
A IA está criando valor para todos, desde pesquisadores na descoberta de medicamentos até analistas quantitativos que navegam pelas mudanças do mercado financeiro.
Quanto mais rápido um sistema de IA puder produzir tokens, uma unidade de dados usada para encadear saídas, maior será seu impacto. É por isso que as fábricas de IA são fundamentais, fornecendo o caminho mais eficiente do “tempo até o primeiro token” até o “tempo até a primeira receita”.
As fábricas de IA estão redefinindo a economia da infraestrutura moderna. Eles produzem inteligência transformando dados em resultados valiosos, sejam tokens, previsões, imagens, proteínas ou outras formas, em grande escala.
Eles ajudam a aprimorar três aspectos principais da jornada de IA: ingestão de dados, treinamento de modelos e inferência de alto volume. As fábricas de IA estão sendo construídas para gerar tokens com mais rapidez e precisão, usando três stacks críticos de tecnologia: modelos de IA, infraestrutura de computação acelerada e software de nível empresarial.
Continue lendo para saber como as fábricas de IA estão ajudando empresas e organizações em todo o mundo a converter a mercadoria digital mais valiosa, dados, em potencial de receita.
Da Economia de Inferência à Criação de Valor
Antes de construir uma fábrica de IA, é importante entender a economia da inferência: como equilibrar custos, eficiência energética e uma demanda crescente por IA.
A taxa de transferência refere-se ao volume de tokens que um modelo pode produzir. A latência é a quantidade de tokens que o modelo pode gerar em um período de tempo específico, que geralmente é medido em tempo para o primeiro token (quanto tempo leva até que a primeira saída apareça) e tempo por token de saída ou a rapidez com que cada token adicional é lançado. Goodput é uma métrica mais recente, medindo a quantidade de saída útil que um sistema pode oferecer enquanto atinge as principais metas de latência.
A experiência do usuário é fundamental para qualquer aplicação de software, e o mesmo vale para as fábricas de IA. Alta taxa de transferência significa IA mais inteligente e menor latência garante respostas oportunas. Quando essas duas medidas são equilibradas adequadamente, as fábricas de IA podem fornecer experiências de usuário envolventes, fornecendo rapidamente resultados úteis.
Por exemplo, um agente de atendimento ao cliente com inteligência artificial que responde em meio segundo é muito mais envolvente e valioso do que um que responde em cinco segundos, mesmo que ambos gerem o mesmo número de tokens na resposta.
As empresas podem aproveitar a oportunidade para colocar preços competitivos em sua saída de inferência, resultando em mais potencial de receita por token.
Medir e visualizar esse equilíbrio pode ser difícil; e é aí que entra o conceito de fronteira de Pareto.
AI Factory Output: o Valor de Tokens Eficientes
A fronteira de Pareto, representada na figura abaixo, ajuda a visualizar as melhores maneiras de equilibrar as compensações entre metas concorrentes, como respostas mais rápidas versus atender a mais usuários simultaneamente, ao implantar IA em escala.
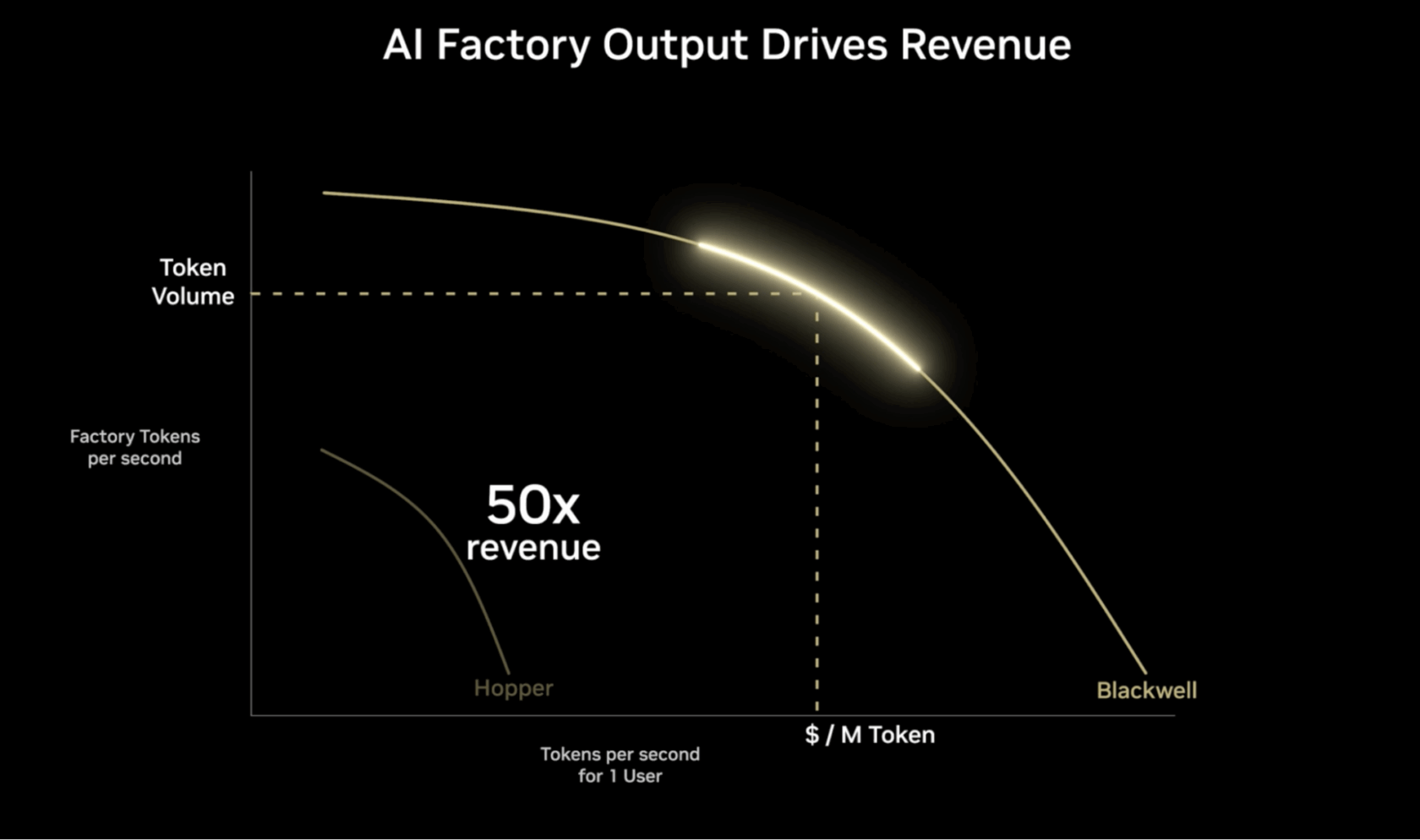
O eixo vertical representa a eficiência da taxa de transferência, medida em tokens por segundo (TPS), para uma determinada quantidade de energia usada. Quanto maior esse número, mais solicitações uma fábrica de IA pode lidar simultaneamente.
O eixo horizontal representa o TPS para um único usuário, representando quanto tempo leva para um modelo dar a um usuário a primeira resposta a um prompt. Quanto maior o valor, melhor a experiência esperada do usuário. Latência mais baixa e tempos de resposta mais rápidos geralmente são desejáveis para aplicações interativas, como chatbots e ferramentas de análise em tempo real.
O valor máximo da fronteira de Pareto, mostrado como o valor superior da curva, representa a melhor saída para determinados conjuntos de configurações operacionais. O objetivo é encontrar o equilíbrio ideal entre taxa de transferência e experiência do usuário para diferentes cargas de trabalho e aplicações de IA.
As melhores fábricas de IA usam computação acelerada para aumentar os tokens por watt, otimizando o desempenho da IA e aumentando significativamente a eficiência energética nas fábricas e aplicações de IA.

A animação acima compara a experiência do usuário ao executar em GPUs NVIDIA H100 configuradas para serem executadas a 32 tokens por segundo por usuário, versus GPUs NVIDIA B300 executadas a 344 tokens por segundo por usuário. Na experiência do usuário configurada, o Blackwell Ultra oferece uma experiência 10 vezes melhor e uma taxa de transferência quase 5 vezes maior, permitindo um potencial de receita até 50 vezes maior.
Como Funciona Uma Fábrica de IA na Prática
Uma fábrica de IA é um sistema de componentes que se unem para transformar dados em inteligência. Ela não assume necessariamente a forma de um data center no local de ponta, mas pode ser uma nuvem dedicada à IA ou um modelo híbrido executado em infraestrutura de computação acelerada. Ou pode ser uma infraestrutura de telecomunicações que pode otimizar a rede e realizar inferências no edge.
Qualquer infraestrutura de computação acelerada dedicada emparelhada com software que transforma dados em inteligência por meio da IA é, na prática, uma fábrica de IA.
Os componentes incluem computação acelerada, rede, software, armazenamento, sistemas e ferramentas e serviços.
Quando uma pessoa solicita um sistema de IA, todo o stack da fábrica de IA começa a funcionar. A fábrica tokeniza o prompt, transformando dados em pequenas unidades de significado, como fragmentos de imagens, sons e palavras.
Cada token é submetido a um modelo de IA impulsionado por GPU, que executa raciocínio intensivo de computação no modelo de IA para gerar a melhor resposta. Cada GPU executa processamento paralelo, habilitado por rede e interconexões de alta velocidade, para processar dados simultaneamente.
Uma fábrica de IA executará esse processo para diferentes prompts de usuários em todo o mundo. Isso é inferência em tempo real, produzindo inteligência em escala industrial.
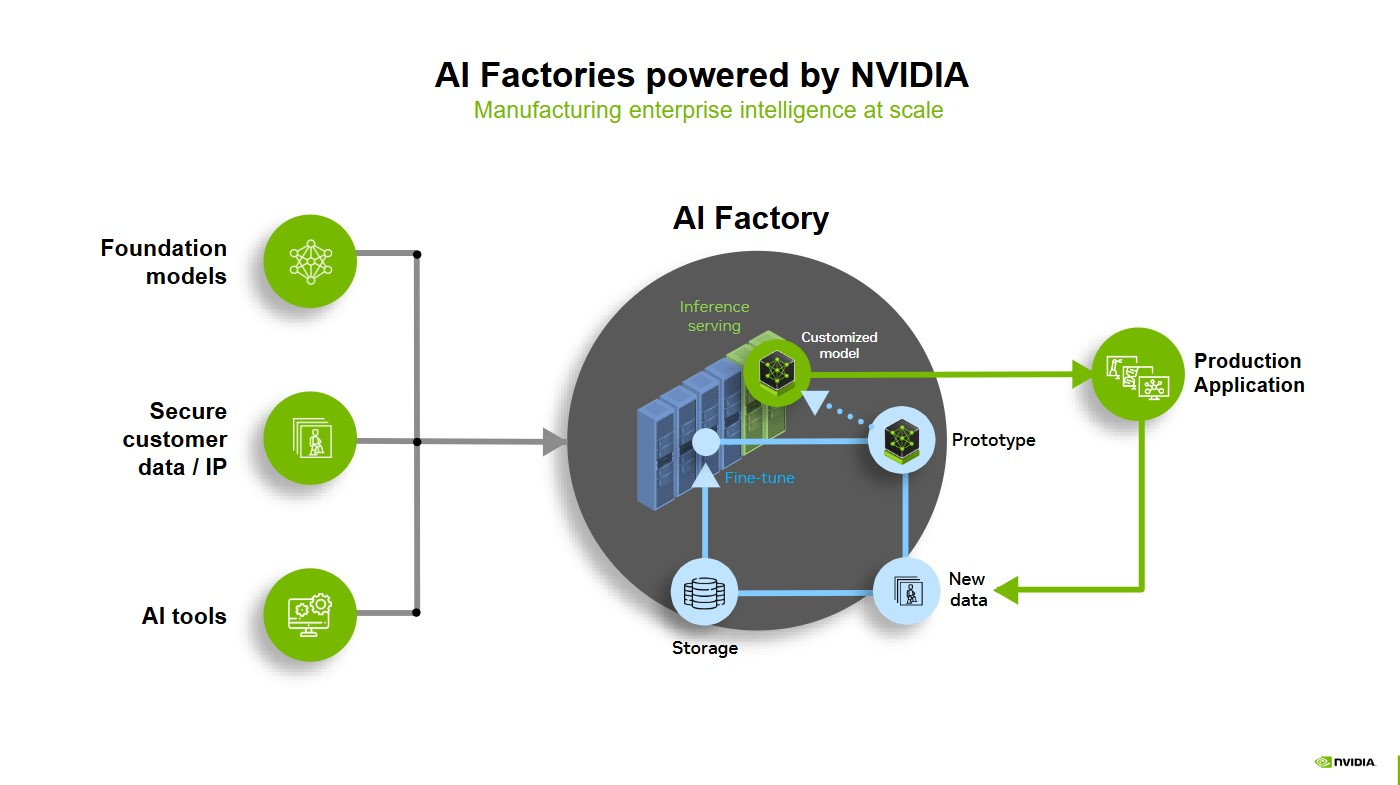
Como as fábricas de IA unificam todo o ciclo de vida da IA, esse sistema está melhorando continuamente: a inferência é registrada, os casos extremos são sinalizados para retreinamento e os loops de otimização se estreitam com o tempo: tudo sem intervenção manual, um exemplo de goodput em ação.
A empresa líder global em tecnologia de segurança, a Lockheed Martin construiu sua própria fábrica de IA para oferecer suporte a diversos usos em seus negócios. Por meio de seu Lockheed Martin AI Center, a empresa centralizou suas cargas de trabalho de IA generativa na NVIDIA DGX SuperPOD para treinar e personalizar modelos de IA, usar todo o poder da infraestrutura especializada e reduzir os custos indiretos dos ambientes de nuvem.
“Com nossa fábrica de IA local, lidamos com tokenização, treinamento e implantação internamente”, disse Greg Forrest, diretor de bases de IA da Lockheed Martin. “Nosso DGX SuperPOD nos ajuda a processar mais de 1 bilhão de tokens por semana, permitindo ajuste fino, geração aumentada por recuperação ou inferência em nossos grandes modelos de linguagem. Esta solução evita os custos crescentes e limitações significativas de taxas com base no uso de tokens.”
Tecnologias NVIDIA Full-Stack para Fábrica de IA
Uma fábrica de IA transforma a IA de uma série de experimentos isolados em um mecanismo escalável, repetível e confiável para inovação e valor comercial.
A NVIDIA fornece todos os componentes necessários para construir fábricas de IA, incluindo computação acelerada, GPUs de alto desempenho, rede de alta largura de banda e software otimizado.
As GPUs NVIDIA Blackwell, por exemplo, podem ser conectadas via rede, refrigeradas a líquido para eficiência energética e orquestradas com software de IA.
A plataforma de inferência de código aberto NVIDIA Dynamo oferece um sistema operacional para fábricas de IA. Ele foi desenvolvido para acelerar e dimensionar a IA com máxima eficiência e custo mínimo. Ao rotear, programar e otimizar de forma inteligente as solicitações de inferência, o Dynamo garante que cada ciclo de GPU garanta a utilização total, impulsionando a produção de tokens com desempenho máximo.
Os sistemas NVIDIA Blackwell GB200 NVL72 e a rede NVIDIA InfiniBand são adaptados para maximizar a taxa de transferência de token por watt, tornando a fábrica de IA altamente eficiente tanto do ponto de vista da taxa de transferência total quanto da baixa latência.
Ao validar soluções otimizadas e full-stack, as empresas podem criar e manter sistemas de IA de ponta com eficiência. Uma fábrica de IA full-stack ajuda as empresas a alcançar a excelência operacional, permitindo que elas aproveitem o potencial da IA com mais rapidez e confiança.
Saiba mais sobre como as fábricas de IA estão redefinindo os data centers e permitindo a próxima era da IA.