
É importante considerar o desempenho da inferência ao implantar, integrar ou comparar qualquer framework de grande modelo de linguagem (LLM). Você precisa ter certeza de ajustar o framework escolhido e seus recursos para que ela forneça as métricas de desempenho que são importantes para sua aplicação.
O TensorRT-LLM, o mecanismo de inferência de IA de código aberto da NVIDIA, permite implantar modelos com suas ferramentas nativas de benchmarking e veiculação e possui uma ampla variedade de recursos que você pode ajustar. Nesta postagem, forneceremos um guia prático sobre como ajustar um modelo com trtllm-bench e, em seguida, implantar usando trtllm-serve.
Como Fazer Benchmarking com trtllm-bench
trtllm-bench é o utilitário baseado em Python do TensorRT-LLM para comparar modelos diretamente sem a sobrecarga de uma implantação de inferência completa. Isso simplifica a geração rápida de insights sobre o desempenho do modelo. O trtllm-bench configura internamente o motor com configurações ideais que geralmente fornecem bom desempenho.
Configurar Seu Ambiente de GPU
O benchmarking começa com um ambiente de GPU configurado corretamente. Para restaurar suas GPUs para suas configurações padrão, execute:

Para consultar o uso máximo da GPU:
![]()
Se você quiser definir um limite de potência específico (ou definir o máximo), execute:
![]()
Para obter mais detalhes, consulte a documentação do trtllm-bench.
Preparar Um Conjunto de Dados
Você pode preparar um conjunto de dados sintético usando prepare_dataset ou criar um conjunto de dados próprio usando o formato especificado em nossa documentação. Para um conjunto de dados personalizado, você pode formatar um arquivo JSON Lines (jsonl) com uma carga configurada em cada linha. Um exemplo de uma única entrada de conjunto de dados está abaixo:
![]()
Para os fins desta postagem, fornecemos um exemplo de saída com base em um conjunto de dados sintético com um ISL/OSL de 128/128.
Executar Benchmarks
Para executar benchmarks usando trtllm-bench, você pode usar o subcomando trtllm-bench throughput. Executando um benchmark usando o fluxo do PyTorch, basta executar o seguinte comando em um ambiente com o TensorRT-LLM instalado:

O comando de taxa de transferência extrairá automaticamente o ponto de verificação de HuggingFace (se não estiver armazenado em cache) e inicializará o TRT-LLM com o fluxo PyTorch. Os resultados serão salvos em results.json e impressos no terminal da seguinte forma assim que a execução for concluída:
Observação: esta é apenas uma amostra da saída e não representa declarações de desempenho.
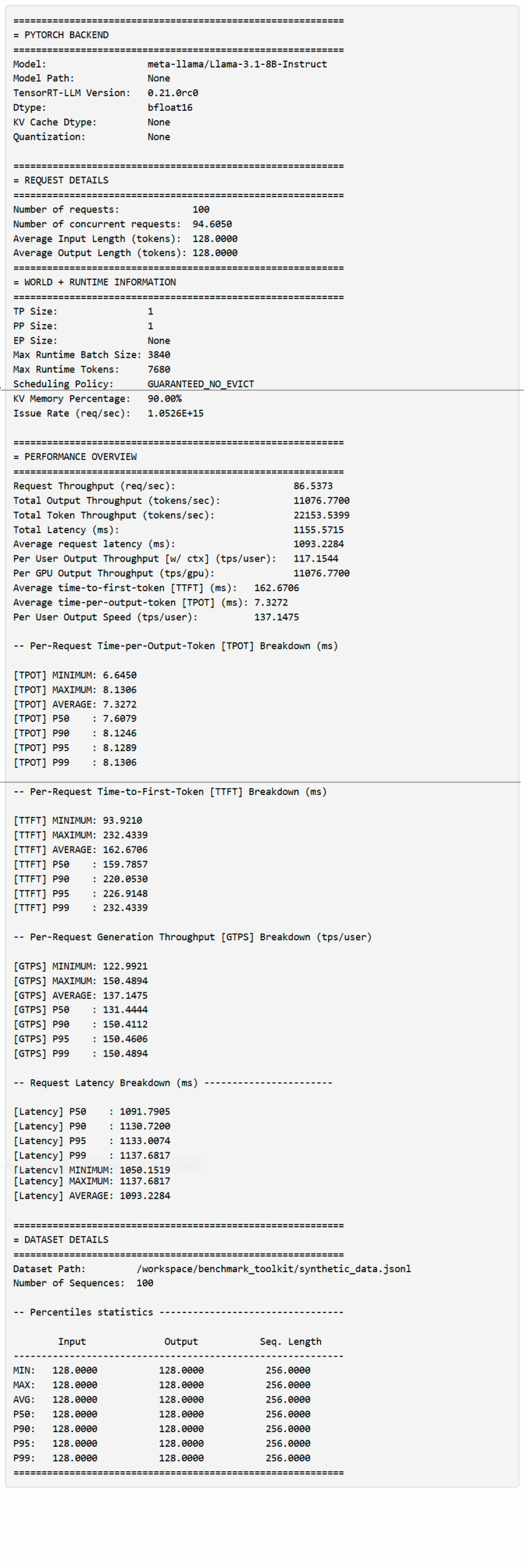
Analise os Resultados de Desempenho
Ao executar o comando acima, as estatísticas primárias são exibidas na seção PERFORMANCE OVERVIEW. Antes de entrarmos em detalhes, aqui estão algumas terminologias úteis:
- Output no contexto da visão geral significa todos os tokens de saída gerados (incluindo tokens de contexto)
- Total Token significa o comprimento total da sequência gerada (ISL+OSL)
- Per user, TTFT e TPOT assumem a perspectiva de que cada solicitação é um “usuário”; essas estatísticas são usadas para formar uma distribuição.
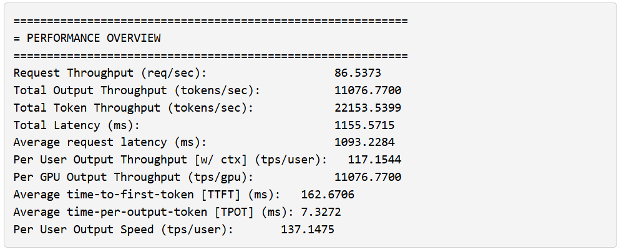
Você também notará que trtllm-bench relata o número máximo de tokens e o tamanho do lote.
Eles têm um significado particular no contexto do TensorRT-LLM:
- O número máximo de tokens refere-se ao número máximo de tokens que o próprio mecanismo pode manipular em uma iteração em lote. Esse limite inclui a soma de todos os tokens de entrada para todas as solicitações de contexto e um único token para a soma de todas as solicitações de geração no lote.
- O tamanho máximo do lote é o número máximo de solicitações permitidas em um lote. Digamos que sua iteração contenha uma solicitação com contexto de comprimento 128, quatro solicitações de geração (total de 132 tokens) e você definiu o máximo de tokens como 512 com um tamanho máximo de lote de cinco solicitações. Nesse caso, seu mecanismo será limitado ao tamanho do lote, mesmo que não tenha atendido ao máximo de tokens.
Ao analisar os resultados, é útil conhecer suas prioridades. Algumas perguntas comuns:
- Você está buscando uma alta taxa de transferência de token por usuário?
- Você está processando grandes quantidades de texto e precisa da maior taxa de transferência possível?
- Você quer que o primeiro token retorne rapidamente?
O ajuste que você estabelece depende muito do cenário que você deseja priorizar. Para esta postagem, vamos nos concentrar em otimizar a experiência por usuário. Queremos priorizar a métrica Per User Output Speed ou a velocidade com que os tokens são retornados ao usuário após a conclusão da fase de contexto. Com trtllm-bench, você pode especificar o número máximo de solicitações pendentes usando –concurrency, o que permite restringir o número de usuários que seu sistema pode suportar.
Essa opção é útil para produzir várias curvas diferentes, que são cruciais ao pesquisar alvos de latência e taxa de transferência. Aqui está um conjunto de curvas baseadas no Llama-3.1 8B FP8 da NVIDIA e no Llama-3.1 8B FP16 da Meta geradas para um cenário ISL/OSL 128/128. Digamos que queremos utilizar o sistema o máximo possível, mas ainda queremos que um usuário experimente cerca de 50 tokens/segundo de velocidade de saída (cerca de 20 ms entre os tokens). Para avaliar a compensação entre o desempenho da GPU e a experiência do usuário, você pode plotar a taxa de transferência de saída por GPU em relação à velocidade de saída por usuário.
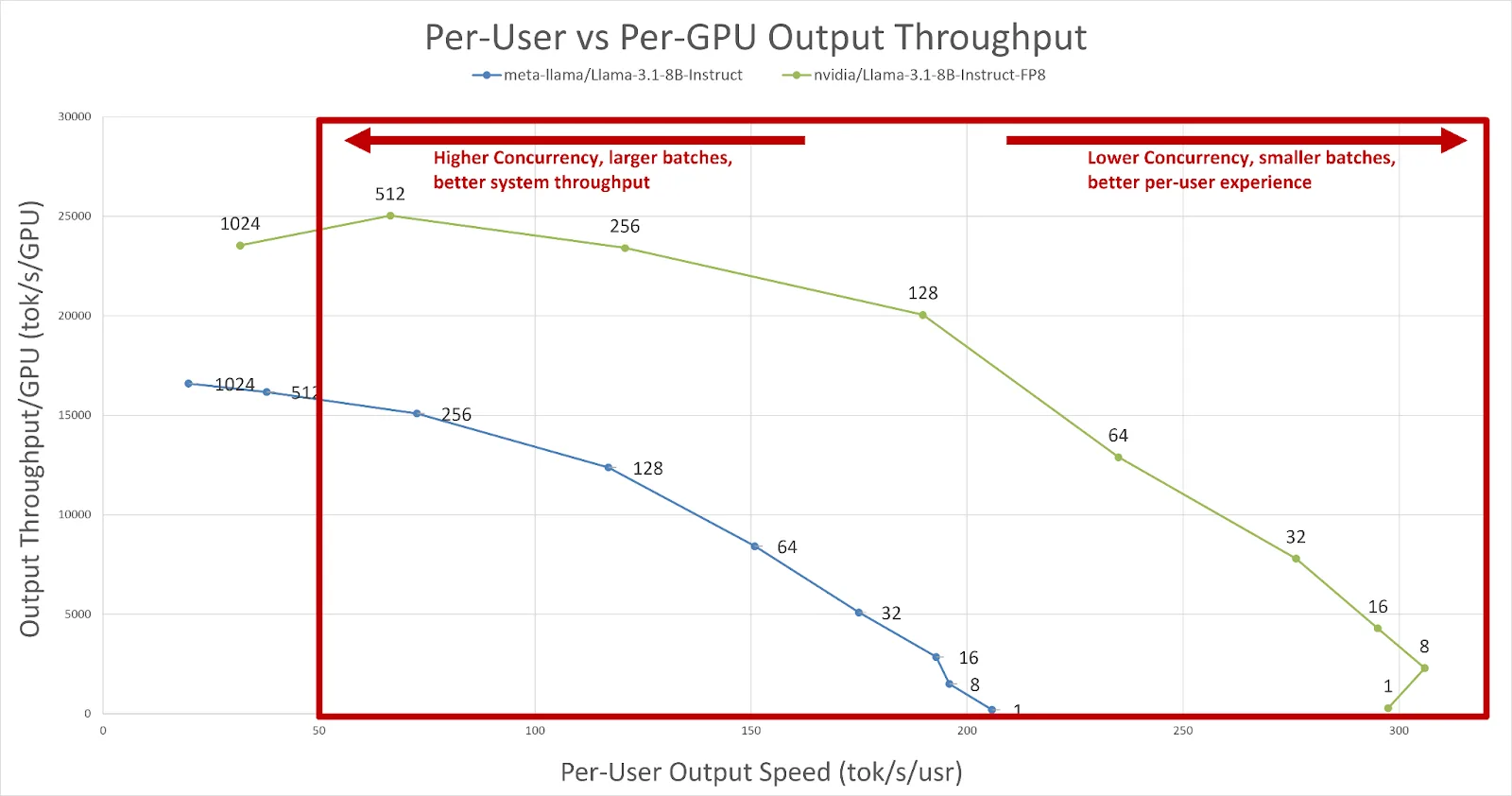
Figura 1. Uma comparação da velocidade de saída por usuário e da taxa de transferência de saída por GPU. Com base em nossos critérios, podemos ver que a taxa de transferência por GPU melhora à medida que a simultaneidade aumenta (melhor utilização do sistema); no entanto, à medida que o sistema se torna menos saturado, a velocidade de saída por usuário aumenta (melhor experiência).
Na Figura 1, podemos ver que o Llama-3.1 8B FP16 só pode lidar com cerca de 256 usuários simultâneos com aproximadamente 72 tokens/s/usuário antes de violar nossa restrição de 50 tokens/s/usuário. No entanto, se olharmos para o ponto de verificação otimizado Llama-3.1 8B FP8, vemos que o TensorRT-LLM pode lidar com 512 usuários simultâneos em aproximadamente 66 tokens/s/usuário. Podemos concluir que o modelo quantizado é capaz de atender mais usuários dentro do mesmo orçamento simplesmente varrendo ambos os modelos com trtllm-bench.
Com esses dados, você pode considerar o seguinte:
- Se você quiser forçar o mecanismo para 512 entradas, poderá definir o tamanho máximo do lote como 512; no entanto, isso corre o risco de aumentar o tempo para o primeiro token (TTFT) se o tráfego para essa instância exceder 512 (todas as solicitações além de 512 são enfileiradas).
- Você pode avaliar cenários e modelos de qualidade de serviço com outros conjuntos de dados usando trtllm-bench e plotar uma variedade de métricas. A ferramenta permite que você faça avaliações de valor com base em suas prioridades, ajustando a linha de comando de maneira simples de usar.
Observação: neste cenário, exploramos apenas um único modelo de GPU: se você tiver um modelo que exija várias GPUs, poderá configurar trtllm-bench usando as opções –tp, –pp e –ep para encontrar a melhor configuração paralela de fragmentos/dados. Além disso, se você for um desenvolvedor e precisar de recursos avançados, poderá usar o argumento –extra_llm_api_options.
Como Servir um Grande Modelo de Linguagem com trtllm-serve
O TensorRT-LLM oferece a capacidade de criar facilmente um endpoint compatível com OpenAI usando o comando trtllm-serve. Você pode usar o ajuste de trtllm-bench acima para ativar um servidor ajustado. Ao contrário do benchmark, trtllm-serve não faz suposições sobre a configuração além das configurações gerais. Para ajustar o servidor com base em nossos resultados de taxa de transferência máxima acima, você precisaria fornecer o seguinte comando com base na saída acima:
trtllm-serve serve nvidia/Llama-3.1-8B-Instruct-FP8 –backend pytorch –max_num_tokens 7680 –max_batch_size 3840 –tp_size 1 –extra_llm_api_options llm_api_options.yml
O –extra_llm_api_options fornece um mecanismo para alterar diretamente as configurações no nível da API do LLM. Para corresponder às configurações do benchmark, você precisará do seguinte em seu llm_api_options.yml:

Depois de configurado e executado, você verá uma atualização de status que o servidor está executando:

Com o servidor em execução, agora você pode comparar o modelo usando GenAI-Perf ou pode usar nossa versão portada do benchmark_serving.py. Isso pode ajudá-lo a verificar o desempenho da configuração do servidor ajustado. Em versões futuras, planejamos aumentar o trtllm-bench para poder criar um servidor otimizado para benchmarking.
Comece com Benchmarking e Ajuste de Desempenho para LLMs
Com o trtllm-bench, o TensorRT-LLM fornece uma maneira fácil de comparar uma variedade de configurações, ajustes, simultaneidade e recursos. As configurações de trtllm-bench são diretamente traduzíveis para a solução de veiculação nativa do TensorRT-LLM, trtllm-serve. Ele permite que você transfira perfeitamente seu ajuste de desempenho para uma implantação compatível com OpenAI.
Para obter informações mais detalhadas sobre desempenho, ajuste específico do modelo e ajuste/benchmarking do TensorRT-LLM, consulte os seguintes recursos:
- Para obter uma compreensão mais aprofundada das opções de desempenho disponíveis, consulte o Guia de Ajuste de Desempenho.
- Para obter a documentação do trtllm-bench, consulte nossa página de Benchmarking de Desempenho.
- Para ver como criar o perfil do TensorRT-LLM, a Análise de Desempenho abrange o uso do Nsight System para criar o perfil da execução do modelo.
- Para se aprofundar no ajuste de desempenho do DeepSeek-R1, confira o Guia de Ajuste de Desempenho do TensorRT-LLM para o DeepSeek-R1.
Confira os seguintes recursos:
- Para saber mais sobre como a arquitetura da plataforma pode afetar o TCO além de apenas FLOPS, você pode ler a postagem do blog “NVIDIA DGX Cloud Introduces Ready-To-Use Templates to Benchmark AI Platform Performance“. Veja também a coleção de receitas de benchmarking de desempenho (modelos prontos para uso) disponíveis para download no NGC aqui.
- Saiba como reduzir seu custo por token e maximizar os modelos de IA com o Guia do Líder de TI para Inferência e Desempenho de IA.