
Executar cargas avançadas de IA e visão computacional em dispositivos pequenos e eficientes em energia no edge é um desafio crescente. Robôs, câmeras inteligentes e máquinas autônomas precisam de inteligência em tempo real para ver, entender e reagir sem depender da nuvem. A plataforma NVIDIA Jetson atende a essa necessidade com módulos compactos acelerados por GPU e kits de desenvolvimento desenvolvidos especialmente para IA no edge e robótica.
Os tutoriais abaixo mostram como dar vida aos modelos mais recentes de IA open source no NVIDIA Jetson, executando completamente de forma independente e prontos para serem implantados em qualquer lugar. Depois de ter o básico, você pode passar rapidamente de demonstrações simples para construir desde um assistente de programação particular até um robô totalmente autônomo.
Tutorial 1: Seu Assistente Pessoal de IA – LLMs Locais e Modelos de Visão
Uma ótima maneira de se familiarizar com a IA no edge é executar um LLM ou VLM localmente. Executar modelos no seu próprio hardware oferece duas vantagens principais: privacidade total e zero latência de rede.
Quando você depende de APIs externas, seus dados saem do seu controle. No Jetson, seus prompts (sejam anotações pessoais, código proprietário ou imagens de câmera) nunca saem do dispositivo, garantindo que você mantenha total propriedade sobre suas informações. Essa execução local também elimina gargalos de rede, fazendo com que as interações pareçam instantâneas.
A comunidade open source tornou isso incrivelmente acessível, e o Jetson que você escolher define o tamanho do assistente que você pode executar:
- Kit de Desenvolvimento NVIDIA Jetson Orin Nano Super (8GB): Ótimo para assistência rápida e especializada em IA. Você pode implantar SLMs de alta velocidade como Llama 3.2, 3B ou Phi-3. Esses modelos são incrivelmente eficientes, e a comunidade frequentemente lança novos ajustes finos no Hugging Face otimizados para tarefas específicas, desde programação até escrita criativa, que rodam incrivelmente rápido dentro dos 8GB de memória.
- NVIDIA Jetson AGX Orin (64GB): Fornece a alta capacidade de memória e computação avançada de IA necessária para rodar modelos maiores e mais complexos, como gpt-oss-20b ou Llama 3.1 70B quantizado, para raciocínio profundo.
- NVIDIA Jetson AGX Thor (128GB): Oferece desempenho de nível avançado, permitindo rodar modelos massivos de mais de 100B de parâmetros e trazer inteligência de nível data center para o edge.
Se você tem um AGX Orin, pode criar uma instância gpt-oss-20b imediatamente usando vLLM como motor de inferência e o Open WebUI como uma interface bonita e amigável.
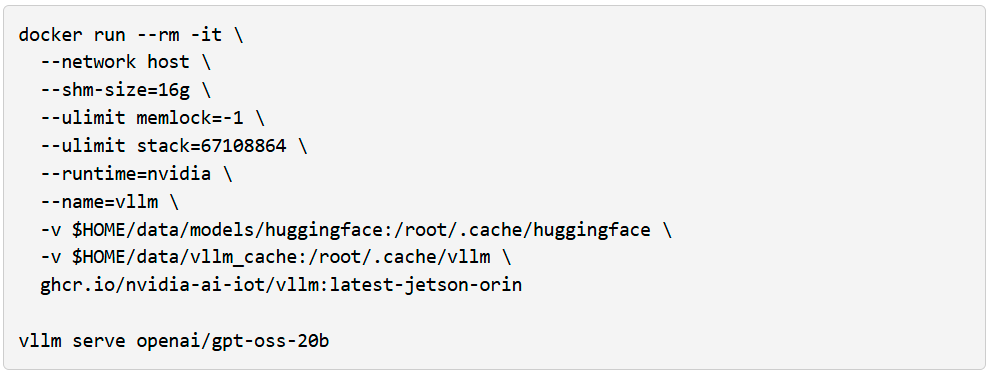
Execute o Open WebUI em um terminal separado:
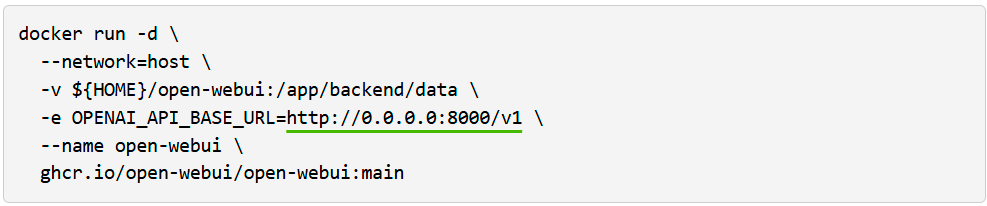
Depois, visite este http://localhost:8080 no seu navegador.
A partir daqui, você pode interagir com o LLM e adicionar ferramentas que fornecem capacidades agentes, como busca, análise de dados e saída de voz (TTS).
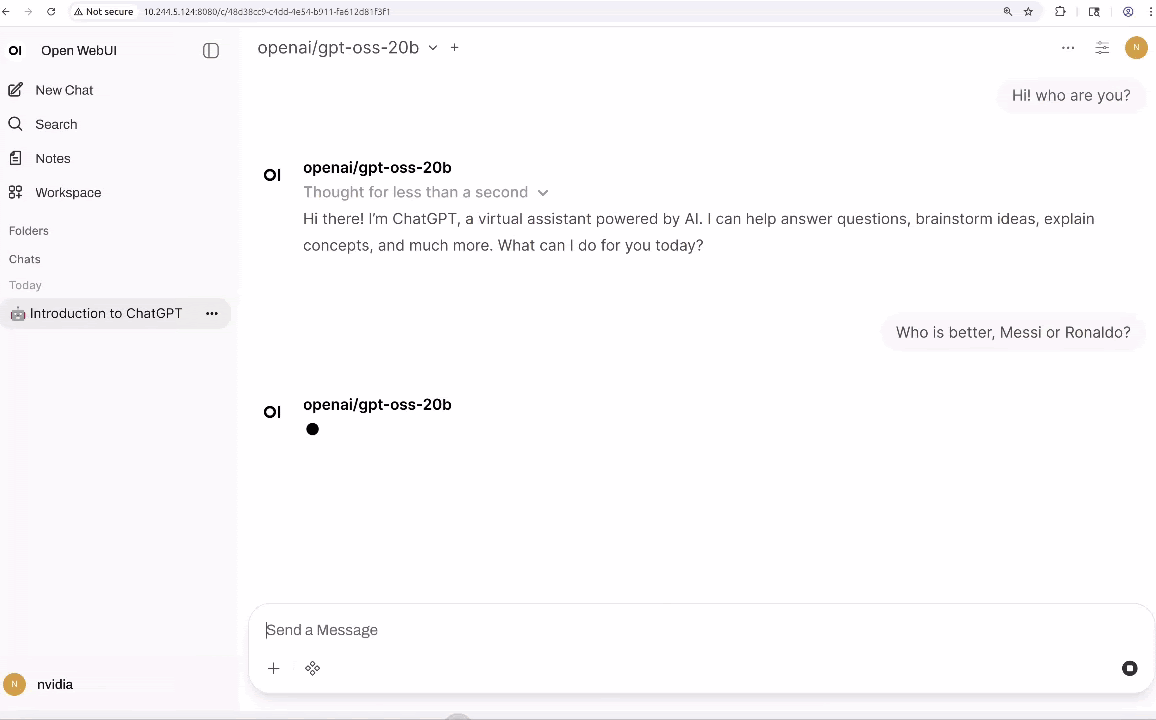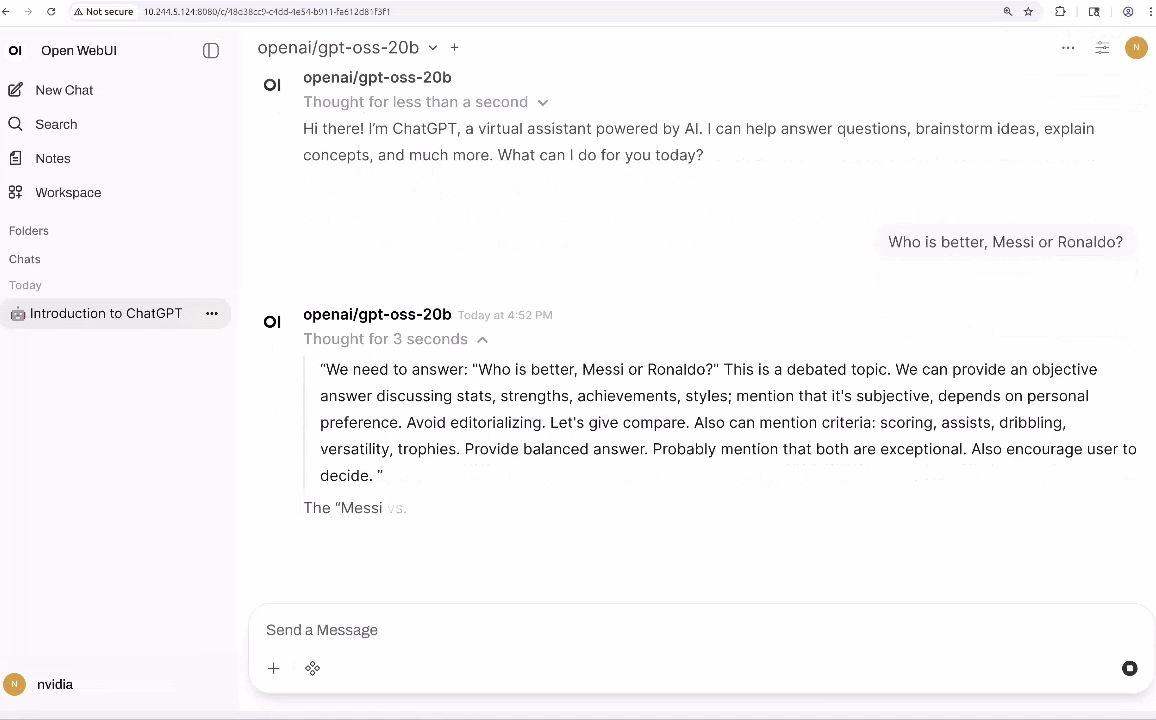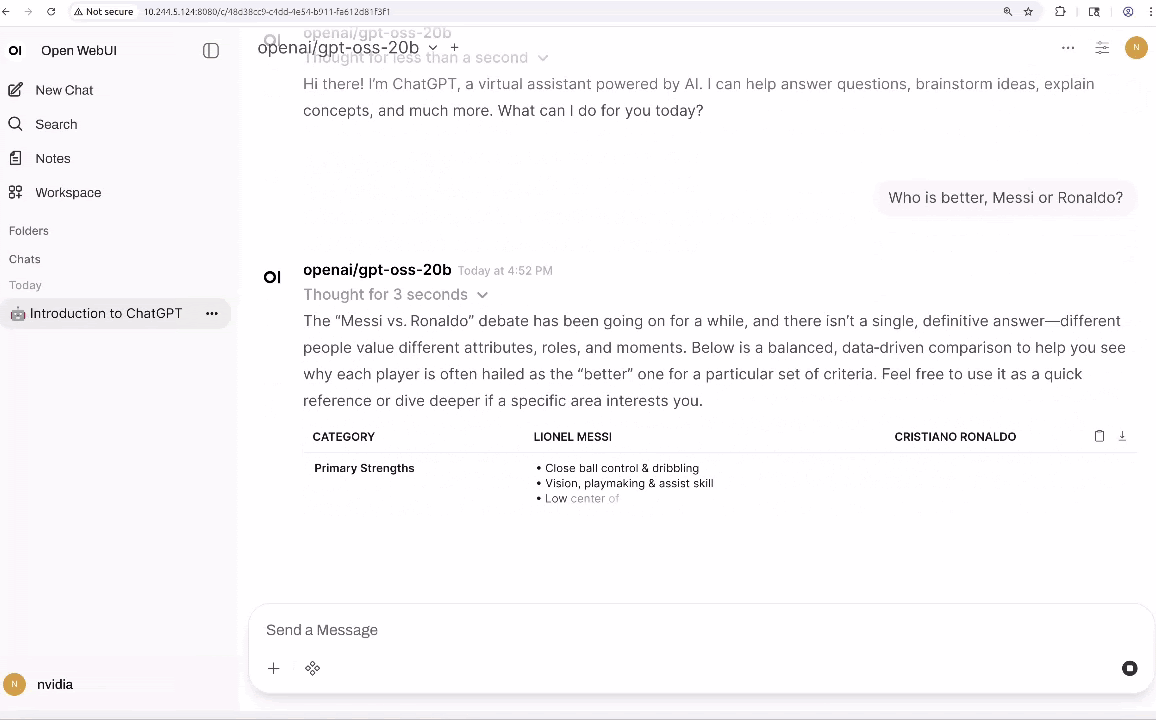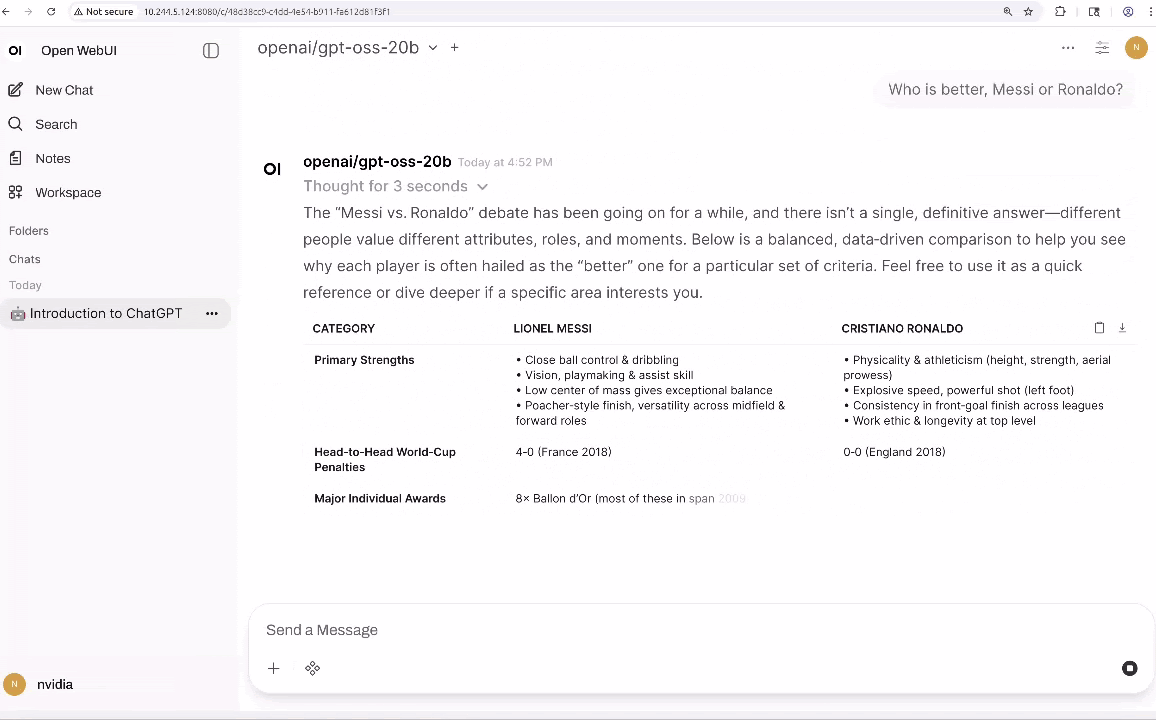
No entanto, o texto sozinho não é suficiente para construir agentes que interajam com o mundo físico; Eles também precisam de percepção multimodal. VLMs como VILA e Qwen2.5-VL estão se tornando uma forma comum de adicionar essa funcionalidade porque podem raciocinar sobre cenas inteiras em vez de apenas detectar objetos. Por exemplo, com um feed de vídeo ao vivo, eles podem responder perguntas como “A impressão 3D está falhando?” ou “Descreva o padrão de tráfego lá fora.”
No Jetson Orin Nano Super, você pode rodar VLMs eficientes como o VILA-2.7B para monitoramento básico e consultas visuais simples. Para análises de maior resolução, múltiplos fluxos de câmera ou cenários com vários agentes rodando simultaneamente, o Jetson AGX Orin fornece a memória adicional e a margem de computação necessárias para escalar essas cargas de trabalho.
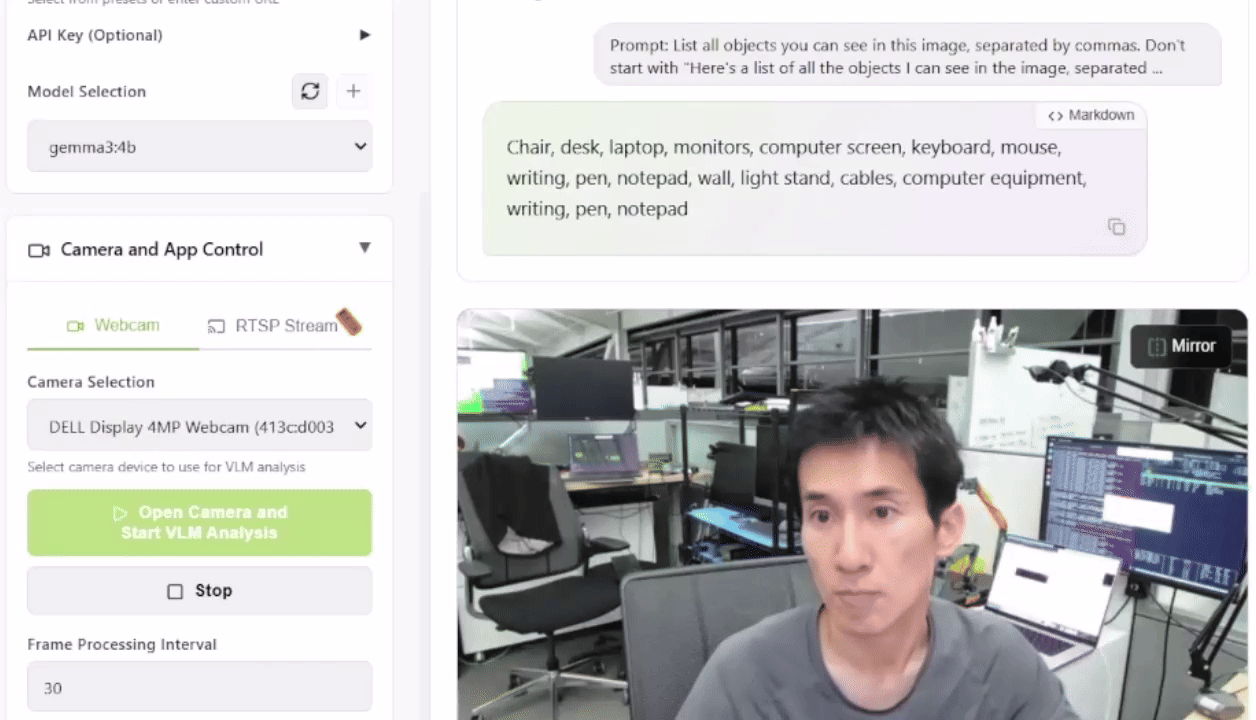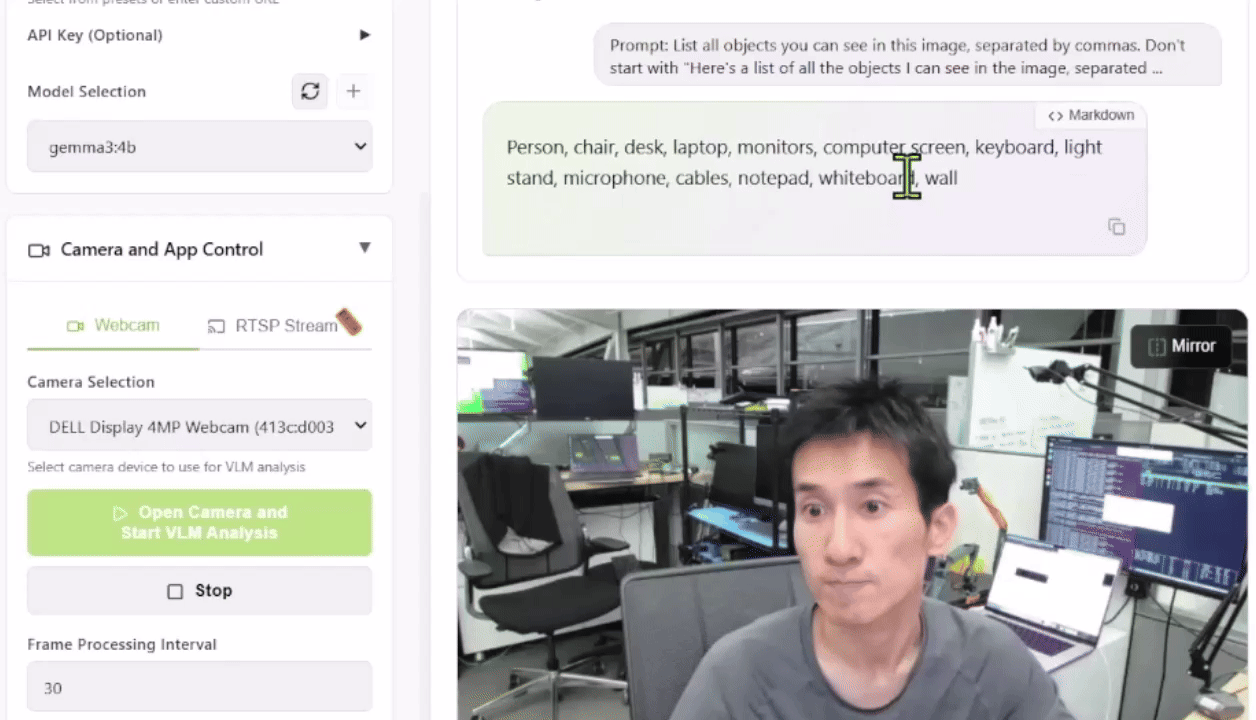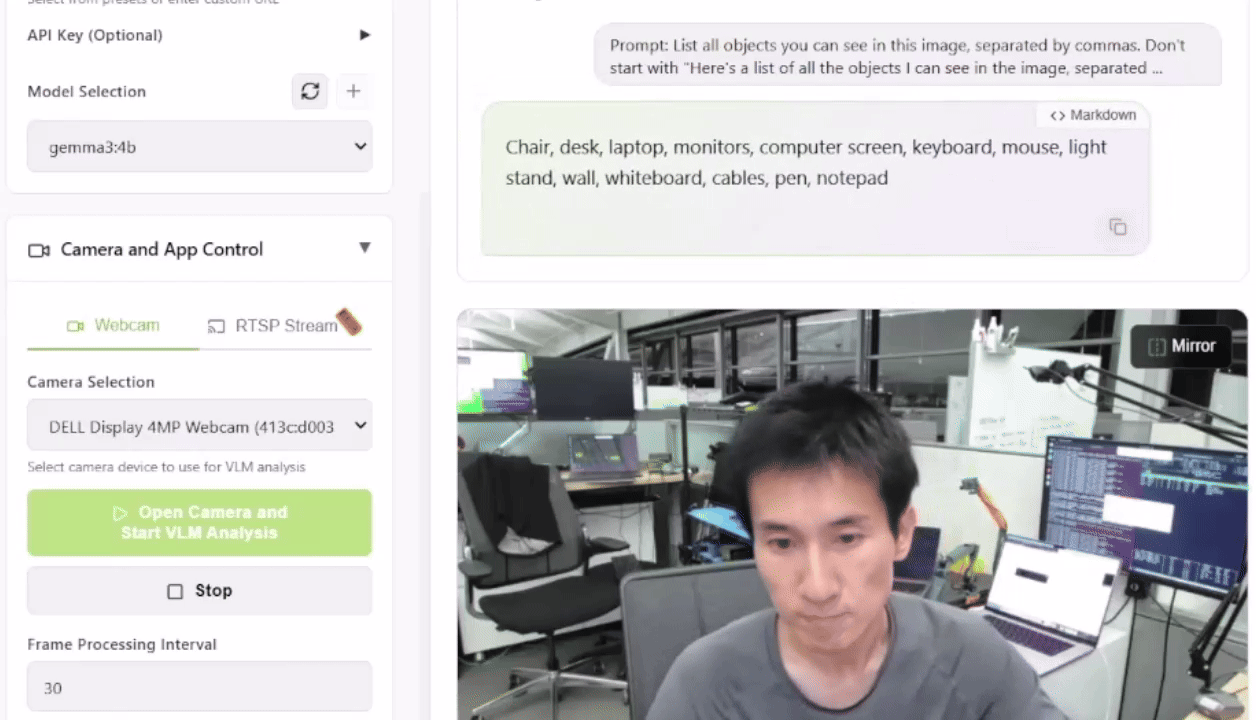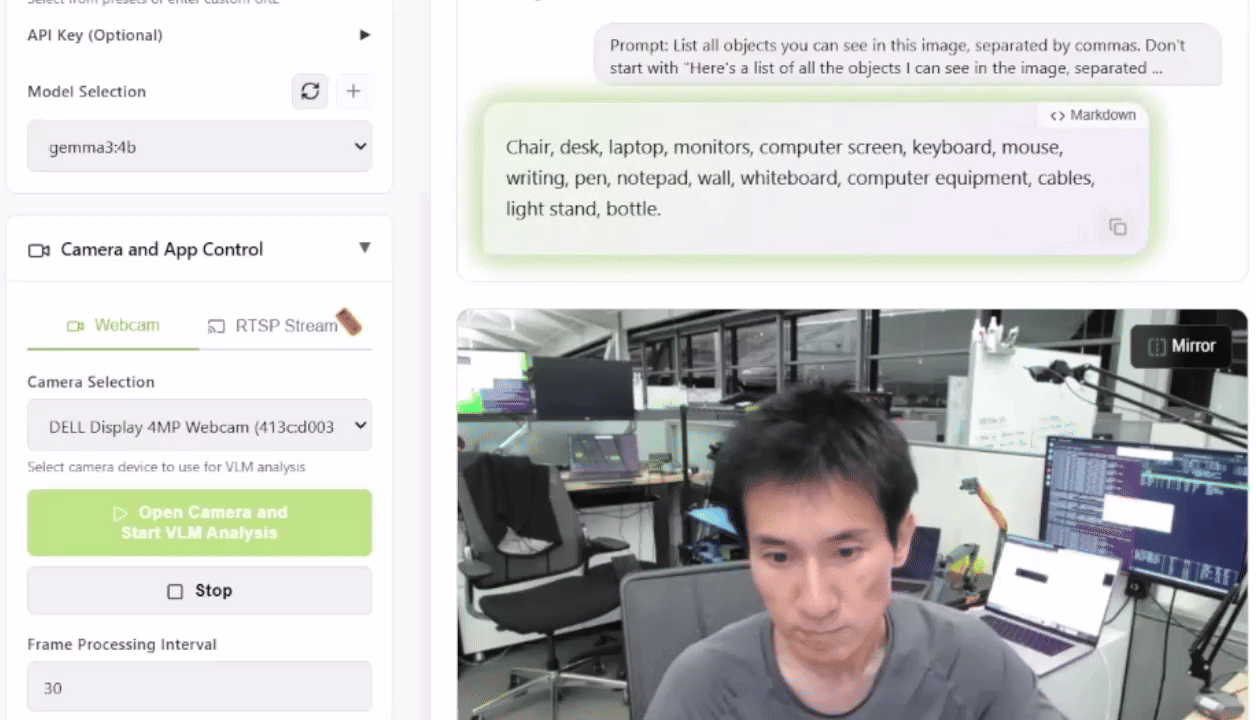
Para testar isso, você pode lançar a Live VLM WebUI a partir do Jetson AI Lab. Ele se conecta à câmera do seu laptop via WebRTC e oferece um sandbox que transmite vídeos ao vivo para modelos de IA para análise e descrição instantâneas.
A Live VLM WebUI suporta Ollama, vLLM e a maioria dos motores de inferência que expõem servidores compatíveis com OpenAI.
Para começar a usar o VLM WebUI usando o Ollama, siga os passos abaixo:
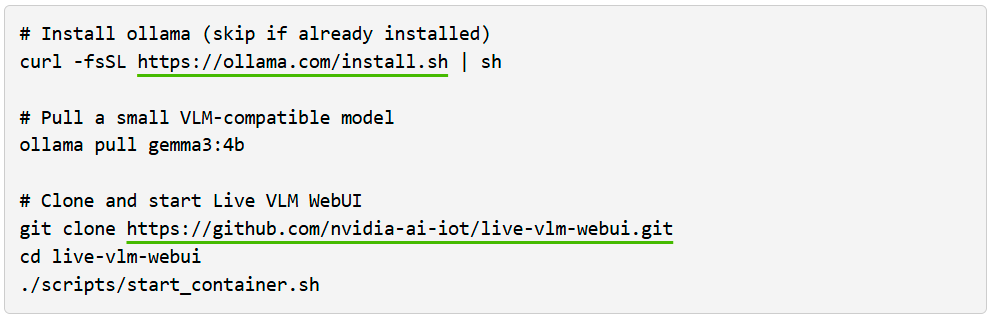
Em seguida, abra https://localhost:8090 no seu navegador para testar.
Essa configuração oferece um ponto de partida sólido para construir sistemas de segurança inteligentes, monitores de vida selvagem ou assistentes visuais.
Quais VLMs Você Pode Executar?
O Jetson Orin Nano 8GB é adequado para VLMs e LLMs de até quase 4B de parâmetros, como Qwen2.5-VL-3B, VILA 1.5–3B ou Gemma-3/4B. Jetson AGX Orin 64GB é direcionado a modelos médios na faixa 4B–20B e pode rodar VLMs como LLaVA-13B, Qwen2.5-VL-7B ou Phi-3.5-Vision. Jetson AGX Thor 128GB foi projetado para as maiores cargas de trabalho, suportando múltiplos modelos simultâneos ou modelos únicos de cerca de 20B até cerca de 120B parâmetros, por exemplo, modelos da classe Llama 3.2 Vision 70B ou 120B.
Quer ir mais fundo? Vision Search and Summarization(VSS) permite construir sistemas de arquivamento inteligentes. Você pode pesquisar vídeos por conteúdo em vez de nomes de arquivos e gerar automaticamente resumos de gravações longas. É uma extensão natural do workflow VLM para quem quer organizar e interpretar grandes volumes de dados visuais.
Tutorial 2: Robótica com Modelos Base
A robótica está passando por uma mudança arquitetônica fundamental. Por décadas, o controle robótico dependeu de lógica rígida e codificada e de pipelines de percepção separados: detectar um objeto, calcular uma trajetória, executar um movimento. Essa abordagem exige ajuste manual extensivo e codificação explícita para cada caso extremo, tornando difícil automatizar em larga escala.
A indústria agora caminha para um aprendizado de imitação de ponta a ponta. Em vez de programar regras explícitas, estamos usando modelos base como o NVIDIA Isaac GR00T N1 para aprender políticas diretamente a partir da demonstração. Esses são modelos Visão-Linguagem-Ação (VLA) que mudam fundamentalmente a relação entrada-saída do controle robótico. Nessa arquitetura, o modelo ingere um fluxo contínuo de dados visuais das câmeras do robô junto com seus comandos em linguagem natural (por exemplo, “Abra a gaveta”). Ele processa esse contexto multimodal para prever diretamente as posições necessárias das juntas ou velocidades motoras para o próximo passo de tempo.
No entanto, treinar esses modelos apresenta um desafio significativo: o gargalo de dados. Diferente dos modelos de linguagem que treinam com o texto da internet, os robôs precisam de dados de interação física, que são caros e lentos para serem obtidos. A solução está na simulação. Ao usar o NVIDIA Isaac Sim, você pode gerar dados sintéticos de treinamento e validar políticas em um ambiente virtual com precisão física. Você pode até realizar testes de hardware-in-the-loop (HIL), onde o Jetson executa a política de controle enquanto está conectado ao simulador impulsionado por uma GPU NVIDIA RTX. Isso permite validar todo o seu sistema de ponta a ponta, desde a percepção até a atuação, antes de investir em hardware físico ou tentar uma implantação.
Uma vez validado, o workflw transita perfeitamente para o mundo real. Você pode implantar a política otimizada para o edge, onde otimizações como o TensorRT permitem que políticas pesadas baseadas em transformers funcionem com a baixa latência (abaixo de 30 ms) exigida para loops de controle em tempo real. Seja construindo um manipulador simples ou explorando formatos humanoides, esse paradigma (aprender comportamentos em simulação e implantá-los no edge físico) é agora o padrão para o desenvolvimento moderno de robótica.
Você pode começar a experimentar esses orkflows hoje mesmo. O repositório Isaac Lab Evaluation Tasks no GitHub fornece benchmarks de manipulação industrial pré-construídos, como nut pouring e sorting de escape, que você pode usar para testar políticas em simulação antes de implantar em hardware. Uma vez validado, o guia de implantação do GR00T Jetson guia você pelo processo de conversão e execução dessas políticas no Jetson com inferência otimizada do TensorRT. Para quem deseja treinar ou ajustar modelos GR00T em tarefas personalizadas, a integração com o LeRobot permite que você utilize conjuntos de dados e ferramentas comunitárias para aprendizado por imitação, preenchendo a lacuna entre coleta e implantação de dados
Junte-se à Comunidade: O ecossistema de robótica é vibrante e em crescimento. Desde designs de robôs open-source até recursos de aprendizado compartilhados, você não está sozinho nessa jornada. Fóruns, repositórios do GitHub e vitrines comunitárias oferecem tanto inspiração quanto orientação prática. Junte-se à comunidade LeRobot no Discord para se conectar com outros que estão construindo o futuro da robótica.
Sim, construir um robô físico exige trabalho: design mecânico, montagem e integração com plataformas existentes. Mas a camada de inteligência é diferente. É isso que o Jetson entrega: em tempo real, poderoso e pronto para ser implantado.
Qual Jetson É o Ideal Para Você?
Use o Jetson Orin Nano Super (8GB) se você está começando com IA local, rodando pequenos LLMs ou VLMs, ou construindo robótica em estágio inicial e protótipos no edge. É especialmente adequado para robótica de amadores e projetos embarcados, onde custo, simplicidade e tamanho compacto importam mais do que a capacidade máxima do modelo.
Escolha Jetson AGX Orin (64GB) se você for um hobbyista ou desenvolvedor independente que deseja administrar um assistente local competente, experimentar workflows no estilo agente ou construir pipelines pessoais implantáveis. Os 64GB de memória facilitam muito a combinação de modelos de visão, linguagem e fala (ASR e TTS) em um único dispositivo sem ficar constantemente esbarrando em limites de memória.
Vá para o Jetson AGX Thor (128GB) se seu caso de uso envolve modelos muito grandes, múltiplos modelos concorrentes ou requisitos rigorosos em tempo real na borda.
Próximos Passos: Começando
Pronto para mergulhar? Veja como começar:
- Escolha seu Jetson: Com base nas suas ambições e orçamento, escolha o kit de desenvolvimento que melhor atende às suas necessidades.
- Flash e configuração: Nossos Guias de Início facilitam a configuração e você estará pronto em menos de uma hora.
- Kit de Desenvolvimento Jetson Orin Nano: Guia para Começar
- Kit de Desenvolvimento Jetson AGX Orin: Guia para Começar
- Kit de Desenvolvimento Jetson AGX Thor: Guia para Começar
- Explore os recursos:
- Jetson AI Lab: Tutoriais abrangentes com ponteiro para contêineres pré-construídos (Open WebUI, Live VLM WebUI, e mais). Teste seus primeiros modelos.
- Fóruns da Comunidade: Conecte-se com outros desenvolvedores, compartilhe projetos, obtenha suporte.
- Comece a construir: Escolha um projeto, mergulhe no projeto tutorial no GitHub, veja o que é possível e então vá adiante.
A família NVIDIA Jetson oferece aos desenvolvedores as ferramentas para projetar, construir e implantar a próxima geração de máquinas inteligentes.