lógica de expansão de malha em um design sem cabos que simplifica a implantação em escala de rack e integra de forma estreita o processamento à comunicação.
As conexões de LPU chip-to-chip (C2C) fornecem comunicação direta dentro da bandeja, entre bandejas por meio do spine C2C das LPUs e entre racks à medida que os sistemas escalam. A conectividade é importante porque a inferência interativa não se trata apenas de processamento bruto. Ela também depende da eficiência com que o sistema pode mover dados, coordenar as tarefas e evitar atrasos variáveis à medida que as solicitações fluem entre os dispositivos.

Cada bandeja oferece:
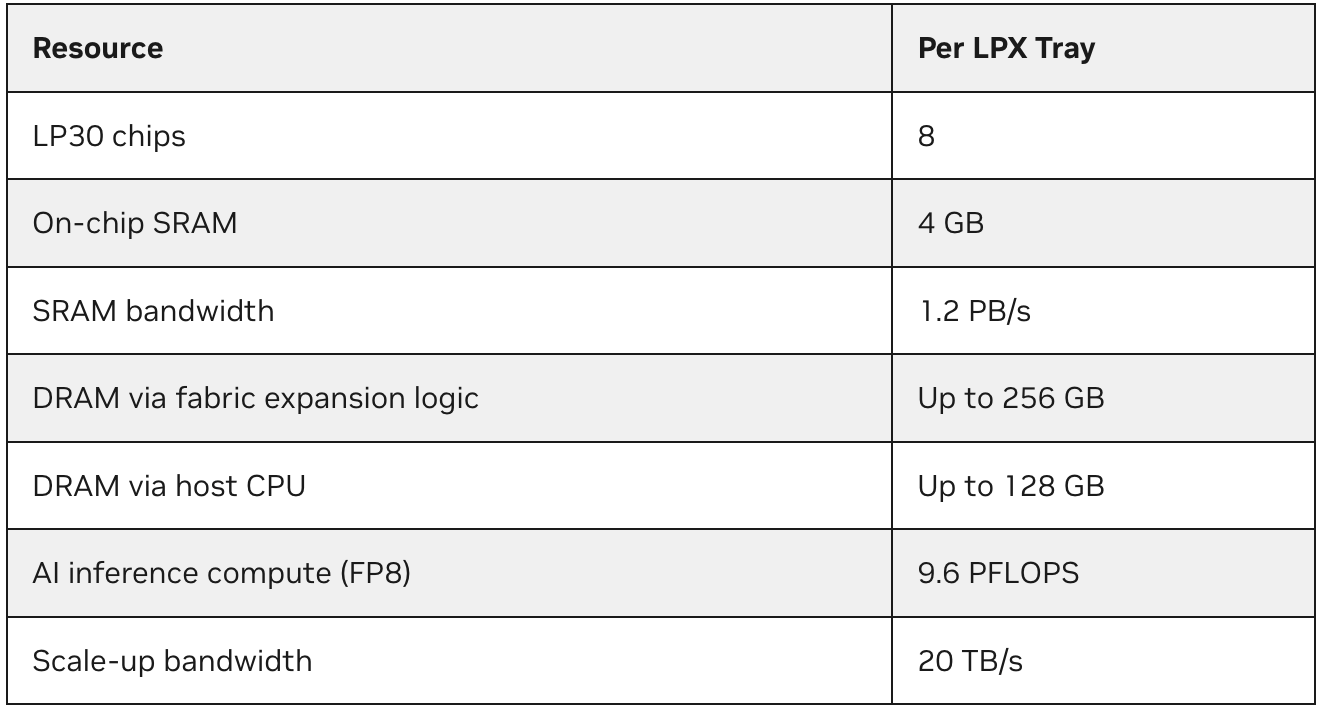
No nível do sistema, o LPX foi projetado para cenários de inferência nos quais a sobrecarga de coordenação e o jitter podem se tornar rapidamente perceptíveis para os usuários. Isso é especialmente relevante à medida que mais aplicações de IA se afastam de cenários off-line ou orientados por taxa de processamento e passam a priorizar a geração interativa. Para ver como o LPX é otimizado para esse regime, vale a pena analisar a arquitetura de processador no núcleo do sistema: a NVIDIA Groq 3 LPU.
Primeira análise da arquitetura da NVIDIA Groq 3 LPU — o sétimo chip da Plataforma Vera Rubin
No coração do LPX está a NVIDIA Groq 3 LPU, projetada para oferecer geração de tokens rápida e previsível ao integrar computação, memória e comunicação sob o controle do compilador. A arquitetura da LPU foi projetada para oferecer geração de tokens rápida e previsível ao integrar computação, memória e comunicação sob o controle do compilador. Em vez de otimizar apenas para a taxa de processamento aritmética de pico, a LPU enfatiza a execução determinística, a alta largura de banda de memória on-chip e o movimento de dados explícito. Esses recursos são especialmente importantes para regimes de inferência dominados por decode e sensíveis à latência.
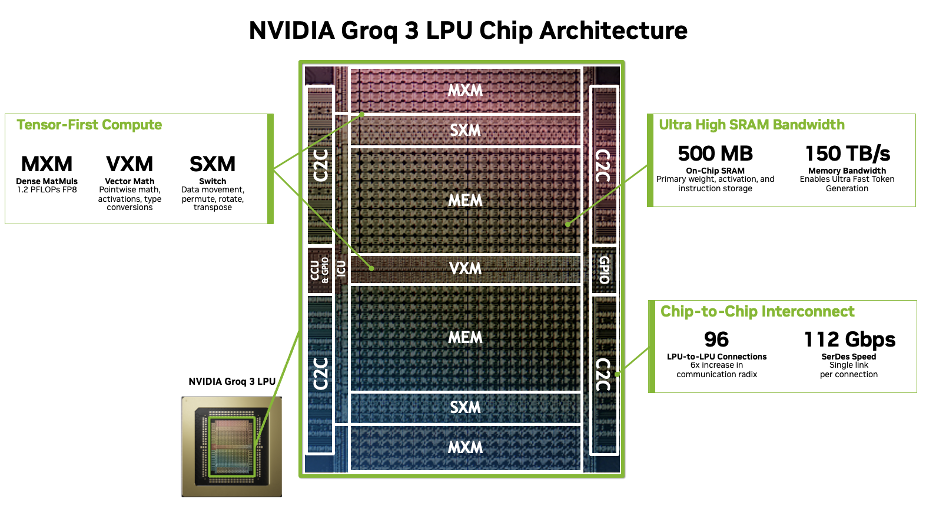
Computação orientada por tensores e movimento de dados explícito
A computação e a comunicação na LPU são organizadas em torno de vetores de 320 bytes como unidade de trabalho. As operações aritméticas, o acesso à memória e as transferências entre dispositivos operam nesses vetores de tamanho fixo, simplificando o agendamento e a sincronização.
Os módulos de execução especializados lidam com diferentes classes de operações:
- Os módulos de execução de matrizes (MXM) fornecem capacidade densa de multiplicação e acumulação para operações tensoriais, operando em tipos de dados fixos a uma taxa de processamento previsível.
- Os módulos de execução vetorial (VXM) executam operações aritméticas ponto a ponto, conversões de tipo e funções de ativação utilizando uma malha de unidades lógicas aritméticas (ALUs) por via.
- Os módulos de execução de comutação (SXM) realizam a movimentação estruturada de dados, incluindo permutação, rotação, distribuição e transposição de vetores.
Ao tornar a movimentação de dados explícita e programável, a LPU permite que o acesso à memória, a computação e a comunicação se sobreponham, em vez de depender de heurísticas de hardware.
O MEM possibilita largura de banda extrema de memória on-chip
Um elemento central da LPU é o bloco MEM, uma arquitetura de memória plana e com foco em SRAM, na qual 500 MB de SRAM on-chip de alta velocidade servem como o principal armazenamento de trabalho para inferência. Em vez de depender de caches gerenciados por hardware, o compilador e o runtime posicionam o conjunto de trabalho ativo, incluindo pesos, ativações e estado de KV, na memória on-chip e movem os dados explicitamente. Isso reduz os atrasos imprevisíveis e ajuda a proporcionar latência baixa e estável, mantendo os dados mais sensíveis à latência próximos ao processamento.
Como a capacidade da SRAM on-chip é finita, modelos maiores são escalados em múltiplos aceleradores de LPU interconectados usando estratégias de execução paralelas, como particionamento por camada, de modo que o sistema geral apresente um conjunto de trabalho efetivo muito maior. Nesse design, o desempenho é regido menos pela taxa de processamento aritmética de pico e mais pela consistência com que o sistema consegue manter o processamento alimentado. É por isso que o LPX combina 150 TB/s de largura de banda de memória on-chip com comunicação chip a chip (C2C) de alta largura de banda e expansão vertical por LPU.
Escalabilidade C2C com comunicação previsível
Para escalar a inferência em vários dispositivos, a LPU inclui conexões C2C de alta velocidade e alto radix, projetadas para troca de dados determinística. Cada LPU se conecta por meio de 96 conexões C2C sendo executadas a 112 Gbps cada, permitindo uma topologia LPX de expansão vertical com alta largura de banda bidirecional de E/S agregada de 2,5 TB/s e tempo de comunicação previsível. Isso é especialmente importante para pipelines de inferência distribuída, nos quais a sobrecarga de comunicação pode se tornar uma grande fonte de latência.
Execução determinística e orquestrada por compilador
A LPU se baseia no modelo de execução espacial do Groq, no qual o compilador agenda explicitamente o processamento, o movimento de dados e a sincronização. Em vez de depender em agendadores de hardware dinâmicos no runtime, o compilador utiliza um protocolo plesiossíncrono, chip a chip, implementado em hardware que compensa a deriva natural do clock e sincroniza centenas de aceleradores de LPU para agir como um único sistema coordenado. Com a chegada previsível dos dados e a sincronização periódica do software, os desenvolvedores podem pensar mais diretamente sobre o controle de tempo, e o sistema pode coordenar o comportamento do processamento e da rede com um determinismo muito maior.
Esse modelo de execução permite:
- Coordenação precisa entre memória e processamento.
- Controle explícito sobre a sincronia das instruções.
- Jitter de execução reduzido sob cargas de trabalho variáveis
Para inferência em tempo real, esse determinismo ajuda a manter o tempo até o primeiro token e a latência por token estáveis, mesmo em lotes pequenos.
A mudança em direção à inferência interativa
A inferência de IA abrange um amplo espectro de desempenho. Por um lado, estão os serviços otimizados para taxa de processamento, como processamento de documentos em lote, moderação, incorporações e pipelines de mídia, em que o objetivo é maximizar os tokens por GPU, os tokens por watt ou a eficiência de custo como um todo. Essas cargas de trabalho geralmente dão suporte a serviços compartilhados em larga escala, incluindo ofertas de IA gratuitas e em segundo plano, nas quais a alta utilização importa mais do que capacidade de resposta por usuário.
Na outra extremidade estão os serviços otimizados para latência, como assistentes de programação, chatbots, assistentes de voz, copilotos e agentes interativos, nos quais atrasos são imediatamente visíveis para os usuários. Nessas cargas de trabalho, as métricas mais importantes são tempo até o primeiro token, tokens por segundo por usuário e a latência de pior caso. Muitas plataformas de IA modernas devem dar suporte a ambos os regimes simultaneamente, executando back-ends de alta taxa de processamento para processamento em larga escala e, ao mesmo tempo, oferecendo experiências interativas responsivas. Essa divergência é uma das razões pelas quais as arquiteturas de inferência heterogêneas estão se tornando cada vez mais importantes.
O que dificulta a inferência interativa
Várias tendências estão tornando a inferência interativa de baixa latência mais importante e difícil de atender de forma eficiente, como mostrado na Tabela 3. À medida que os modelos produzem saídas mais longas e as janelas de contexto crescem, uma parte maior da carga de trabalho muda para o decode, no qual os tokens são gerados sequencialmente. Isso faz com que a capacidade de resposta seja exposta diretamente ao usuário.

Ao mesmo tempo, os contextos mais longos aumentam a pressão sobre a largura de banda de memória e a movimentação de dados, enquanto atender a muitos usuários simultâneos reduz a eficiência da divisão em lotes da qual os sistemas orientados para taxa de processamento dependem. Como resultado, os sistemas otimizados para máxima taxa de processamento agregada nem sempre são a melhor opção para cargas de trabalho que exigem geração de tokens rápida e previsível para cada solicitação.
Esse desafio se torna ainda mais evidente na IA baseada em agentes, na qual sistemas percorrem repetidamente ciclos de inferência, recuperação, uso de ferramentas e raciocínio. Nesses loops, a latência se acumula a cada etapa, tornando crítico um desempenho estável por token e um bom comportamento de latência no pior caso para que haja experiências de usuários responsivas.
A era da inferência baseada em agentes requer uma nova arquitetura
Inferência não é uma carga de trabalho única e uniforme. Em uma solicitação, o prefill e o decode impõem diferentes demandas ao hardware, e essas demandas mudam conforme o tamanho do lote, o comprimento do contexto e a estrutura do modelo. Algumas fases, incluindo a de autoatenção e MoE esparso, podem se tornar altamente sensíveis à largura de banda de memória e à movimentação de dados, enquanto outras, como projeção densa e camadas de feed-forward, escalam com eficiência em hardware otimizado para taxa de processamento quando há paralelismo suficiente disponível. No decode interativo, muitas operações são executadas em lotes muito pequenos, tornando a latência muito mais sensível a atrasos, conflitos e jitter.
Otimizar todo o pipeline para apenas um regime força uma compensação. Um hardware ajustado para taxa de processamento de pico em grandes lotes não é ideal para os caminhos de execução mais sensíveis à latência, enquanto um hardware otimizado para execução de baixa latência é menos eficiente para as fases com uso mais intensivo de processamento.
Conforme mostrado na Figura 4, um sistema heterogêneo combina as duas abordagens, combinando desempenho interativo de baixa latência com alta taxa de processamento de fábricas de IA. O resultado é uma arquitetura de dois mecanismos: as GPUs oferecem alta saída para prefill com contexto intensivo e executam a atenção no decode, enquanto as LPUs aceleram os componentes de decode sensíveis à latência, como a execução de FFN/MoE. Juntos, eles melhoram a interatividade sem abrir mão da taxa de processamento das fábricas de IA.

Vera Rubin NVL72 encontra o LPX
A inferência moderna é uma corrida de revezamento. O mesmo hardware que executa a etapa de contexto pesado não precisa comandar a corrida até o próximo token. As GPUs Rubin são os motores flexíveis e de uso geral para treinamento e inferência. Elas oferecem alta taxa de processamento para diversos tamanhos de modelos, regimes de lote e padrões de serviço, desde o prefill de contexto longo até a atenção de decode e a inferência de alta simultaneidade em escala.
O LPX adiciona um caminho especializado e otimizado para geração de tokens rápida e sensível à latência. Juntos, eles possibilitam um projeto de inferência heterogêneo que melhora a capacidade de resposta interativa sem abrir mão da eficiência em escala do sistema.

Fase de decode: um loop repetido de vários mecanismos
A fase de prefill é dominada pela ingestão de grandes entradas e pela criação do cache KV, uma carga de trabalho que se beneficia do processamento paralelo denso e de grandes capacidades de memória. O Vera Rubin NVL72 lida com essa fase de forma eficiente, especialmente para cargas de trabalho de contexto longo e modelos MoE nos quais o contexto pode ser grande e altamente variável.
A fase de decode é diferente. O decode é um loop repetido por token, e diferentes partes desse loop pressionam diferentes gargalos. Na arquitetura da plataforma Vera Rubin com LPX, o decode é melhor visto como um loop de dois mecanismos. As GPUs cuidam do trabalho de decode que mais se beneficia da taxa de processamento e da grande capacidade de memória, como a atenção ao contexto completo no cache KV acumulado. O LPX acelera a execução sensível à latência dentro do decode, como redes feed-forward especializadas (FFNs) de especialistas MoE esparsos e outras operações ponto a ponto. Essa divisão, geralmente descrita como desagregação da fase de decode ou desagregação atenção-FFN (AFD), separa a atenção do FFN dentro do decode e troca ativações intermediárias para cada token, de modo que cada mecanismo execute a parte do loop à qual mais se adequa. Esse loop de AFD expande a região operacional de mais alto valor da fronteira de Pareto.

Em escala de rack e além, o LPX foi projetado para operar como uma unidade de processamento coesa, minimizando a sobrecarga de coordenação e reduzindo o jitter. Isso é valioso em workflows baseados em agentes com forte uso de decode, nos quais pequenos atrasos se acumulam ao longo de várias chamadas de modelo e loops de verificação.
O NVIDIA Dynamo torna o decode heterogêneo operacional.
Tornar o decode heterogêneo prático requer software capaz de classificar solicitações, direcionar o trabalho com base em alvos de latência, mover ativações intermediárias com baixa sobrecarga e manter estável a latência de pior caso em tráfego intenso e variável. O NVIDIA Dynamo fornece essa camada de orquestração, coordenando o atendimento e o decode desagregados em back-ends heterogêneos.
Na prática, o Dynamo direciona o prefill para os workers de GPU para processar o contexto grande e criar o cache KV. Durante o decode, o Dynamo orquestra o loop de AFD, no qual as GPUs executam a atenção sobre o cache KV acumulado, ativações intermediárias são transferidas para LPUs para execução FFN/MoE, e as saídas retornam às GPUs para continuar a geração de tokens. O resultado é um caminho de atendimento único e coerente com latência de pior caso mais previsível, ao mesmo tempo em que sustenta uma alta taxa de processamento de fábricas de IA.

Com direcionamento com reconhecimento de KV, transferências de baixa sobrecarga e agendamento orientado por metas de latência, o Dynamo ajuda a manter sessões interativas fora de longas filas, reduz o jitter entre tenants e mantém uma latência de pior caso estável, à medida que a simultaneidade e as formas de solicitação variam. O resultado é um modelo de atendimento heterogêneo pronto para produção que oferece experiências de usuário responsivas, ao mesmo tempo em que sustenta alta taxa de processamento de fábricas de IA em escala.
Acelerando o decode especulativo com LPX
O decode especulativo é uma técnica cada vez mais importante para reduzir a latência na inferência de LLM. A abordagem usa um modelo de rascunho menor para gerar vários tokens candidatos com antecedência, enquanto um modelo-alvo maior verifica e aceita esses tokens em paralelo. Quando as previsões coincidem, vários tokens podem ser confirmados de uma só vez, aumentando significativamente os tokens por segundo efetivos e reduzindo a latência de resposta.
O LPX é adequado para agir como o mecanismo de geração de rascunhos nessa arquitetura. O modelo de execução determinística e a largura de banda de SRAM on-chip extremamente alta da LPU possibilitam uma geração de tokens de rascunho muito rápida, permitindo que o modelo de rascunho seja executado à frente do verificador. Ao mesmo tempo, as GPUs, como a Rubin, permanecem altamente eficientes para tarefas de execução de grandes modelos, como prefill, processamento de atenção e verificação de tokens.
Ao acoplar os dois, o sistema combina os pontos fortes de ambos os processadores:
- O LPX gera tokens de rascunho rapidamente usando sua arquitetura de baixa latência.
- As GPUs Rubin verificam e finalizam tokens com eficiência usando sua alta taxa de processamento e grande capacidade de memória.
Essa separação permite que o decode especulativo seja executado em processadores heterogêneos, em vez de executar modelos de rascunho e verificadores no mesmo hardware. O resultado é um sistema que pode oferecer uma geração de rascunhos mais rápida sem sacrificar a eficiência da verificação baseada em GPU.

Liberando enxames inteligentes baseados em agentes
À medida que os casos de uso de IA evoluem de simples salas de bate-papo e inferência em lote para fluxos baseados em agentes de várias etapas, a capacidade de resposta se torna um requisito importante. A inferência off-line e os assistentes básicos geralmente podem priorizar a taxa de processamento agregada, mas as aplicações interativas, a pesquisa profunda e os pipelines baseados em agentes combinam alto volume de tokens com loops de feedback apertados, nos quais a latência se acumula ao longo de muitas chamadas de modelo e interações com ferramentas.
Nesse regime, a inferência heterogênea é importante. A combinação de um mecanismo de alta taxa de processamento para processamento de contexto longo com um mecanismo de baixa latência para FFNs de decode possibilita aumentar a interatividade do usuário sem sacrificar a produção da fábrica de IA.

Desbloqueando uma nova categoria de experiências de IA na fronteira de Pareto
Uma maneira prática de visualizar essa compensação entre desempenho e custo é a fronteira de Pareto, plotando a interatividade do usuário, medida em tokens por segundo por usuário (TPS por usuário) no eixo horizontal, em comparação com a taxa de processamento da fábrica de IA, medida em tokens por segundo por megawatt (TPS por MW), no eixo vertical.
Conforme mostrado na Figura 10, diferentes serviços de IA operam em pontos muito diferentes dessa curva. Os serviços orientados à taxa de processamento, incluindo muitas cargas de trabalho gratuitas e em segundo plano, geralmente priorizam a eficiência máxima e a alta utilização e frequentemente usam modelos menores com janelas de contexto mais curtas. Os serviços de IA premium, por outro lado, exigem maior capacidade de modelo e desempenho muito mais responsivo visível pelo usuário, especialmente para raciocínio de longo contexto e workflows baseados em agentes. Na Figura 10, esse nível premium é representado por um modelo MoE de 2 trilhões de parâmetros com uma janela de contexto de entrada de 400 mil operando a aproximadamente 400 TPS por usuário e acima.

Alcançar esses pontos operacionais premium com uma única plataforma homogênea força uma compensação entre a capacidade de resposta e a taxa de processamento geral da fábrica de IA, porque a carga de trabalho combina regimes de desempenho fundamentalmente diferentes no mesmo pipeline de atendimento. Uma arquitetura heterogênea expande a região alcançável ao combinar caminhos de execução complementares, permitindo que o sistema sustente a alta produção da fábrica e, ao mesmo tempo, ofereça experiências interativas altamente responsivas e de baixa latência. Conforme ilustrado na Figura 10, a combinação do Vera Rubin NVL72 e do LPX oferece um TPS por megawatt até 35 vezes maior, com 400 TPS por usuário, em comparação com o NVIDIA GB200 NVL72, criando efetivamente um novo nível de desempenho premium para serviços de IA interativa.
Essa mudança gera impacto econômico direto. Uma capacidade de resposta mais alta expande o conjunto de experiências premium que uma fábrica de IA pode oferecer e aumenta o valor por unidade de infraestrutura. Com a plataforma Vera Rubin, as fábricas de IA podem gerar até 5 vezes mais receita por megawatt em comparação com o GB200 NVL72, e até dez vezes mais ao combinar o Vera Rubin NVL72 com LPX para as cargas de trabalho interativas de maior valor e mais sensíveis à latência, como programação baseada em agentes e sistemas multiagente.

O que o NVIDIA Groq 3 LPX possibilita para desenvolvedores
Os desenvolvedores estão cada vez mais construindo sistemas que exigem três coisas ao mesmo tempo:
- Capacidade de resposta: latência baixa e previsível para experiências interativas e loops de agentes.
- Capacidade: qualidade de modelos sólida, profundidade de raciocínio e compreensão de contexto longo.
- Escala: alta taxa de processamento e eficiência de custo para atender a muitos usuários ou agentes simultâneos.
O LPX amplia o conjunto de cargas de trabalho que uma fábrica de IA pode atender com eficiência. Use o caminho de baixa latência em que a geração previsível de tokens melhora a experiência, como assistentes de programação, workflows baseados em agentes com loops apertados de chamada de ferramentas, interações de voz e tradução em tempo real. Mantenha as cargas de trabalho centradas na taxa de processamento nas GPUs Rubin, como atendimento em lote e execuções de processamento de longo contexto, nos quais a alta simultaneidade e a geração em lote mantêm as GPUs constantemente ocupadas e com boa eficiência de custo. A mudança operacional é de mentalidade. Pare de otimizar para uma única métrica e comece a otimizar para uma variedade de cenários reais de operação.
Saiba Mais
Aprofunde-se na arquitetura por trás do NVIDIA Groq 3 LPX e do Vera Rubin com as páginas de produtos e blogs técnicos da NVIDIA, que abordam plataforma Vera Rubin, LPX, AFD e Dynamo. Explore a pesquisa subjacente sobre processadores de streaming tensorial e design de silício definido por software para IA. Juntos, esses recursos oferecem uma visão mais aprofundada do hardware, da arquitetura dos sistemas e do software de orquestração por trás da inferência heterogênea e de baixa latência em escala. Em seguida, participe de um tópico do Fórum de Desenvolvedores NVIDIA focado em inferência e implantação para comparar notas com outras equipes que desenvolvem sistemas de atendimento de baixa latência.
Recursos
- Página do NVIDIA LPX
- Comunicado à Imprensa: NVIDIA Vera Rubin Abre a Fronteira da IA Baseada em Agentes
- Blog de Tecnologia: Por Dentro da Plataforma NVIDIA Rubin: Seis Novos Chips, Um Supercomputador de IA
- Blog de Tecnologia: NVIDIA Vera Rubin POD: Sete Chips, Cinco Sistemas em Escala de Rack, Um Supercomputador de IA
- Blog Técnico: Apresentando o NVIDIA Dynamo 1.0: Escalando a Inferência em Vários Nós na Produção
- Vídeo: O Futuro da Inferência de IA — Explicação sobre a Desagregação Atenção-FFN (AFD) (a partir de 18:00)
- Blog Técnico: CPU NVIDIA Vera Oferece Alto Desempenho, Largura de Banda e Eficiência para Fábricas de IA
- Artigo de Pesquisa: Pense Rápido: Um Processador de Streaming de Tensores (TSP) para Acelerar Cargas de Trabalho de Deep Learning
- Artigo de Pesquisa: Um Multiprocessador de Streaming de Tensores Definido por Software para Machine Learning em Larga Escala
- Vídeo: Habilitando as Milhares de Operações do PyTorch para o Design de Silício Orientado por Software
Agradecimentos
Agradecemos a Amr Elmeleegy, Andrew Bitar, Andrew Ling, Graham Steele, Itay Neeman, Jamie Li, Omar Kilani, Santosh Raghavan e Stuart Pitts, juntamente com muitos outros líderes de produtos, engenheiros e arquitetos da NVIDIA que contribuíram para esta publicação.