Grandes modelos de linguagem (LLMs) são algoritmos de deep learning que são treinados em conjuntos de dados em escala de internet com centenas de bilhões de parâmetros. Os LLMs podem ler, escrever, codificar, desenhar e aumentar a criatividade humana para melhorar a produtividade em todos os setores e resolver os problemas mais difíceis do mundo.
Os LLMs são usados em uma ampla gama de indústrias, do varejo à área da saúde, e para uma ampla gama de tarefas. Eles aprendem a linguagem das sequências de proteínas para gerar compostos novos e viáveis que podem ajudar os cientistas a desenvolver vacinas inovadoras que salvam vidas. Eles ajudam os programadores de software a gerar código e corrigir bugs com base em descrições de linguagem natural. E eles fornecem copilotos de produtividade para que os humanos possam fazer o que fazem de melhor: criar, questionar e entender.
O aproveitamento eficaz de LLMs em aplicações e workflows corporativos requer a compreensão de tópicos-chave, como seleção de modelos, personalização, otimização e implantação. Este post explora os seguintes tópicos de LLM empresarial:
- Como as empresas estão usando LLMs
- Usar, personalizar ou construir um LLM?
- Comece com modelos de base
- Criar um modelo de linguagem personalizado
- Conectar um LLM a dados externos
- Mantenha os LLMs seguros e no caminho certo
- Otimize a inferência de LLM na produção
- Introdução ao uso de LLMs
Se você é um cientista de dados que deseja criar modelos personalizados ou um diretor de dados que explora o potencial dos LLMs para sua empresa, continue lendo para obter insights e orientações valiosas.
Como as Empresas Estão Usando LLMs
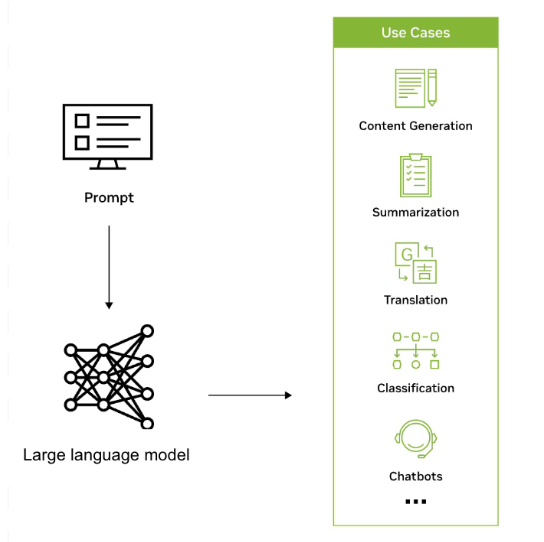
Os LLMs são usados em uma ampla variedade de aplicações em todos os setores para reconhecer, resumir, traduzir, prever e gerar texto e outras formas de conteúdo com base no conhecimento obtido de conjuntos de dados massivos. Por exemplo, as empresas estão aproveitando os LLMs para desenvolver interfaces semelhantes a chatbots que podem apoiar os usuários com consultas de clientes, fornecer recomendações personalizadas e ajudar no gerenciamento de conhecimento interno.
Os LLMs também têm o potencial de ampliar o alcance da IA em todos os setores e empresas e permitir uma nova onda de pesquisa, criatividade e produtividade. Eles podem ajudar a gerar soluções complexas para problemas desafiadores em áreas como área da saúde e química. Os LLMs também são usados para criar mecanismos de busca reimaginados, chatbots de tutorial, ferramentas de composição, materiais de marketing e muito mais.
A colaboração entre a ServiceNow e a NVIDIA ajudará a impulsionar novos níveis de automação para aumentar a produtividade e maximizar o impacto nos negócios. Os casos de uso de IA generativa que estão sendo explorados incluem o desenvolvimento de assistentes virtuais e agentes inteligentes para ajudar a responder às perguntas dos usuários e resolver solicitações de suporte e o uso de IA generativa para resolução automática de problemas, geração de artigos da base de conhecimento e resumo de bate-papo.
Um consórcio na Suécia está desenvolvendo um modelo de linguagem de última geração com o NVIDIA NeMo Megatron e o disponibilizará para qualquer usuário na região nórdica. A equipe pretende treinar um LLM com 175 bilhões de parâmetros que possam lidar com todos os tipos de tarefas linguísticas nas línguas nórdicas do sueco, dinamarquês, norueguês e, potencialmente, islandês.
O projeto é visto como um ativo estratégico, uma pedra angular da soberania digital em um mundo que fala milhares de idiomas em quase 200 países. Para saber mais, consulte Discurso Digno de Rei: Revolução da AI na Escandinávia.
A operadora móvel líder na Coreia do Sul, KT, desenvolveu um LLM de bilhões de parâmetros usando a plataforma NVIDIA DGX SuperPOD e o framework NVIDIA NeMo. O NeMo é um framework empresarial nativo da nuvem de ponta a ponta que fornece componentes pré-criados para criar, treinar e executar LLMs personalizados.
O LLM da KT foi usado para melhorar a compreensão do alto-falante impulsionados por IA da empresa, GiGA Genie, que pode controlar TVs, oferecer atualizações de tráfego em tempo real e concluir outras tarefas de assistência domiciliar com base em comandos de voz. Para obter detalhes, consulte Sem Travamentos com Hangul: KT Treina Alto-Falantes Inteligentes e Centrais de Atendimento ao Cliente com AI da NVIDIA.
Usar, Personalizar ou Construir um LLM?
As organizações podem optar por usar um LLM existente, personalizar um LLM pré-treinado ou criar um LLM personalizado do zero. O uso de um LLM existente fornece uma solução rápida e econômica, enquanto a personalização de um LLM pré-treinado permite que as organizações ajustem o modelo para tarefas específicas e incorporem conhecimento proprietário. Construir um LLM do zero oferece a maior flexibilidade, mas requer experiência e recursos significativos.
O NeMo oferece uma escolha de várias técnicas de personalização e é otimizado para inferência em escala de modelos para aplicações de linguagem e imagem, com configurações multi-GPU e multi-node. Para obter mais detalhes, consulte Unlocking the Power of Enterprise-Ready LLMs with NVIDIA NeMo.
O NeMo torna o desenvolvimento de modelos de IA generativa fácil, econômico e rápido para as empresas. Ele está disponível em todas as principais nuvens, incluindo o Google Cloud como parte de suas instâncias A3 alimentadas por GPUs NVIDIA H100 Tensor Core para criar, personalizar e implantar LLMs em escala. Para saber mais, consulte Streamline Generative AI Development with NVIDIA NeMo on GPU-Accelerated Google Cloud.
Para experimentar rapidamente modelos de IA generativos, como o Llama 2, diretamente do seu navegador com uma interface fácil de usar, visite o NVIDIA AI Playground.
Comece com Modelos de Base
Os modelos de base são grandes modelos de IA treinados em enormes quantidades de dados não rotulados por meio de aprendizado auto-supervisionado. Exemplos incluem Llama 2, GPT-3 e Difusão Estável.
Os modelos podem lidar com uma ampla variedade de tarefas, como classificação de imagens, processamento de linguagem natural e resposta a perguntas, com notável precisão.
Esses modelos de base são o ponto de partida para a construção de modelos personalizados mais especializados e sofisticados. As empresas podem personalizar modelos de base usando dados rotulados específicos do domínio para criar modelos mais precisos e com reconhecimento de contexto para casos de uso específicos.
Os modelos de base geram um enorme número de respostas únicas a partir de um único prompt, gerando uma distribuição de probabilidade sobre todos os itens que poderiam seguir a entrada e, em seguida, escolhendo a próxima saída aleatoriamente a partir dessa distribuição. A randomização é ampliada pelo uso do contexto pelo modelo. Cada vez que o modelo gera uma distribuição de probabilidade, ele considera o último item gerado, o que significa que cada previsão impacta cada previsão que se segue.
O NeMo suporta modelos de base treinados pela NVIDIA, bem como modelos de comunidade como Llama 2, Falcon LLM e MPT. Você pode experimentar uma variedade de modelos de base otimizados da comunidade e da NVIDIA diretamente do seu navegador gratuitamente no NVIDIA AI Playground. Em seguida, você pode personalizar o modelo de base usando seus dados corporativos proprietários. Isso resulta em um modelo que é especialista em seu negócio e domínio.
Criar um Modelo de Idioma Personalizado
As empresas geralmente precisarão de modelos personalizados para adaptar os recursos de processamento de linguagem a seus casos de uso específicos e conhecimento de domínio. LLMs personalizados permitem que uma empresa gere e compreenda texto de forma mais eficiente e precisa dentro de um determinado setor ou contexto empresarial. Eles capacitam as empresas a criar soluções personalizadas que se alinham com a voz de sua marca, otimizam workflows, fornecem insights mais precisos e oferecem experiências de usuário aprimoradas, impulsionando uma vantagem competitiva no mercado.
O NVIDIA NeMo é um framework poderoso que fornece componentes para a criação e treinamento de LLMs personalizados no local, em todos os principais provedores de serviços de nuvem ou no NVIDIA DGX Cloud. Ele inclui um conjunto de técnicas de personalização, desde o aprendizado imediato até o ajuste fino eficiente de parâmetros, até o aprendizado por reforço por meio de feedback humano (RLHF). A NVIDIA também lançou uma nova técnica de personalização aberta chamada SteerLM que permite o ajuste durante a inferência.
Ao treinar um LLM, há sempre o risco de ele se tornar “lixo dentro, lixo fora”. Uma grande porcentagem do esforço é adquirir e organizar os dados que serão usados para treinar ou personalizar o LLM.
O NeMo Data Curator é uma ferramenta escalável de curadoria de dados que permite a curadoria de conjuntos de dados multilíngues de trilhões de tokens para pré-treinamento de LLMs. A ferramenta permite pré-processar e eliminar a duplicação de conjuntos de dados com deduplicação exata ou difusa, para que você possa garantir que os modelos sejam treinados em documentos exclusivos, potencialmente levando a custos de treinamento muito reduzidos.
Conectar um LLM a Dados Externos
A conexão de um LLM a fontes de dados empresariais externas aprimora seus recursos. Isso permite que o LLM execute tarefas mais complexas e aproveite os dados criados desde que foi treinado pela última vez.
A Geração Aumentada de Recuperação (RAG) é uma arquitetura que fornece um LLM com a capacidade de usar fontes de dados atuais, selecionadas e específicas do domínio que são fáceis de adicionar, excluir e atualizar. Com o RAG, as fontes de dados externas são processadas em vetores (usando um modelo de incorporação) e colocadas em um banco de dados vetorial para recuperação rápida em tempo de inferência.
Além de reduzir os custos computacionais e financeiros, o RAG aumenta a precisão e permite aplicações mais confiáveis e alimentadas por IA. Acelerar a pesquisa vetorial é um dos tópicos mais quentes no cenário de IA devido às suas aplicações em LLMs e IA generativa.
Mantenha os LLMs Seguros e no Caminho Certo
Para garantir que o comportamento de um LLM esteja alinhado com os resultados desejados, é importante estabelecer diretrizes, monitorar seu desempenho e personalizar conforme necessário. Isso envolve definir limites éticos, abordar vieses nos dados de treinamento e avaliar regularmente os resultados do modelo em relação a métricas predefinidas, muitas vezes em conjunto com um recurso de guardrails. Para obter mais informações, consulte NVIDIA Enables Trustworthy, Safe, and Secure Large Language Model Conversational Systems.
Para atender a essa necessidade, a NVIDIA desenvolveu o NeMo Guardrails, um kit de ferramentas de código aberto que ajuda os desenvolvedores a garantir que suas aplicações de IA generativa sejam precisas, apropriadas e seguras. Ele fornece um framework que funciona com todos os LLMs, incluindo o ChatGPT da OpenAI, para tornar mais fácil para os desenvolvedores criar sistemas de conversação LLM seguros e confiáveis que aproveitam modelos básicos.
Manter os LLMs seguros é de suma importância para aplicações impulsionadas por IA generativa. A NVIDIA também introduziu a Computação Confidencial acelerada, um recurso de segurança inovador que mitiga ameaças enquanto fornece acesso à aceleração sem precedentes das GPUs NVIDIA H100 Tensor Core para cargas de trabalho de IA. Esse recurso garante que os dados confidenciais permaneçam seguros e protegidos, mesmo durante o processamento.
Otimize a Inferência de LLM na Produção
A otimização da inferência de LLM envolve técnicas como quantização de modelos, aceleração de hardware e estratégias de implantação eficientes. A quantização do modelo reduz o espaço ocupado pela memória do modelo, enquanto a aceleração de hardware aproveita hardware especializado, como GPUs, para inferência mais rápida. Estratégias de implantação eficientes garantem escalabilidade e confiabilidade em ambientes de produção.
NVIDIA TensorRT-LLM é uma biblioteca de software de código aberto que sobrecarrega a grande inferência LLM na computação acelerada NVIDIA. Ele permite que os usuários convertam seus pesos de modelo em um novo formato FP8 e compilem seus modelos para aproveitar os kernels FP8 otimizados com GPUs NVIDIA H100. O TensorRT-LLM pode acelerar o desempenho de inferência em 4,6 vezes em comparação com as GPUs NVIDIA A100. Ele fornece uma maneira mais rápida e eficiente de executar LLMs, tornando-os mais acessíveis e econômicos.
Esses processos personalizados de IA generativa envolvem a criação de modelos, frameworks, kits de ferramentas e muito mais. Muitas dessas ferramentas são de código aberto, demandando tempo e energia para manter os projetos de desenvolvimento. O processo pode se tornar incrivelmente complexo e demorado, especialmente ao tentar colaborar e implantar em vários ambientes e plataformas.
O NVIDIA AI Workbench ajuda a simplificar esse processo, fornecendo uma plataforma única para gerenciar dados, modelos, recursos e necessidades de computação. Isso permite colaboração e implantação perfeitas para que os desenvolvedores criem modelos econômicos e escaláveis de IA generativa rapidamente.
A NVIDIA e a VMware estão trabalhando juntas para transformar o data center moderno construído no VMware Cloud Foundation e levar a IA para todas as empresas. Usando o pacote NVIDIA AI Enterprise e as GPUs e unidades de processamento de dados (DPUs) mais avançadas da NVIDIA, os clientes VMware podem executar com segurança cargas de trabalho modernas e aceleradas ao lado de aplicações corporativas existentes nos Sistemas Certificados pela NVIDIA.
Comece a Usar os LLMs
Começar a usar LLMs requer fatores de ponderação, como custo, esforço, disponibilidade de dados de treinamento e objetivos de negócios. As empresas devem avaliar as compensações entre usar modelos existentes e personalizá-los com conhecimento específico do domínio versus criar modelos personalizados do zero na maioria das circunstâncias. É importante escolher ferramentas e frameworks que se alinhem a casos de uso e requisitos técnicos específicos, incluindo os listados abaixo.
O Laboratório de Chatbot da Base de Conhecimento de IA Generativa mostra como adaptar um modelo básico de IA existente para gerar respostas com precisão para seu caso de uso específico. Este laboratório gratuito fornece experiência prática com a personalização de um modelo usando aprendizado imediato, ingestão de dados em um banco de dados vetorial e encadeamento de todos os componentes para criar um chatbot.
O NVIDIA AI Enterprise, disponível em todas as principais plataformas de nuvem e data center, é um conjunto nativo de nuvem de software de IA e análise de dados que fornece mais de 50 frameworks, incluindo o frameworks NeMo, modelos pré-treinados e ferramentas de desenvolvimento otimizadas para infraestruturas de GPU aceleradas. Você pode experimentar este pacote de software completo pronto para empresas com uma avaliação gratuita de 90 dias.
O NeMo é um frameworks corporativo nativo da nuvem de ponta a ponta para desenvolvedores criarem, personalizarem e implantarem modelos de IA generativa com bilhões de parâmetros. Ele é otimizado para inferência em escala de modelos com configurações multi-GPU e multi-node. O frameworks torna o desenvolvimento de modelos de IA generativo fácil, econômico e rápido para as empresas. Explore os tutoriais do NeMo para começar.
O NVIDIA Training ajuda as empresas a treinar suas equipes de trabalho com a tecnologia mais recente e preencher a lacuna de habilidades, oferecendo workshops e cursos práticos técnicos abrangentes. O caminho de aprendizado de LLM desenvolvido por especialistas no assunto da NVIDIA abrange tópicos fundamentais e avançados que são relevantes para as equipes de engenharia de software e operações de IT. Os consultores de treinamento da NVIDIA estão disponíveis para ajudar a desenvolver planos de treinamento personalizados e oferecer preços para a equipe.