Muitos usuários desejam executar Large Language Models ou Modelos de Linguagem de Grande Porte (as LLMs) localmente para obter mais privacidade e controle, sem assinaturas, mas, até recentemente, isso significava uma perda na qualidade da saída. Os recém-lançados open-weight models, como o gpt-oss da OpenAI e o Qwen 3 da Alibaba, podem ser executados diretamente em PCs, fornecendo saídas úteis de alta qualidade, especialmente para IA local com agentes.
Isso abre novas oportunidades para estudantes, amadores e desenvolvedores explorarem aplicações de IA generativa localmente. Os PCs NVIDIA com RTX aceleram essas experiências, oferecendo IA rápida e ágil aos usuários.
Introdução aos LLMs locais otimizados para PCs com RTX
A NVIDIA trabalhou para otimizar as principais aplicações LLM para PCs RTX, extraindo o desempenho máximo dos Tensor Cores em GPUs RTX.
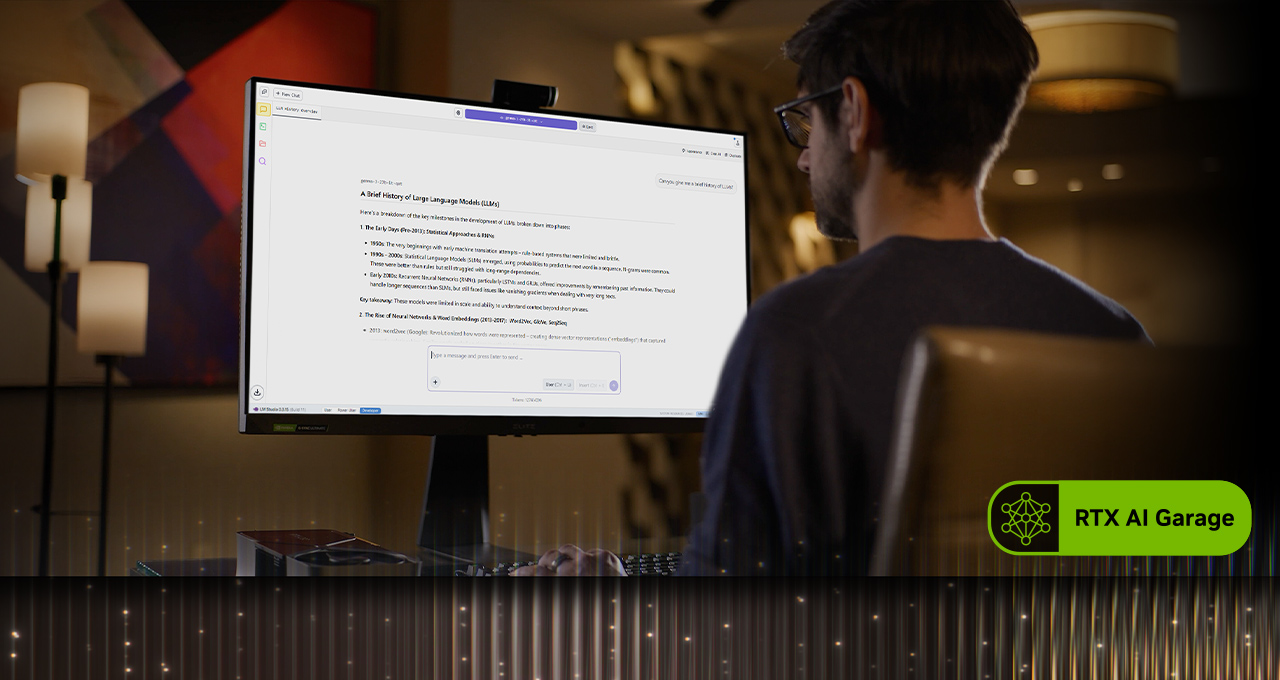
Uma das maneiras mais fáceis de começar a usar IA em um PC é com o Ollama, uma ferramenta de código aberto que oferece uma interface simples para executar e interagir com LLMs. Ele permite arrastar e soltar PDFs em prompts, bate-papos e fluxos de trabalho de compreensão multimodal que incluem texto e imagens.
- Melhorias de desempenho em GPUs GeForce RTX para o modelo gpt-oss-20B da OpenAI e os modelos Gemma 3 do Google
- Suporte para os novos modelos Gemma 3 270M e EmbeddingGemma3 para geração aumentada de recuperação hipereficiente em PC RTX com IA
- Sistema de agendamento de modelos aprimorado para maximizar e relatar com precisão a utilização da memória
- Melhorias de estabilidade e multi-GPU
Ollama é um framework de desenvolvimento que pode ser usado com outras aplicações. Por exemplo, o AnythingLLM — um aplicativo de código aberto que permite aos usuários criar seus próprios assistentes de IA com qualquer LLM — pode ser executado no Ollama e se beneficiar de todas as suas acelerações.
Entusiastas também podem começar a usar LLMs locais usando o LM Studio, uma aplicação desenvolvida com o popular framework llama.cpp. A aplicação oferece uma interface amigável para executar modelos localmente, permitindo que os usuários carreguem diferentes LLMs, conversem com eles em tempo real e até mesmo os utilizem como endpoints de interface de programação de aplicações locais para integração em projetos personalizados.
- Suporte para o mais recente modelo NVIDIA Nemotron Nano v2 9B, que é baseado na nova arquitetura híbrida-mamba
- O Flash Attention agora está ativado por padrão, oferecendo uma melhoria de desempenho de até 20% em comparação com o Flash Attention desativado
- Otimizações de kernels CUDA para RMS Norm e módulo baseado em fast-div, resultando em melhorias de desempenho de até 9% para modelos populares
- Controle de versão semântico, facilitando a adoção de versões futuras pelos desenvolvedores
Saiba mais sobre o gpt-oss no RTX e como a NVIDIA trabalhou com o LM Studio para acelerar o desempenho do LLM em PCs com RTX.
Criando um companheiro de estudo com tecnologia de IA com AnythingLLM
Além de maior privacidade e desempenho, a execução local de LLMs remove restrições sobre quantos arquivos podem ser carregados ou por quanto tempo eles permanecem disponíveis, permitindo conversas de IA com reconhecimento de contexto por um período mais longo. Isso cria mais flexibilidade para a criação de assistentes conversacionais e generativos com IA.
Para os alunos, gerenciar uma enxurrada de slides, anotações, laboratórios e provas anteriores pode ser uma tarefa árdua. LLMs locais possibilitam a criação de um tutor personalizado que se adapta às necessidades individuais de aprendizagem.
A demonstração abaixo mostra como os alunos podem usar LLMs locais para criar um assistente com tecnologia de IA generativa:
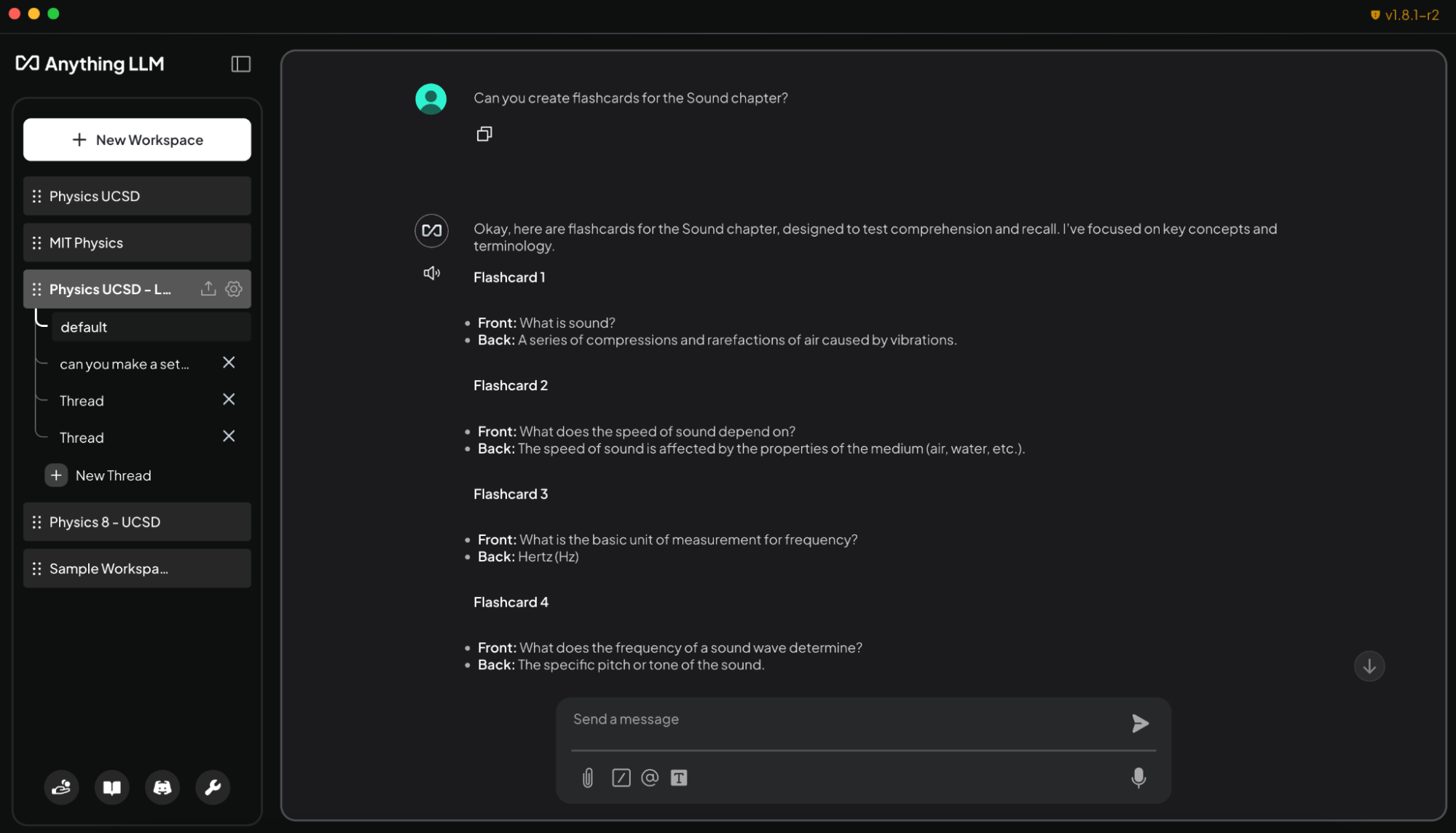
Ao carregar programas, tarefas e livros didáticos no AnythingLLM em PCs RTX, os alunos podem obter um companheiro de estudo adaptável e interativo. Eles podem pedir ajuda ao agente, usando texto simples ou fala, para realizar tarefas como:
- Gerando flashcards a partir de slides de aula: “Crie flashcards a partir dos slides de aula do capítulo sobre Som. Coloque os termos-chave de um lado e as definições do outro.”
- Fazendo perguntas contextuais relacionadas aos seus materiais: “Explique a conservação do momento usando minhas anotações de Física 8.”
- Criação e correção de questionários para preparação para exames: “Criar um questionário de múltipla escolha com 10 questões baseado nos capítulos 5 e 6 do meu livro de química e corrigir minhas respostas.”
- Analisando problemas difíceis passo a passo: “Mostre-me como resolver o problema 4 da minha tarefa de codificação, passo a passo.”
Além da sala de aula, amadores e profissionais podem usar o AnythingLLM para se preparar para certificações em novas áreas de estudo ou para outros fins semelhantes. E a execução local em GPUs RTX garante respostas rápidas e privadas, sem custos de assinatura ou limites de uso.
O Projeto G-Assist agora pode controlar as configurações do Notebook
O Project G-Assist é um assistente de IA experimental que ajuda os usuários a ajustar, controlar e otimizar seus PCs gamer por meio de comandos simples de voz ou texto, sem precisar vasculhar menus. No próximo dia, uma nova atualização do G-Assist será lançada na página inicial do NVIDIA App.
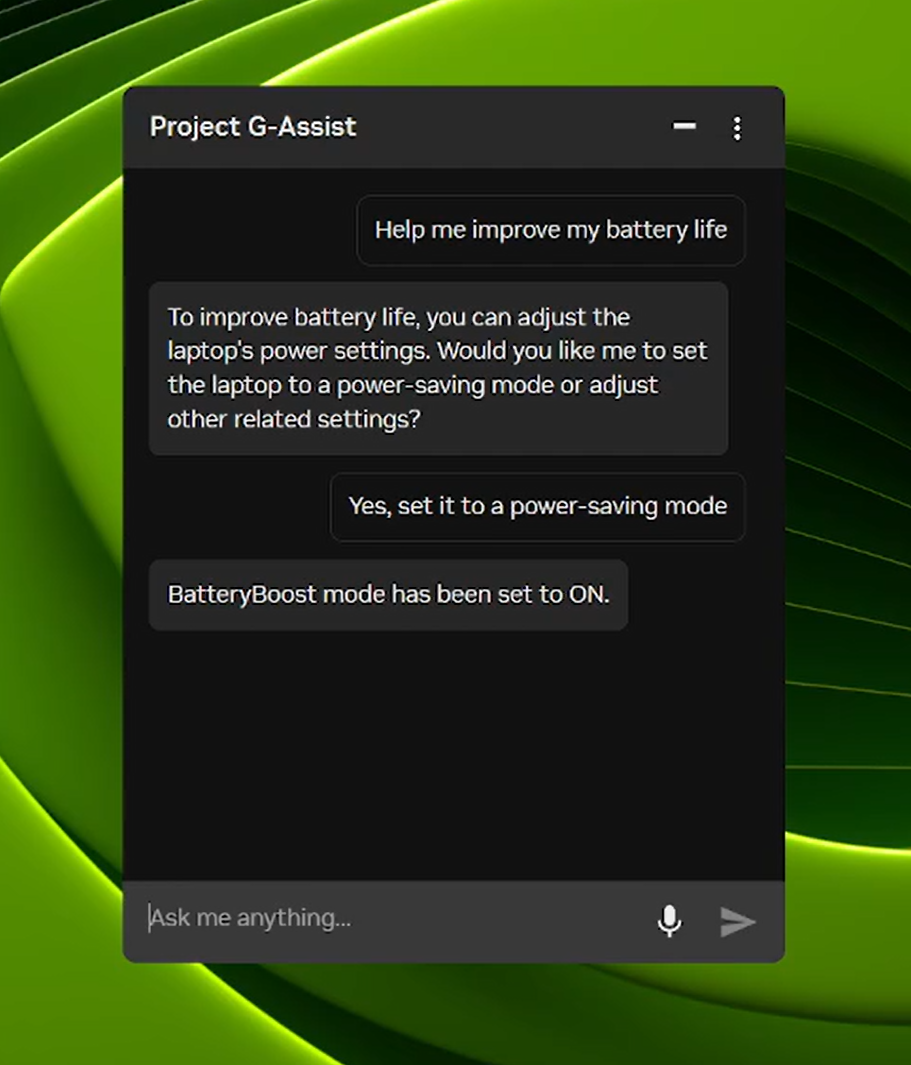
- Perfis de aplicações otimizados para Notebooks: ajuste automaticamente jogos ou aplicações para eficiência, qualidade ou equilíbrio quando os Notebooks não estiverem conectados a carregadores.
- Controle do BatteryBoost: ative ou ajuste o BatteryBoost para estender a vida útil da bateria, mantendo as taxas de quadros suaves.
- Controle WhisperMode: reduza o ruído das fans em até 50% quando necessário e retorne ao desempenho máximo quando não for mais necessário.
O Project G-Assist também é extensível. Com o G-Assist Plug-In Builder, os usuários podem criar e personalizar as funcionalidades do G-Assist adicionando novos comandos ou conectando ferramentas externas com plugins fáceis de criar. E com o G-Assist Plug-In Hub , os usuários podem facilmente descobrir e instalar plugins para expandir os recursos do G-Assist.
Confira o repositório G-Assist do GitHub da NVIDIA para obter materiais sobre como começar, incluindo plug-ins de amostra, instruções passo a passo e documentação para criar funcionalidades personalizadas.
#ICYMI — Os últimos avanços em PCs RTX com IA
 Ollama obtém um grande aumento de desempenho com RTX
Ollama obtém um grande aumento de desempenho com RTX
As atualizações mais recentes incluem desempenho otimizado para gpt-oss-20B da OpenAI, modelos Gemma 3 mais rápidos e agendamento de modelos mais inteligente para reduzir problemas de memória e melhorar a eficiência de múltiplas GPUs.
 Llama.cpp e GGML otimizados para RTX
Llama.cpp e GGML otimizados para RTX
As atualizações mais recentes oferecem inferência mais rápida e eficiente em GPUs RTX, incluindo suporte para o modelo NVIDIA Nemotron Nano v2 9B, Flash Attention habilitado por padrão e otimizações de kernel CUDA.
 Atualização do Project G-Assist lançada
Atualização do Project G-Assist lançada
Baixe a atualização do G-Assist v0.1.18 pelo NVIDIA App. A atualização traz novos comandos para usuários de Notebook e qualidade de resposta aprimorada.
 Windows ML com NVIDIA TensorRT com RTX já está disponível para todos
Windows ML com NVIDIA TensorRT com RTX já está disponível para todos
A Microsoft lançou o Windows ML com NVIDIA TensorRT para aceleração RTX, oferecendo inferência até 50% mais rápida, implantação simplificada e suporte para LLMs, difusão e outros tipos de modelos em PCs com Windows 11.
 NVIDIA Nemotron impulsiona o desenvolvimento de IA
NVIDIA Nemotron impulsiona o desenvolvimento de IA
A coleção NVIDIA Nemotron de modelos abertos, conjuntos de dados e técnicas está impulsionando a inovação em IA, desde o raciocínio generalizado até aplicações específicas do setor.
Conecte-se ao NVIDIA AI PC no Facebook, Instagram, TikTok e X e mantenha-se informado assinando a newsletter de PCs RTX com IA.
Siga a NVIDIA Workstation no LinkedIn e no X.
Veja o aviso sobre informações do produto de software.