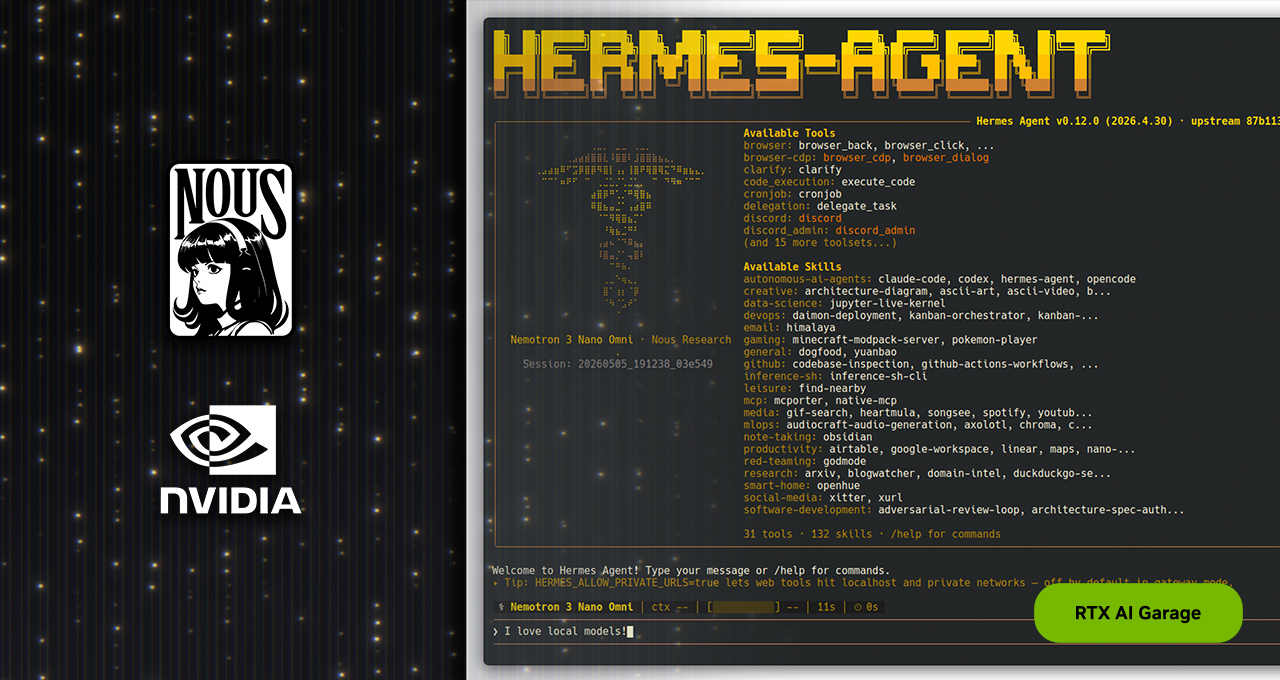
A IA agética está mudando a forma como os usuários realizam o trabalho. Após o sucesso do OpenClaw, a comunidade está adotando novas estruturas agéticas de código aberto. A mais recente é o Hermes Agent, que ultrapassou 140.000 estrelas no GitHub em menos de três meses e, na semana passada, era o agente mais usado no mundo, segundo o OpenRouter.
Desenvolvido pela Nous Research, o Hermes foi projetado para oferecer confiabilidade e autoaperfeiçoamento — duas qualidades que historicamente têm sido difíceis de alcançar com agentes. Ele é agnóstico em relação a provedores e modelos por natureza e otimizado para uso local contínuo, tornando os PCs com NVIDIA RTX, as workstations NVIDIA RTX PRO e o NVIDIA DGX Spark o hardware ideal para executá-lo em velocidade máxima, 24 horas por dia, 7 dias por semana.
O Qwen 3.6, uma nova série de modelos de linguagem de grande porte (LLMs) de alto desempenho e com pesos livres da Alibaba, é ideal para executar agentes locais como o Hermes. Os modelos de 27 bilhões e 35 bilhões de parâmetros do Qwen 3.6 superam seus equivalentes da geração anterior, com 120 bilhões e 400 bilhões de parâmetros, e são executados em NVIDIA RTX e DGX Spark para IA acelerada baseada em agentes.
Hermes: Capacidades de Agentes de IA Locais Aceleradas
Assim como outros agentes populares, o Hermes se integra a aplicativos de mensagens, pode acessar arquivos e aplicativos locais e funciona 24 horas por dia, 7 dias por semana. Mas quatro recursos excepcionais o diferenciam:
- Habilidades em Autodesenvolvimento: Hermes cria e aprimora suas próprias habilidades. Sempre que o agente se depara com uma tarefa complexa ou recebe feedback, ele salva o aprendizado como uma habilidade para que possa se adaptar e melhorar com o tempo.
- Subagentes isolados: O Hermes trata os subagentes como trabalhadores isolados e de curta duração, dedicados a uma subtarefa específica — com um contexto e um conjunto de ferramentas bem definidos. Isso mantém a organização das tarefas clara, minimiza a confusão para o agente e permite que o Hermes funcione com janelas de contexto menores, o que é ideal para modelos locais.
- Confiabilidade por design: a Nous Research seleciona e testa rigorosamente cada habilidade, ferramenta e plug-in que acompanha o Hermes. O resultado: o Hermes simplesmente funciona — mesmo com modelos locais de 30 bilhões de parâmetros — sem a necessidade de depuração constante exigida pela maioria das outras estruturas de agentes.
- Mesmo modelo, melhores resultados: comparações entre desenvolvedores usando modelos idênticos em diferentes frameworks mostram consistentemente resultados mais robustos no Hermes. A diferença está no framework: o Hermes é uma camada de orquestração ativa, não um mero encapsulamento, permitindo agentes persistentes no dispositivo em vez da execução tarefa por tarefa.
Tanto o agente Hermes quanto o LLM subjacente são desenvolvidos para serem executados localmente — o que significa que a qualidade do hardware determina diretamente a qualidade da experiência do usuário. As GPUs NVIDIA RTX são projetadas especificamente para esse tipo de carga de trabalho.
Qwen 3.6: Inteligência em nível de data center, localmente
Os mais recentes modelos do Qwen 3.6 baseiam-se na aclamada série Qwen 3.5 para oferecer mais um avanço para agentes de IA locais. O novo modelo Qwen 3.6 35B funciona com aproximadamente 20 GB de memória, enquanto supera os modelos de 120 bilhões de parâmetros, que exigem mais de 70 GB de memória.
Além disso, o Qwen 3.6 27B é um novo modelo denso com mais parâmetros ativos — atingindo a precisão de modelos com 400 bilhões de parâmetros, como o Qwen 3.5 397B, mas com um tamanho dez vezes menor. A execução em GPUs RTX de última geração proporciona ao modelo o poder computacional necessário para uma experiência ágil.
Esses modelos são ideais para agentes locais como o Hermes, e as GPUs NVIDIA e o DGX Spark são a maneira mais rápida de executá-los. Os Tensor Cores da NVIDIA aceleram a inferência de IA para oferecer maior taxa de transferência e menor latência — assim, o Hermes pode executar uma tarefa de várias etapas ou aprimorar uma de suas próprias habilidades em segundos, em vez de minutos.
DGX Spark: O computador agético sempre ativo
Agentes como o Hermes são projetados para funcionar continuamente — respondendo a solicitações, planejando tarefas complexas, executando de forma autônoma e aprimorando-se constantemente. O NVIDIA DGX Spark é o companheiro ideal — uma máquina independente, compacta e eficiente, criada para fluxos de trabalho contínuos com agentes, durante todo o dia.
Com 128 GB de memória unificada e 1 petaflop de desempenho de IA, o NVIDIA DGX Spark consegue executar modelos de combinação de especialistas com 120 bilhões de parâmetros o dia todo. E o novo modelo Qwen 3.6 35B oferece inteligência equivalente em um formato mais compacto — com maior velocidade e permitindo que os usuários executem cargas de trabalho simultâneas.
Para maximizar o desempenho e a facilidade de uso, leia o guia do Hermes DGX Spark. Além disso, inscreva-se nas próximas sessões práticas da série de IA agética “Construa Você Mesmo” da NVIDIA para aprender a criar agentes de IA autônomos com NemoClaw e OpenShell.
O NVIDIA DGX Spark está disponível para encomenda nos parceiros de fabricação da NVIDIA — visite o marketplace.
Primeiros passos com o Hermes em hardware NVIDIA
Executar o Hermes localmente em hardware NVIDIA é simples.
Visite o repositório do Hermes no GitHub para começar e combine-o com um modelo e ambiente de execução locais de sua preferência. Execute o Hermes juntamente com o Qwen 3.6 através do arquivo llama.cpp, LM Studio ou Ollama. O Hermes Agent já vem com suporte integrado para LM Studio e Ollama, oferecendo o caminho mais simples para um agente local.
Seja para um entusiasta local de IA explorando a fronteira dos agentes pessoais ou para um desenvolvedor criando ferramentas locais para seus fluxos de trabalho, o Hermes em hardware NVIDIA oferece uma base excepcionalmente capaz e confiável.
Fique ligado para mais novidades do RTX AI Garage sobre os modelos abertos e agentes mais recentes otimizados para hardware NVIDIA RTX.
#ParaQuemPerdeu: As últimas novidades do RTX AI Garage
 As GPUs NVIDIA RTX PRO oferecem geração de tokens até 3 vezes mais rápida ao executar modelos Qwen 3.6 com llama.cpp. Obtenha a capacidade de resposta em tempo real necessária para IA local, onde os agentes podem lidar com tarefas de várias etapas e aprimorar suas habilidades para manter os fluxos de trabalho contínuos.
As GPUs NVIDIA RTX PRO oferecem geração de tokens até 3 vezes mais rápida ao executar modelos Qwen 3.6 com llama.cpp. Obtenha a capacidade de resposta em tempo real necessária para IA local, onde os agentes podem lidar com tarefas de várias etapas e aprimorar suas habilidades para manter os fluxos de trabalho contínuos.
Os modelos Gemma 4 26B e 31B do Google agora estão disponíveis como checkpoints NVFP4 para um desempenho ainda mais rápido em GPUs NVIDIA Blackwell. Combine os checkpoints NVFP4 com os novos drafters de Multi-Token Prediction do Google para obter inferência até 3 vezes mais rápida com a mesma qualidade de saída, permitindo que o raciocínio de ponta seja executado localmente em GPUs NVIDIA.
A versão 3.5 do Mistral Medium , também lançada em abril, inclui atualizações de compatibilidade com llama.cpp e Ollama, permitindo que os usuários executem o programa em sistemas NVIDIA RTX PRO e DGX Spark.
 A NVIDIA lançou recentemente o NVIDIA NemoClaw, uma pilha de código aberto que otimiza as experiências do OpenClaw em dispositivos NVIDIA, aumentando a segurança e oferecendo suporte a modelos locais. O NemoClaw agora é compatível com o Subsistema Windows para Linux (WSL2), trazendo suporte para entusiastas e desenvolvedores na plataforma da Microsoft. Comece a usar o NemoClaw no DGX Spark com este guia passo a passo.
A NVIDIA lançou recentemente o NVIDIA NemoClaw, uma pilha de código aberto que otimiza as experiências do OpenClaw em dispositivos NVIDIA, aumentando a segurança e oferecendo suporte a modelos locais. O NemoClaw agora é compatível com o Subsistema Windows para Linux (WSL2), trazendo suporte para entusiastas e desenvolvedores na plataforma da Microsoft. Comece a usar o NemoClaw no DGX Spark com este guia passo a passo.
Conecte-se com a NVIDIA AI PC e mantenha-se informado assinando a newsletter de PCs RTX com IA.
Siga a NVIDIA Workstation no LinkedIn e no X.
Consulte o aviso referente às informações do produto de software.