
Dois meses após sua impressionante estreia nos benchmarks de inferência do MLPerf, as GPUs NVIDIA H100 Tensor Core estabeleceram recordes mundiais em cargas de trabalho de AI empresarial nos testes mais atuais de treinamento de AI do grupo do setor.
Juntos, os resultados mostram que a H100 é a melhor escolha para usuários que exigem o máximo desempenho para a criação e a implantação de modelos avançados de AI.
O MLPerf é o padrão do setor para medir o desempenho da AI. Ele é apoiado por um amplo grupo que inclui Amazon, Arm, Baidu, Google, Universidade de Harvard, Intel, Meta, Microsoft, Universidade de Stanford e a Universidade de Toronto.
Em um benchmark do MLPerf relacionado também lançado hoje, as GPUs NVIDIA A100 Tensor Core elevaram o nível que estabeleceram no ano passado para a computação de alto desempenho (HPC – High-Performance Computing).
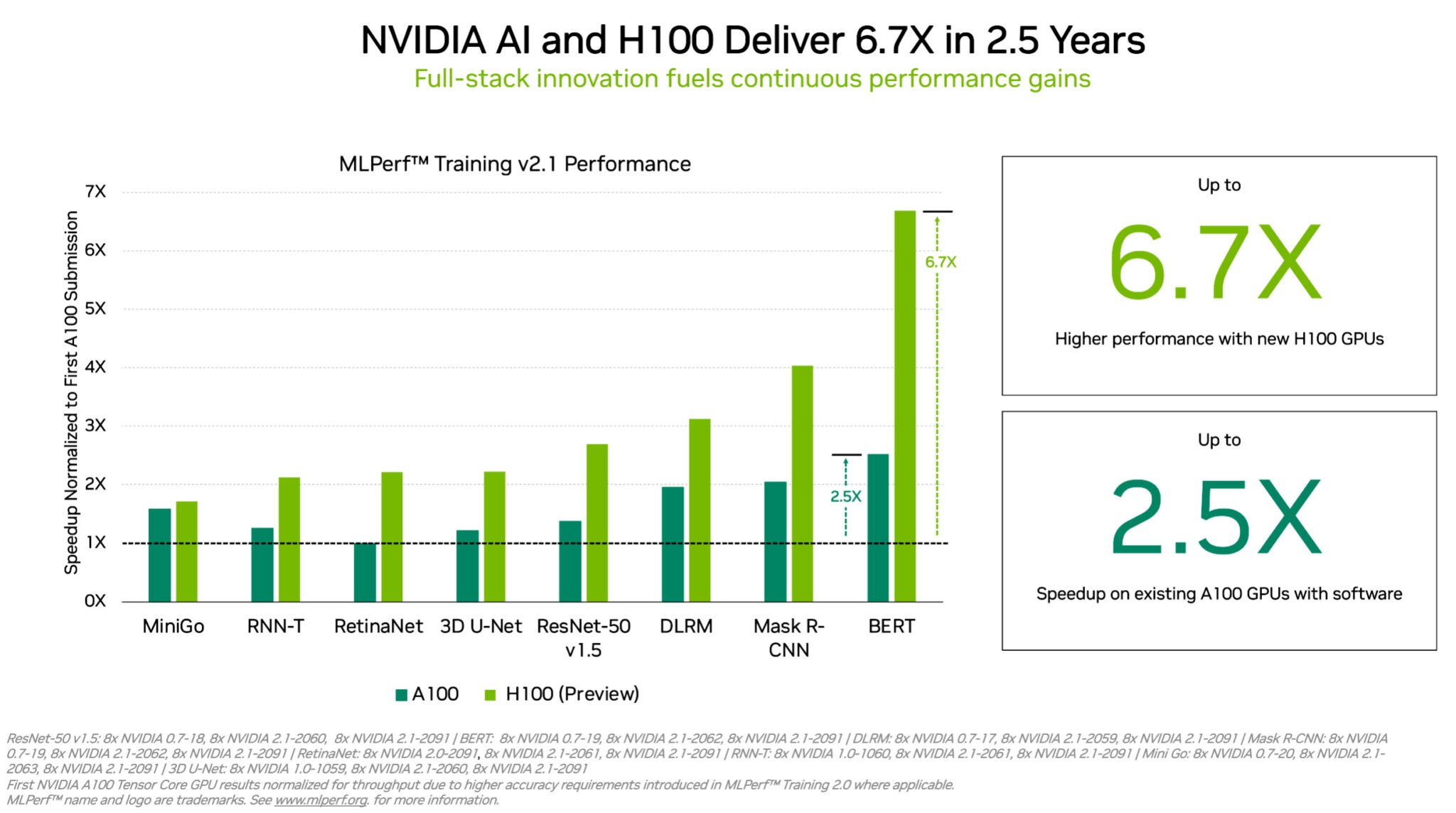
As GPUs H100 (também conhecidas como Hopper) elevaram o nível do desempenho por acelerador no Treinamento MLPerf. Elas ofereceram até 6,7 vezes mais desempenho do que as GPUs da geração anterior quando foram enviadas pela primeira vez para o Treinamento MLPerf. Na mesma comparação, as GPUs A100 atuais oferecem 2,5 vezes mais potência, graças aos avanços em software.
Devido, em parte, ao seu Engine Transformer, a Hopper apresentou um desempenho excelente no treinamento do popular modelo BERT para processamento de linguagem natural. Ele está entre os modelos de AI do MLPerf de maior tamanho e de mais alto desempenho.
O MLPerf proporciona aos usuários a confiança para tomar decisões de compra mais informadas, porque os benchmarks abrangem as cargas de trabalho de AI mais comuns de hoje, como visão computacional, processamento de linguagem natural, sistemas de recomendação, aprendizagem por reforço e muito mais. Os testes são revisados por pares, para que os usuários possam confiar nos resultados.
As GPUs A100 Atingem Novo Marco em HPC
No conjunto separado de benchmarks de HPC do MLPerf, as GPUs A100 foram as melhores em todos os testes de treinamento de modelos de AI em cargas de trabalho científicas exigentes executadas em supercomputadores. Os resultados mostram a capacidade da plataforma de AI da NVIDIA de ser dimensionada para os desafios técnicos mais difíceis do mundo.
As GPUs A100, por exemplo, treinaram modelos de AI no teste do CosmoFlow para astrofísica 9 vezes mais rápido do que os melhores resultados de dois anos atrás, na primeira rodada do MLPerf de HPC. Nessa mesma carga de trabalho, a A100 também ofereceu um rendimento até 66 vezes maior por chip do que uma oferta alternativa.
Os benchmarks de HPC treinam modelos para trabalhos em astrofísica, previsão do tempo e dinâmica molecular. Eles estão entre várias áreas técnicas, como a descoberta de medicamentos, adotando a AI para promover a ciência.
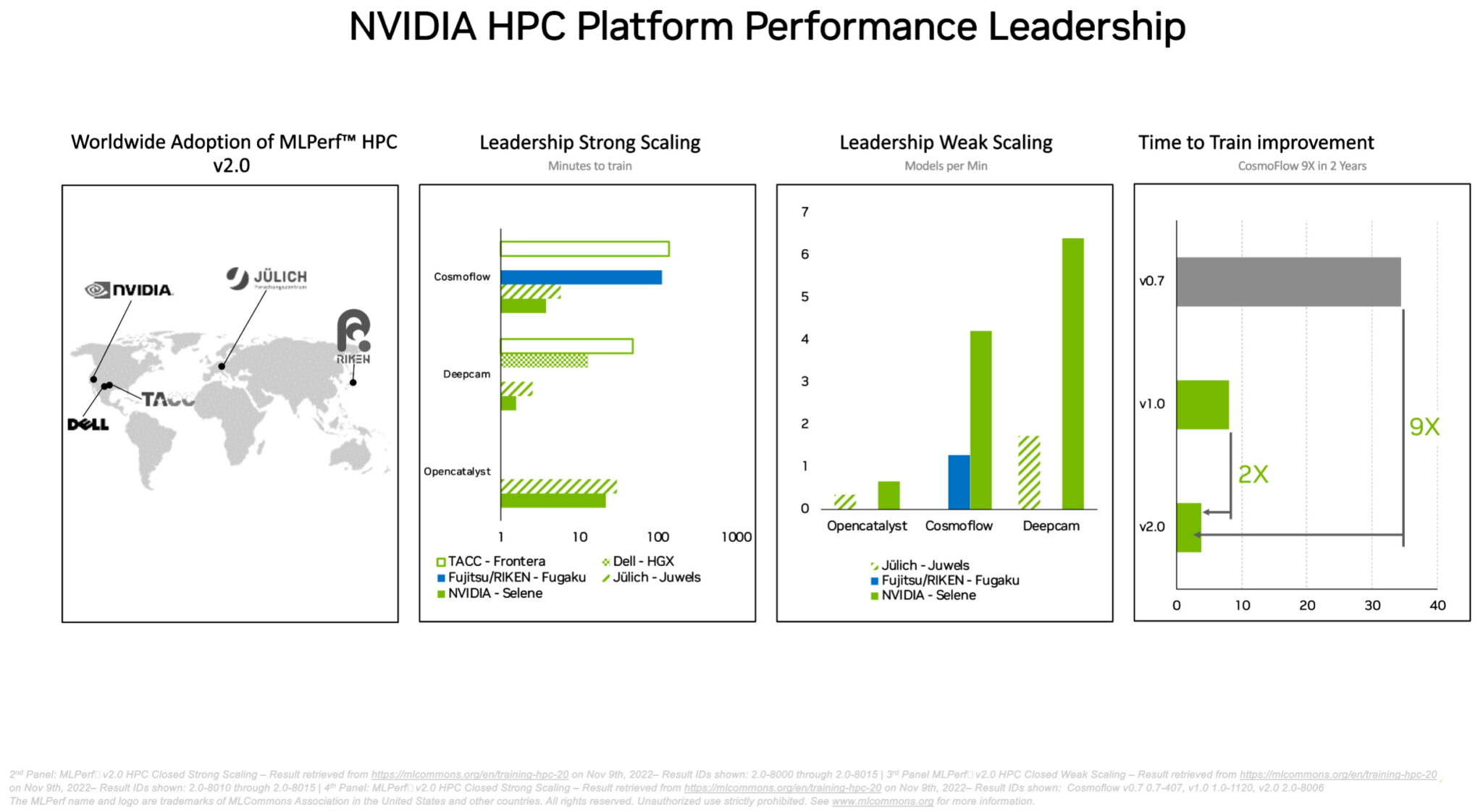
Centros de supercomputadores na Ásia, na Europa e nos EUA participaram da última rodada de testes de HPC do MLPerf. Em sua estreia nos benchmarks da DeepCAM, a Dell Technologies mostrou resultados fortes usando as GPUs NVIDIA A100.
Um Ecossistema Incomparável
Nos benchmarks de treinamento de AI empresarial, um total de 11 empresas, incluindo o serviço em cloud Azure da Microsoft, fizeram envios usando as GPUs NVIDIA A100, A30 e A40. Fabricantes de sistemas como ASUS, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Lenovo e Supermicro usaram um total de nove Sistemas Certificados pela NVIDIA para seus envios.
Na última rodada, pelo menos três empresas se juntaram à NVIDIA para enviar resultados de todas as oito cargas de trabalho do Treinamento MLPerf. Essa versatilidade é importante porque geralmente as aplicações do mundo real exigem um conjunto diverso de modelos de AI.
Os parceiros da NVIDIA participam do MLPerf porque sabem que é uma ferramenta importante para clientes que avaliam plataformas e fornecedores de AI.
Características Subjacentes
A plataforma de AI da NVIDIA fornece um pacote completo de chips para sistemas, software e serviços. Isso possibilita melhorias contínuas de desempenho ao longo do tempo.
Os envios nos testes mais atuais de HPC, por exemplo, aplicaram um conjunto de otimizações e técnicas de software descritas em um artigo técnico. Juntos, eles reduziram o tempo de execução de um benchmark em 5x, de 101 minutos para apenas 22 minutos.
Um segundo artigo descreve como a NVIDIA otimizava sua plataforma para os benchmarks de AI empresarial. Por exemplo, usamos a NVIDIA DALI para carregar e pré-processar dados de forma eficiente para um benchmark de visão computacional.
Todos os softwares usados nos testes estão disponíveis no repositório do MLPerf, para que todos possam obter esses resultados superiores. A NVIDIA continuamente transforma essas otimizações em contêineres disponibilizados no NGC, um hub de softwares para aplicações de GPU.