Nota do editor: Esta postagem faz parte de nossa série IA Decodificada, que visa desmistificar a IA, tornando a tecnologia mais acessível, ao mesmo tempo em que apresenta novos hardware, software, ferramentas e acelerações para usuários de PCs e estações de trabalho RTX.
Se a IA está tendo seu momento no iPhone, então os chatbots são um de seus primeiros aplicativos populares.
Eles são possíveis graças a grandes modelos de linguagem , algoritmos de aprendizagem profunda pré-treinados em enormes conjuntos de dados – tão extensos quanto a própria Internet – que podem reconhecer, resumir, traduzir, prever e gerar texto e outras formas de conteúdo. Eles podem ser executados localmente em PCs e estações de trabalho com GPUs NVIDIA GeForce e RTX .
Os LLMs são excelentes em resumir grandes volumes de texto, classificar e extrair dados para obter insights e gerar novo texto em um estilo, tom ou formato especificado pelo usuário. Eles podem facilitar a comunicação em qualquer idioma, mesmo além daqueles falados por humanos, como códigos de computador ou proteínas e sequências genéticas.
Enquanto os primeiros LLMs tratavam apenas de texto, as iterações posteriores foram treinadas em outros tipos de dados. Esses LLMs multimodais podem reconhecer e gerar imagens, áudio, vídeos e outras formas de conteúdo.
Chatbots como o ChatGPT foram um dos primeiros a trazer LLMs para um público consumidor, com uma interface familiar construída para conversar e responder a solicitações em linguagem natural. Desde então, os LLMs têm sido usados para ajudar os desenvolvedores a escrever códigos e os cientistas a impulsionar a descoberta de medicamentos e o desenvolvimento de vacinas.
Mas os modelos de IA que alimentam essas funções são computacionalmente intensivos. A combinação de técnicas avançadas de otimização e algoritmos como quantização com GPUs RTX, que são desenvolvidas especificamente para IA, ajuda a tornar os LLMs compactos o suficiente e os PCs poderosos o suficiente para serem executados localmente – sem necessidade de conexão com a Internet. E uma nova geração de LLMs leves como o Mistral — um dos LLMs que alimentam o Chat com RTX — prepara o terreno para desempenho de última geração com menores demandas de energia e armazenamento.
Por que os LLMs são importantes?
Os LLMs podem ser adaptados para uma ampla variedade de casos de uso, setores e fluxos de trabalho. Essa versatilidade, combinada com seu desempenho de alta velocidade, oferece ganhos de desempenho e eficiência em praticamente todas as tarefas baseadas em linguagem.
LLMs são amplamente usados em aplicativos de tradução de idiomas, como o DeepL , que usa IA e aprendizado de máquina para fornecer resultados precisos.
Pesquisadores médicos estão treinando LLMs em livros didáticos e outros dados médicos para melhorar o atendimento ao paciente. Os varejistas estão aproveitando chatbots com tecnologia LLM para oferecer experiências excelentes de suporte ao cliente. Os analistas financeiros estão recorrendo aos LLMs para transcrever e resumir ligações sobre ganhos e outras reuniões importantes. E isso é apenas a ponta do iceberg.
Chatbots – como o Chat with RTX – e assistentes de redação construídos sobre LLMs estão deixando sua marca em todas as facetas do trabalho de conhecimento, desde marketing de conteúdo e redação até operações jurídicas. Os assistentes de codificação estavam entre os primeiros aplicativos baseados em LLM a apontar para o futuro do desenvolvimento de software assistido por IA. Agora, projetos como o ChatDev estão combinando LLMs com agentes de IA – bots inteligentes que agem de forma autônoma para ajudar a responder perguntas ou executar tarefas digitais – para criar uma empresa de software virtual sob demanda. Basta informar ao sistema que tipo de aplicativo é necessário e vê-lo funcionar.
Saiba mais sobre os agentes LLM no blog do desenvolvedor NVIDIA.
Fácil como iniciar uma conversa
O primeiro encontro de muitas pessoas com IA generativa ocorreu por meio de um chatbot como o ChatGPT, que simplifica o uso de LLMs por meio de linguagem natural, tornando a ação do usuário tão simples quanto dizer ao modelo o que fazer.
Os chatbots com tecnologia LLM podem ajudar a gerar um rascunho de texto de marketing, oferecer ideias para férias, elaborar um e-mail para o atendimento ao cliente e até mesmo criar poesia original.
Os avanços na geração de imagens e nos LLMs multimodais ampliaram o domínio do chatbot para incluir a análise e geração de imagens — tudo isso mantendo a experiência do usuário maravilhosamente simples. Basta descrever uma imagem para o bot ou fazer upload de uma foto e pedir ao sistema para analisá-la. Está conversando, mas agora com recursos visuais.
Para saber mais sobre como esses bots são projetados, confira o webinar sob demanda sobre Construindo chatbots de IA inteligentes usando RAG .
Os avanços futuros ajudarão os LLMs a expandir sua capacidade de lógica, raciocínio, matemática e muito mais, dando-lhes a capacidade de dividir solicitações complexas em subtarefas menores.
Também estão sendo feitos progressos em agentes de IA, aplicações capazes de receber solicitações complexas, dividi-las em solicitações menores e interagir de forma autônoma com LLMs e outros sistemas de IA para concluí-las. ChatDev é um exemplo de estrutura de agente de IA, mas os agentes não estão limitados a tarefas técnicas.
Por exemplo, os usuários podem pedir a um agente de viagens pessoal de IA que reserve férias com a família no exterior. O agente dividiria essa tarefa em subtarefas – planejamento de itinerário, reserva de viagens e hospedagem, criação de listas de embalagem, localização de um passeador de cães – e as executaria de forma independente e em ordem.
Desbloqueie dados pessoais com RAG
Por mais poderosos que sejam os LLMs e os chatbots para uso geral, eles podem se tornar ainda mais úteis quando combinados com os dados de um usuário individual. Ao fazer isso, eles podem ajudar a analisar caixas de entrada de e-mail para descobrir tendências, vasculhar manuais de usuário densos para encontrar a resposta a uma pergunta técnica sobre algum hardware ou resumir anos de extratos bancários e de cartão de crédito.
A geração aumentada de recuperação , ou RAG, é uma das maneiras mais fáceis e eficazes de aprimorar LLMs para um conjunto de dados específico.
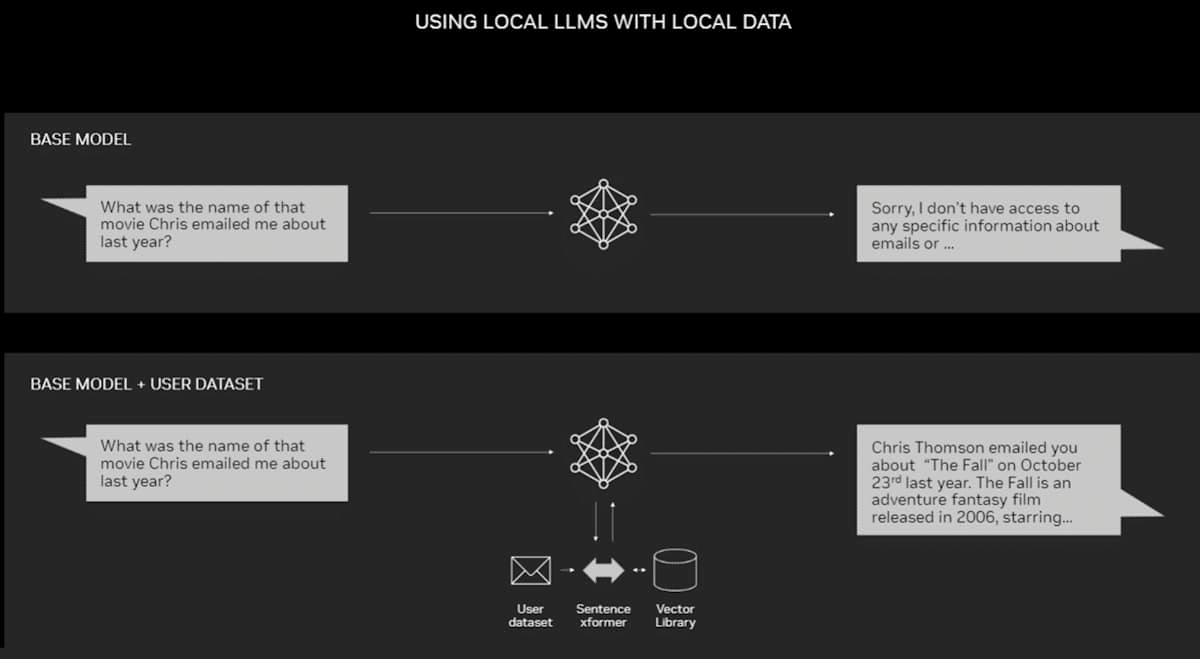
O RAG aumenta a precisão e a confiabilidade dos modelos generativos de IA com fatos obtidos de fontes externas. Ao conectar um LLM a praticamente qualquer recurso externo, o RAG permite que os usuários conversem com repositórios de dados, ao mesmo tempo que dá ao LLM a capacidade de citar suas fontes. A experiência do usuário é tão simples quanto apontar o chatbot para um arquivo ou diretório.
Por exemplo, um LLM padrão terá conhecimento geral sobre as melhores práticas de estratégia de conteúdo, táticas de marketing e insights básicos sobre um determinado setor ou base de clientes. Mas conectá-lo via RAG a ativos de marketing que apoiam o lançamento de um produto permitiria analisar o conteúdo e ajudaria a planejar uma estratégia personalizada.
RAG funciona com qualquer LLM, pois o aplicativo oferece suporte. A demonstração técnica Chat with RTX da NVIDIA é um exemplo de RAG conectando um LLM a um conjunto de dados pessoais. Ele é executado localmente em sistemas com GPU profissional GeForce RTX ou NVIDIA RTX.
Para saber mais sobre o RAG e como ele se compara ao ajuste fino de um LLM, leia o blog de tecnologia RAG 101: Retrieval-Augmented Generation Questions Answered .
Experimente a velocidade e a privacidade do bate-papo com RTX
Chat com RTX é uma demonstração de chatbot local e personalizada, fácil de usar e gratuita para download . É construído com funcionalidade RAG e aceleração TensorRT-LLM e RTX. Ele suporta vários LLMs de código aberto, incluindo Meta’s Llama 2 e Mistral’s Mistral. O suporte para Gemma do Google chegará em uma atualização futura.
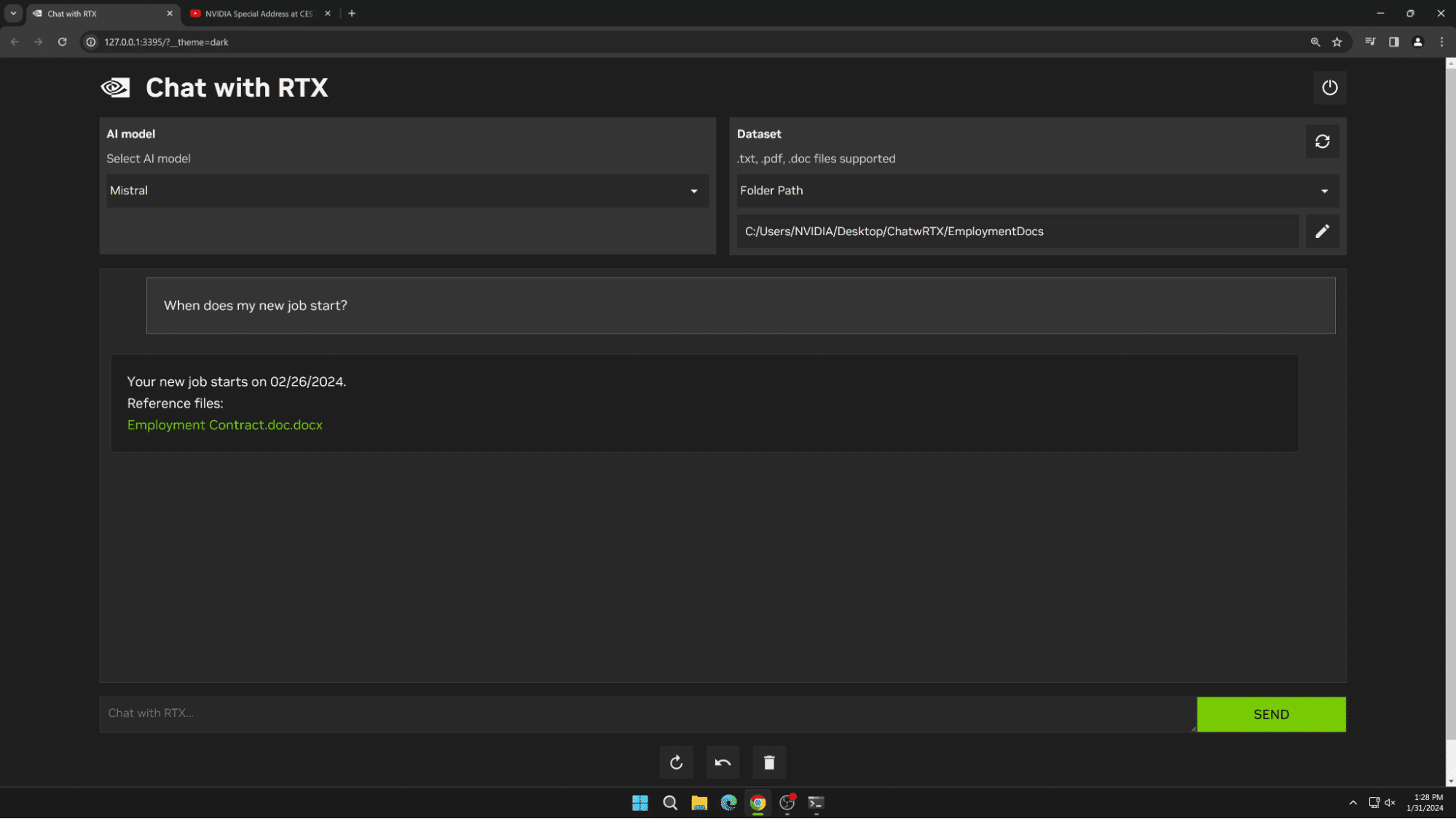
Os usuários podem conectar facilmente arquivos locais em um PC a um LLM compatível simplesmente colocando os arquivos em uma pasta e apontando a demonstração para esse local. Isso permite responder a perguntas com respostas rápidas e contextualmente relevantes.
Como o Chat with RTX é executado localmente no Windows com PCs GeForce RTX e estações de trabalho NVIDIA RTX, os resultados são rápidos e os dados do usuário permanecem no dispositivo. Em vez de depender de serviços baseados em nuvem, o Chat with RTX permite que os usuários processem dados confidenciais em um PC local sem a necessidade de compartilhá-los com terceiros ou de ter uma conexão com a Internet.
Para saber mais sobre como a IA está moldando o futuro, assista ao NVIDIA GTC , uma conferência global para desenvolvedores de IA que acontecerá de 18 a 21 de março em San Jose, Califórnia, e on-line.