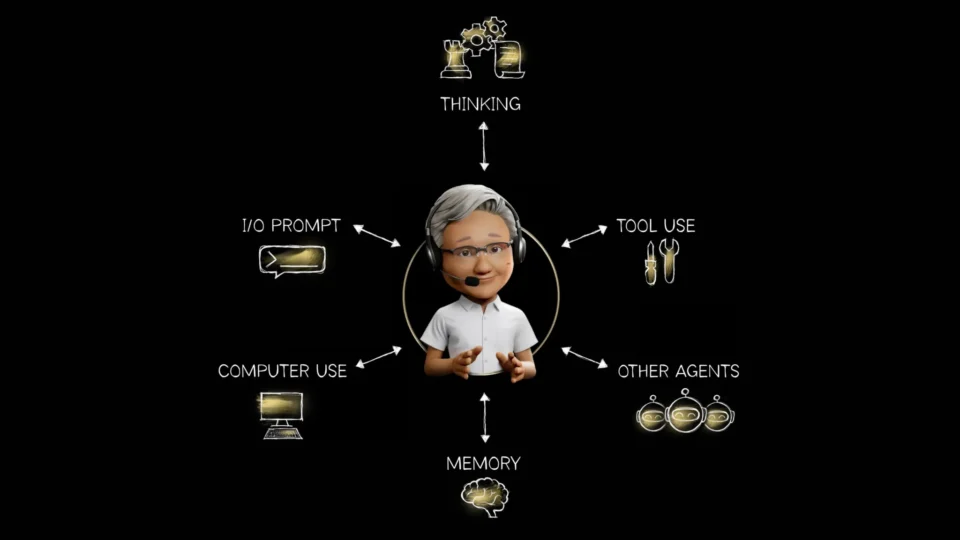
RAG Tradicional vs. Agente de RAG: Por Que os Agentes de IA Precisam de Conhecimento Dinâmico para Ficarem Mais Inteligentes
NVIDIA Anuncia DGX Cloud Lepton para Conectar Desenvolvedores ao Ecossistema Global de Computação da NVIDIA
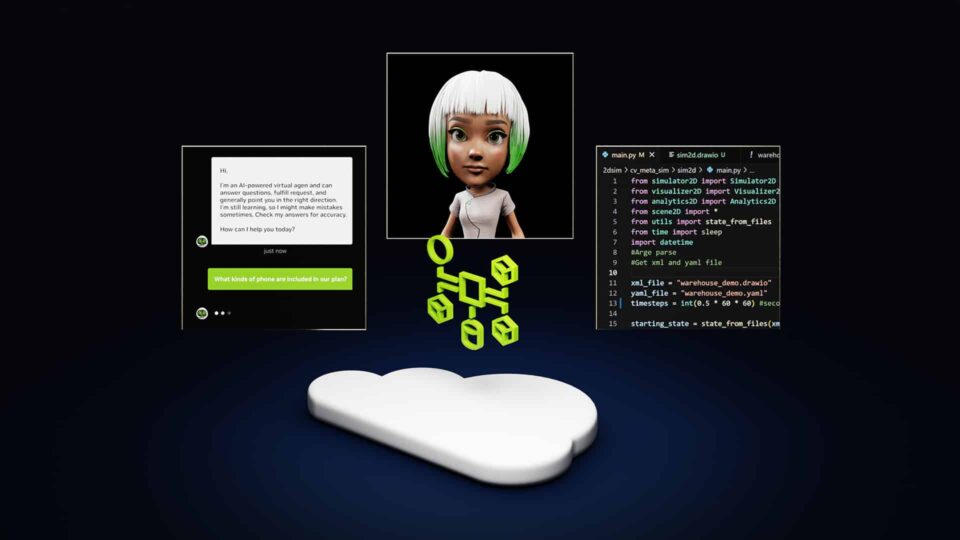
Três Passos Chaves para Criar Assistentes Virtuais de IA para Atendimento ao Cliente com um NVIDIA AI Blueprint
Turbinando o Desempenho do Meta Llama 3 com NVIDIA TensorRT-LLM e Servidor de Inferência NVIDIA Triton