Os microfones estavam ao vivo e a fita rolava no estúdio onde o Quinteto Miles Davis estava gravando dezenas de músicas em 1956 para a Prestige Records.
Quando um engenheiro perguntou o título da próxima música, Davis respondeu: “Vou tocar e depois digo qual é”.
Como o famoso trompetista e compositor de jazz, os pesquisadores têm gerado modelos de IA em um ritmo febril, explorando novas arquiteturas e casos de uso. Focados em abrir novos caminhos, eles às vezes deixam para outros a tarefa de categorizar seu trabalho.
Uma equipe de mais de cem pesquisadores de Stanford colaborou para fazer exatamente isso em um artigo de 214 páginas lançado no verão de 2021.
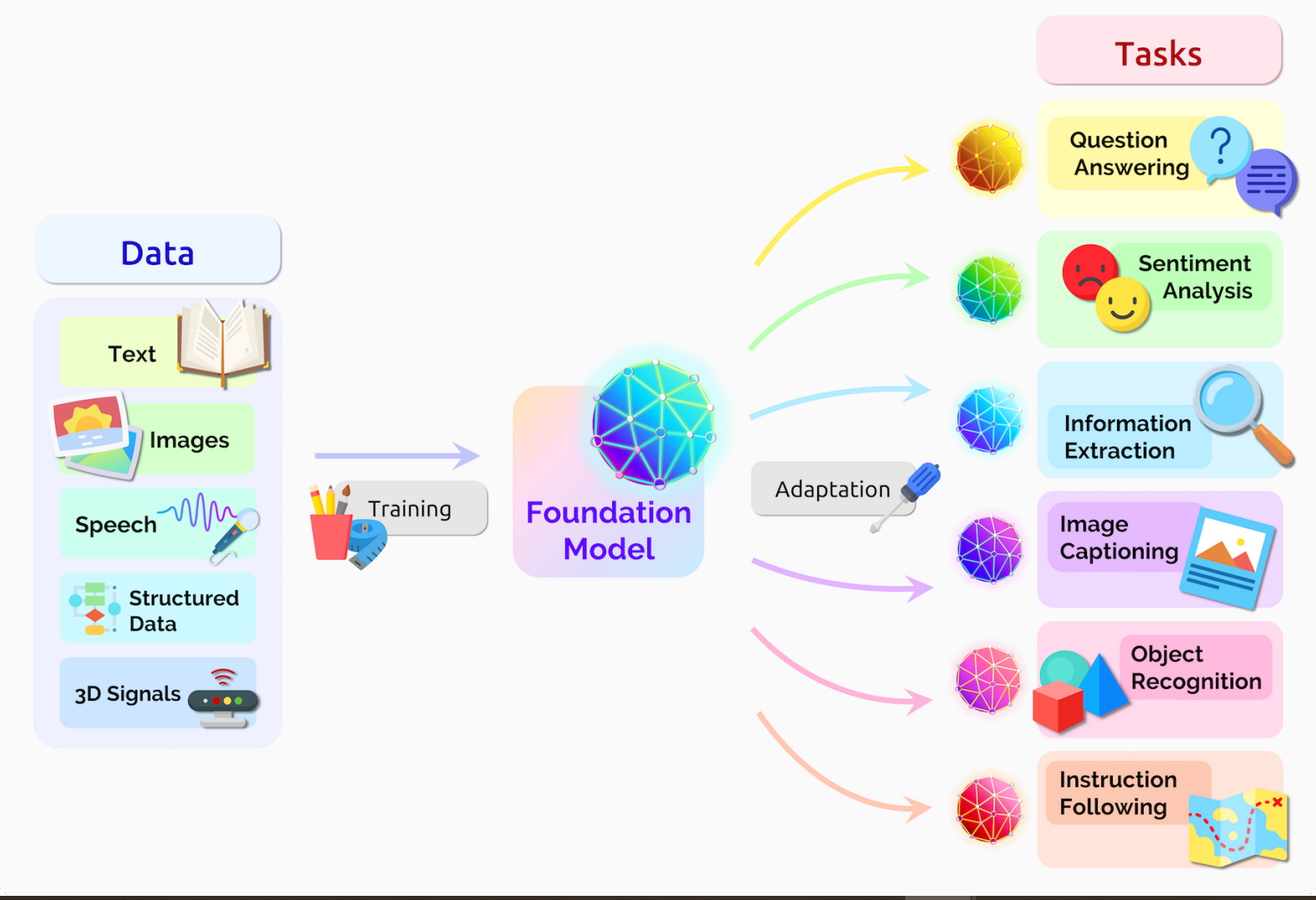
Eles disseram que modelos transformers, grandes modelos de linguagem (LLMs) e outras redes neurais que ainda estão sendo construídas fazem parte de uma nova categoria importante que eles apelidaram de modelos base.
Modelos Base Definidos
Um modelo base é uma rede neural de IA treinada em montanhas de dados brutos, geralmente com aprendizado não supervisionado, que pode ser adaptada para realizar uma ampla gama de tarefas, disse o artigo.
“A escala e o escopo dos modelos base dos últimos anos ampliaram nossa imaginação sobre o que é possível”, escreveram eles.
Dois conceitos importantes ajudam a definir essa categoria abrangente: a coleta de dados é mais fácil e as oportunidades são tão amplas quanto o horizonte.
Sem Rótulos, Mas com Muitas Oportunidades
Os modelos base geralmente aprendem com conjuntos de dados não rotulados, economizando tempo e gastos com a descrição manual de cada item em coleções massivas.
As redes neurais anteriores foram estreitamente ajustadas para tarefas específicas. Com um pouco de ajuste fino, os modelos base podem lidar com trabalhos desde a tradução de texto até a análise de imagens médicas.
Os modelos base estão demonstrando “comportamento impressionante” e estão sendo implantados em escala, disse o grupo no site de seu centro de pesquisa formado para estudá-los. Até agora, eles publicaram mais de 50 artigos sobre modelos base apenas de pesquisadores internos.
“Acho que descobrimos uma fração muito pequena das capacidades dos modelos base existentes, quanto mais dos futuros”, disse Percy Liang, diretor do centro, na palestra de abertura do primeiro workshop sobre modelos base.
Surgimento e Homogeneização da IA
Nessa palestra, Liang cunhou dois termos para descrever os modelos base:
Emergência refere-se a recursos de IA ainda sendo descobertos, como as muitas habilidades nascentes em modelos base. Ele chama a mistura de algoritmos de IA e homogeneização de arquiteturas de modelos, uma tendência que ajudou a formar modelos base. (Veja quadro abaixo.)
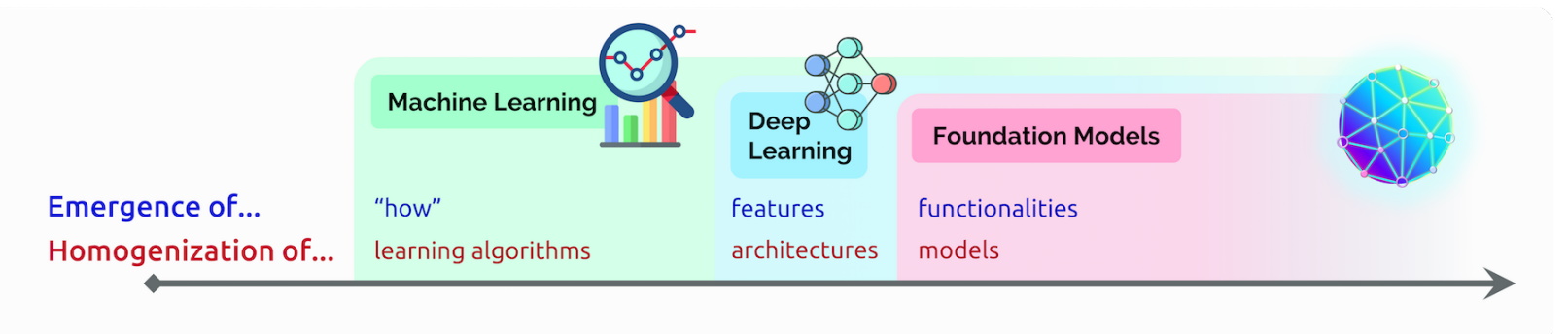
O campo continua a se mover rapidamente.
Um ano depois que o grupo definiu os modelos base, outros observadores de tecnologia cunharam um termo relacionado: IA generativa. É um termo genérico para transformers, grandes modelos de linguagem, modelos de difusão e outras redes neurais que capturam a imaginação das pessoas porque podem criar texto, imagens, música, software e muito mais.
A IA generativa tem o potencial de render trilhões de dólares em valor econômico, disseram os executivos da empresa de risco Sequoia Capital, que compartilharam suas opiniões em um recente podcast sobre IA.
Uma Breve História dos Modelos Base
“Estamos em uma época em que métodos simples, como redes neurais, estão nos dando uma explosão de novos recursos”, disse Ashish Vaswani, empresário e ex-cientista sênior de pesquisa do Google Brain, que liderou o trabalho no artigo seminal de 2017 sobre transformers.
Esse trabalho inspirou pesquisadores que criaram o BERT e outros grandes modelos de linguagem, tornando 2018 “um divisor de águas” para o processamento de linguagem natural, disse um relatório sobre IA no final daquele ano.
O Google lançou o BERT como software de código aberto, gerando uma família de sucessores e iniciando uma corrida para construir LLMs cada vez maiores e mais poderosos. Em seguida, aplicou a tecnologia em seu mecanismo de busca para que os usuários pudessem fazer perguntas em frases simples.
Em 2020, os pesquisadores da OpenAI anunciaram outro transformer de referência, o GPT-3. Em semanas, as pessoas o estavam usando para criar poemas, programas, músicas, sites e muito mais.
“Os modelos de linguagem têm uma ampla gama de aplicações benéficas para a sociedade”, escreveram os pesquisadores.
O trabalho deles também mostrou os quão grandes e intensivos em computação esses modelos podem ser. O GPT-3 foi treinado em um conjunto de dados com quase um trilhão de palavras e possui 175 bilhões de parâmetros, uma medida fundamental do poder e complexidade das redes neurais.
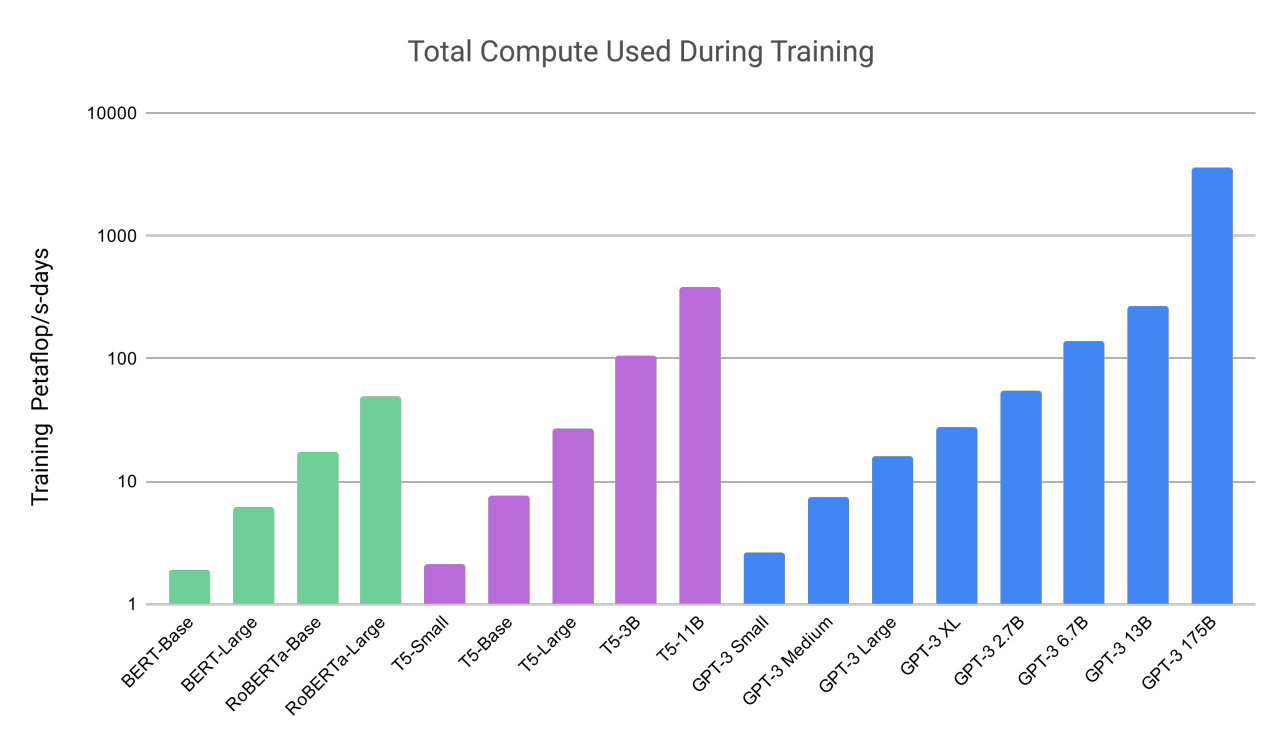
“Só me lembro de ter ficado impressionado com as coisas que ele poderia fazer”, disse Liang, falando sobre o GPT-3 em um podcast.
A última iteração, ChatGPT, treinada em 10.000 GPUs NVIDIA, é ainda mais envolvente, atraindo mais de 100 milhões de usuários em apenas dois meses. Seu lançamento foi considerado o momento do iPhone para IA porque ajudou muitas pessoas a ver como poderiam usar a tecnologia.

Do Texto às Imagens
Mais ou menos na mesma época em que o ChatGPT estreou, outra classe de redes neurais, chamadas de modelos de difusão, fez sucesso. Sua capacidade de transformar descrições de texto em imagens artísticas atraiu usuários casuais para criar imagens incríveis que se tornaram virais nas redes sociais.
O primeiro artigo a descrever um modelo de difusão chegou com pouco alarde em 2015. Mas, como os transformers, a nova técnica logo pegou fogo.
Os pesquisadores publicaram mais de 200 artigos sobre modelos de difusão no ano passado, de acordo com uma lista mantida por James Thornton, pesquisador de IA da Universidade de Oxford.
Em um tweet, o CEO da Midjourney, David Holz, revelou que seu serviço de texto para imagem baseado em difusão tem mais de 4,4 milhões de usuários. Servi-los requer mais de 10.000 GPUs NVIDIA principalmente para inferência de IA, disse ele em uma entrevista (assinatura necessária).
Dezenas de Modelos em Uso
Centenas de modelos base estão agora disponíveis. Um documento cataloga e classifica mais de 50 modelos transformers principais (veja a tabela abaixo).
O grupo de Stanford comparou 30 modelos base, observando que o campo está se movendo tão rápido que não revisou alguns novos e proeminentes.
A Startup NLP Cloud, membro do programa NVIDIA Inception que impulsiona startups de ponta, diz que usa cerca de 25 grandes modelos de linguagem em uma oferta comercial que atende companhias aéreas, farmácias e outros usuários. Os especialistas esperam que uma parcela crescente dos modelos seja de código aberto em sites como o hub de modelos do Hugging Face.
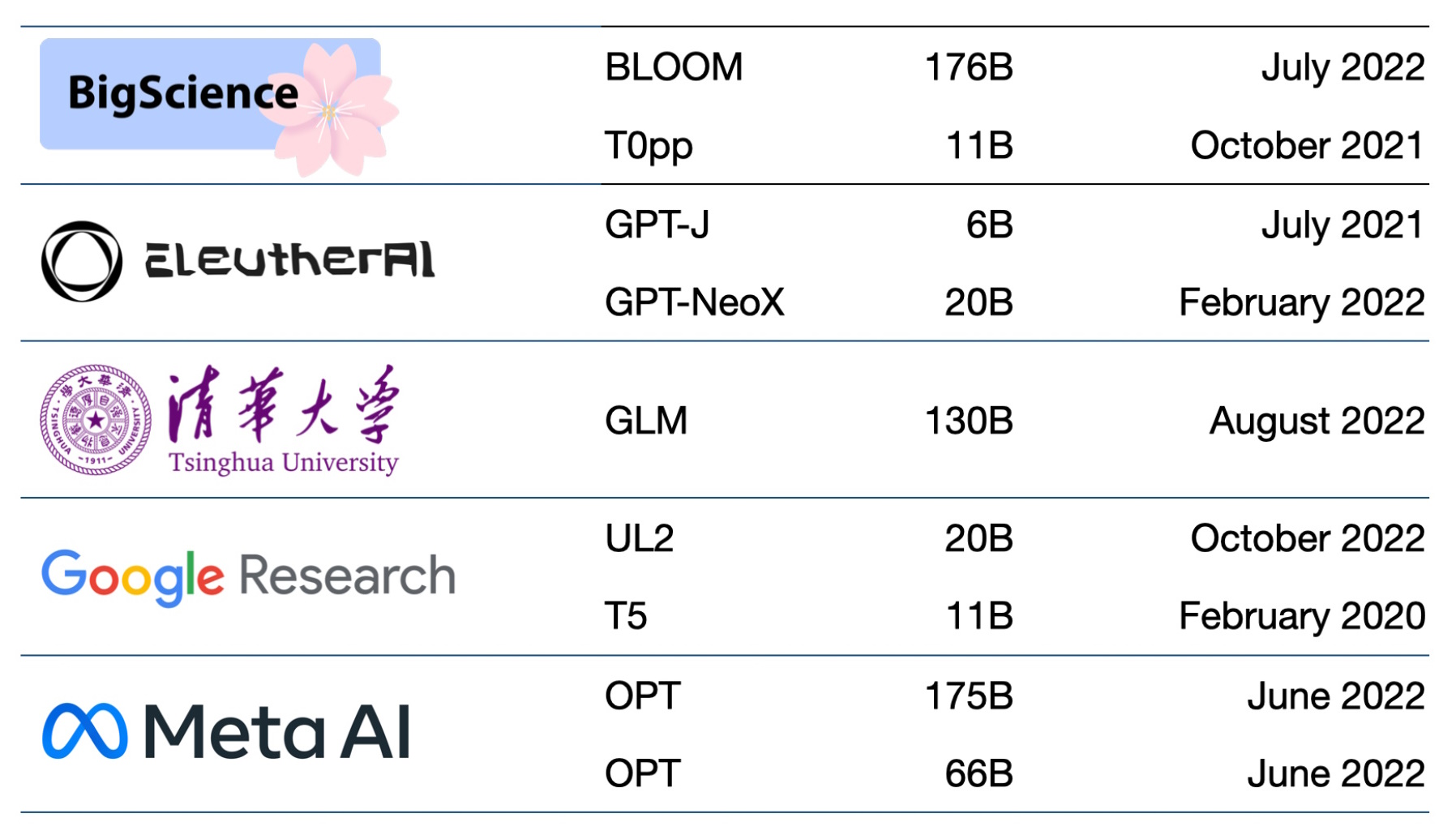
Os modelos base continuam ficando maiores e mais complexos também.
É por isso que, em vez de criar novos modelos do zero, muitas empresas já estão personalizando modelos de base pré-treinados para turbinar suas jornadas para a IA.
Base na Nuvem
Uma empresa de capital de risco lista 33 casos de uso para IA generativa, desde a geração de anúncios até a pesquisa semântica.
Os principais serviços de nuvem já usam modelos base há algum tempo. Por exemplo, o Microsoft Azure trabalhou com a NVIDIA para implementar um transformer para seu serviço Translator. Ajudou os trabalhadores do desastre a entender o Haitian Creole enquanto eles estavam respondendo a um terremoto de 7.0.
Em fevereiro, a Microsoft anunciou planos para aprimorar seu navegador e mecanismo de pesquisa com o ChatGPT e inovações relacionadas. “Pensamos nessas ferramentas como um co-piloto de IA para a web”, disse o anúncio.
O Google anunciou o Bard, um serviço experimental de IA conversacional. Ela planeja conectar muitos de seus produtos ao poder de seus modelos base, como LaMDA, PaLM, Imagen e MusicLM.
“IA é a tecnologia mais profunda em que estamos trabalhando hoje”, escreveu o blog da empresa.
As Startups Também Ganham Tração
A startup Jasper espera registrar US$ 75 milhões em receita anual de produtos que escrevem cópias para empresas como a VMware. Está liderando um campo de mais de uma dúzia de empresas que geram texto, incluindo Writer, um membro da NVIDIA Inception.
Outros membros do Inception no campo incluem rinna com sede em Tóquio, que criou chatbots usados por milhões no Japão. Em Tel Aviv, a Tabnine executa um serviço de IA generativa que automatiza até 30% do código escrito por um milhão de desenvolvedores em todo o mundo.
Uma Plataforma para a Área da Saúde
Os pesquisadores da startup Evozyne usaram modelos base no NVIDIA BioNeMo para gerar duas novas proteínas. Uma poderia tratar uma doença rara e a outra poderia ajudar a capturar carbono na atmosfera.
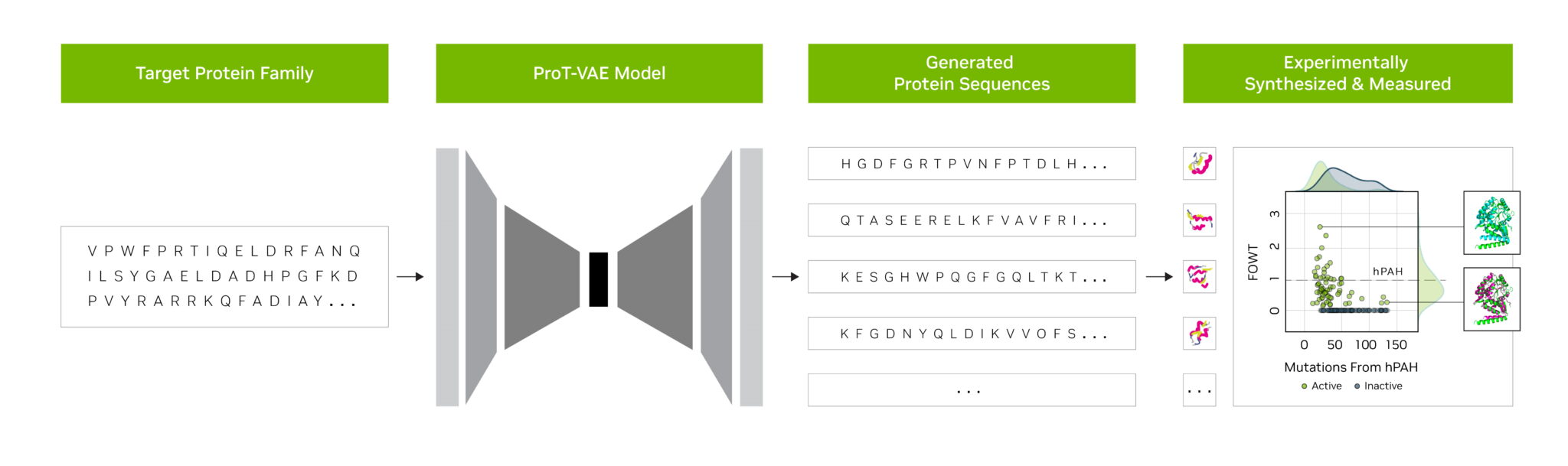
O BioNeMo, uma plataforma de software e serviço em nuvem para IA generativa na descoberta de medicamentos, oferece ferramentas para treinar, executar inferência e implantar modelos biomoleculares personalizados de IA. Ele inclui o MegaMolBART, um modelo de IA generativa para química desenvolvido pela NVIDIA e AstraZeneca.
“Assim como os modelos de linguagem IA podem aprender as relações entre as palavras em uma frase, nosso objetivo é que as redes neurais treinadas em dados de estrutura molecular sejam capazes de aprender as relações entre átomos em moléculas do mundo real”, disse Ola Engkvist, chefe de IA molecular, ciências da descoberta e P&D na AstraZeneca, quando o trabalho foi anunciado.
Separadamente, o centro de saúde acadêmico da Universidade da Flórida colaborou com pesquisadores da NVIDIA para criar o GatorTron. O grande modelo de linguagem visa extrair insights de grandes volumes de dados clínicos para acelerar a pesquisa médica.
Um centro de Stanford está aplicando os mais recentes modelos de difusão para aprimorar as imagens médicas. A NVIDIA também ajuda empresas de saúde e hospitais a usar IA em imagens médicas, acelerando o diagnóstico de doenças mortais.
Base de IA para Negócios
Outro novo framework, o framework NVIDIA NeMo, visa permitir que qualquer empresa crie seus próprios transformers de bilhões ou trilhões de parâmetros para alimentar chatbots personalizados, assistentes pessoais e outras aplicações de IA.
Ele criou o modelo Megatron-Turing Natural Language Generation (MT-NLG) de 530 bilhões de parâmetros que alimenta o TJ, o avatar Toy Jensen que deu parte da apresentação de abertura no NVIDIA GTC no ano passado.
Os modelos base, conectados a plataformas 3D como NVIDIA Omniverse, serão fundamentais para simplificar o desenvolvimento do metaverso, a evolução 3D da Internet. Esses modelos impulsionarão aplicações e ativos para entretenimento e usuários industriais.
Fábricas e armazéns já estão aplicando modelos base dentro de gêmeos digitais, simulações realistas que ajudam a encontrar maneiras mais eficientes de trabalhar.
Os modelos base podem facilitar o trabalho de treinamento de veículos autônomos e robôs que auxiliam humanos em fábricas e centros de logística. Eles também ajudam a treinar veículos autônomos criando ambientes realistas como o abaixo.
Novos usos para os modelos base surgem diariamente, assim como os desafios em aplicá-los.
Vários artigos sobre modelos básicos de IA generativa descrevendo riscos como:
- amplificação do viés implícito nos conjuntos de dados massivos usados para treinar modelos,
- introduzir informações imprecisas ou enganosas em imagens ou vídeos, e
- violar direitos de propriedade intelectual de obras existentes.
“Dado que os futuros sistemas de IA provavelmente dependerão fortemente de modelos base, é imperativo que nós, como comunidade, nos reunamos para desenvolver princípios mais rigorosos para modelos base e orientação para seu desenvolvimento e implantação responsáveis”, disse o artigo de Stanford sobre modelos base.
As ideias atuais para salvaguardas incluem prompts de filtragem e suas saídas, recalibração de modelos em tempo real e limpeza de conjuntos de dados massivos.
“Essas são questões nas quais estamos trabalhando como uma comunidade de pesquisa”, disse Bryan Catanzaro, vice-presidente de pesquisa de deep learning aplicada da NVIDIA. “Para que esses modelos sejam realmente amplamente implantados, temos que investir muito em segurança.”
É mais um campo que os pesquisadores e desenvolvedores de IA estão arando enquanto criam o futuro.