O MLPerf continua sendo a medida definitiva para o desempenho da AI como um benchmark independente de terceiros. A plataforma de AI da NVIDIA tem consistentemente mostrado liderança em treinamento e inferência desde o início do MLPerf, incluindo os benchmarks MLPerf Inference 3.0 lançados hoje.
“Três anos atrás, quando apresentamos o A100, o mundo da AI era dominado pela visão computacional. A AI generativa chegou”, disse o fundador e CEO da NVIDIA, Jensen Huang.
“É exatamente por isso que construímos o Hopper, otimizado especificamente para GPT com o Transformer Engine. O MLPerf 3.0 de hoje destaca o Hopper oferecendo 4x mais desempenho do que o A100.
“O próximo nível de AI generativa requer uma nova infraestrutura de AI para treinar grandes modelos de linguagem com grande eficiência energética. Os clientes estão aumentando a escala do Hopper, construindo uma infraestrutura de AI com dezenas de milhares de GPUs Hopper conectadas por NVIDIA NVLink e InfiniBand.
“A indústria está trabalhando duro em novos avanços em AI generativa segura e confiável. Hopper está permitindo esse trabalho essencial”, disse ele.
Os resultados mais recentes do MLPerf mostram que a NVIDIA leva a inferência de AI a novos níveis de desempenho e eficiência do cloud até o edge.
Especificamente, as GPUs NVIDIA H100 Tensor Core executadas em sistemas DGX H100 apresentaram o mais alto desempenho em todos os testes de inferência de AI, o trabalho de executar redes neurais em produção. Graças às otimizações de software , as GPUs apresentaram ganhos de desempenho de até 54% desde sua estreia em setembro.
Na área da saúde, as GPUs H100 apresentaram um aumento de desempenho de 31% desde setembro no 3D-UNet, o benchmark MLPerf para imagens médicas.
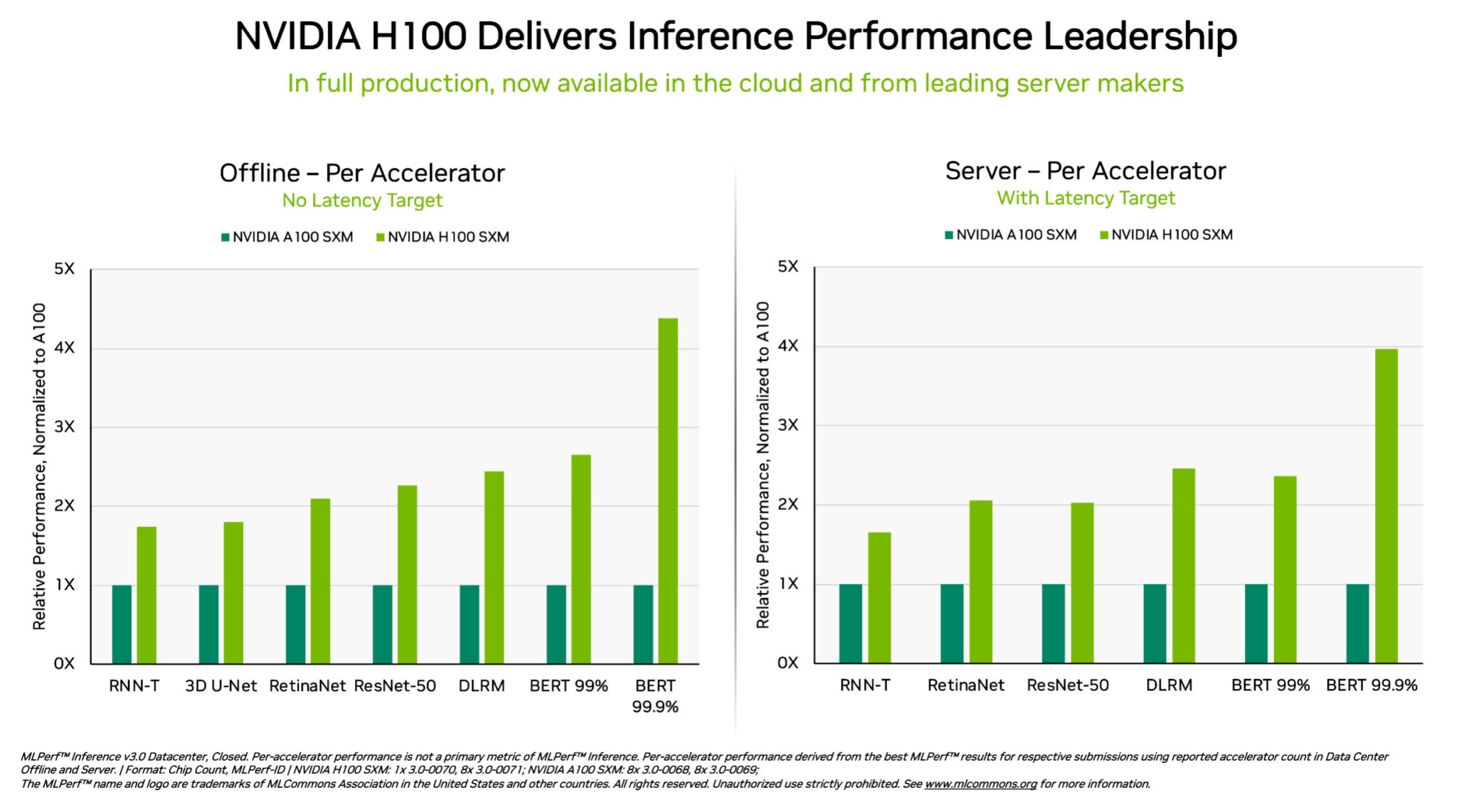
Impulsionado por seu Transformer Engine , a GPU H100, baseada na arquitetura Hopper, se destacou no BERT, um modelo de linguagem grande baseado em transformador que abriu o caminho para o amplo uso atual de AI generativa.
A AI generativa permite que os usuários criem rapidamente textos, imagens, modelos 3D e muito mais. É um recurso que as empresas, de startups a provedores de serviços em nuvem, estão adotando rapidamente para habilitar novos modelos de negócios e acelerar os existentes.
Centenas de milhões de pessoas agora estão usando ferramentas de AI generativas como o ChatGPT, também um modelo transformer, esperando respostas instantâneas.
Neste momento de AI do iPhone, o desempenho na inferência é vital. O deep learning agora está sendo implantado em quase todos os lugares, gerando uma necessidade insaciável de desempenho de inferência, desde o chão de fábrica até os sistemas de recomendação on-line .
GPUs L4 aceleram desde o início
As GPUs NVIDIA L4 Tensor Core fizeram sua estreia nos testes MLPerf com mais de 3x a velocidade das GPUs T4 da geração anterior. Empacotados em um fator de forma de baixo perfil, esses aceleradores são projetados para oferecer alta taxa de transferência e baixa latência em praticamente qualquer servidor.
As GPUs L4 executaram todos os workloads MLPerf. Graças ao seu suporte para o formato chave FP8, seus resultados foram particularmente impressionantes no modelo BERT com fome de desempenho.
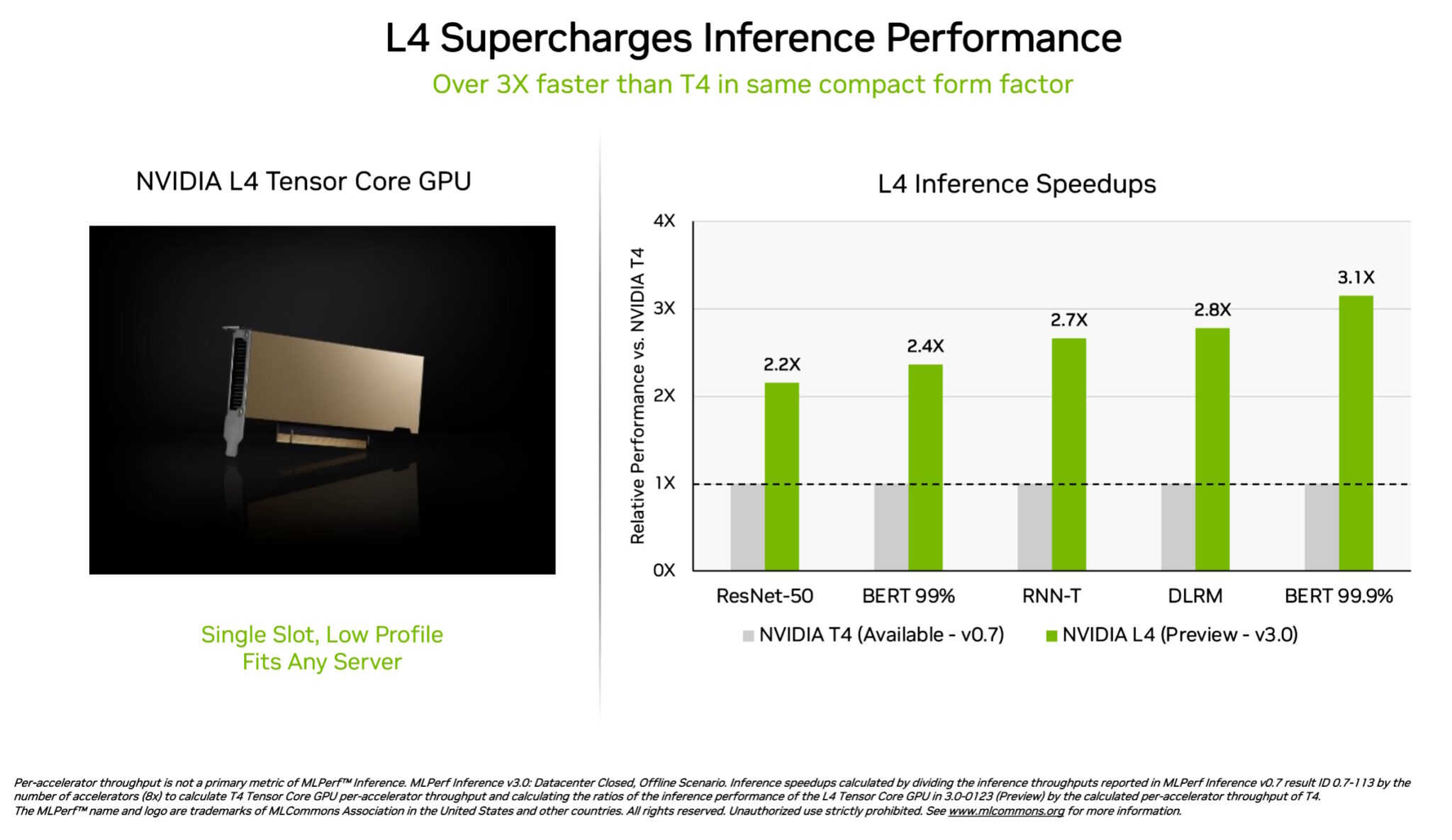
Além do excelente desempenho de AI, as GPUs L4 oferecem decodificação de imagem até 10x mais rápida, processamento de vídeo até 3,2x mais rápido e gráficos 4x mais rápidos e desempenho de renderização em tempo real.
Anunciados há duas semanas no GTC , esses aceleradores já estão disponíveis nos principais fabricantes de sistemas e provedores de serviços no cloud . As GPUs L4 são a mais recente adição ao portfólio de plataformas de inferência de AI da NVIDIA lançadas no GTC.
Software, redes brilham em teste de sistema
A plataforma full-stack AI da NVIDIA mostrou sua liderança em um novo teste MLPerf.
O chamado benchmark de divisão de rede transmite dados para um servidor de inferência remoto. Ele reflete o cenário popular de usuários corporativos executando trabalhos de AI no cloud com dados armazenados atrás de firewalls corporativos.
No BERT, os sistemas remotos NVIDIA DGX A100 forneceram até 96% de seu desempenho local máximo, em parte porque precisavam esperar que as CPUs concluíssem algumas tarefas. No teste ResNet-50 para visão computacional, tratado exclusivamente por GPUs, eles atingiram 100%.
Ambos os resultados se devem, em grande parte, à rede NVIDIA Quantum Infiniband , NVIDIA ConnectX SmartNICs e software como o NVIDIA GPUDirect .
Orin mostra ganhos de 3,2x no edge
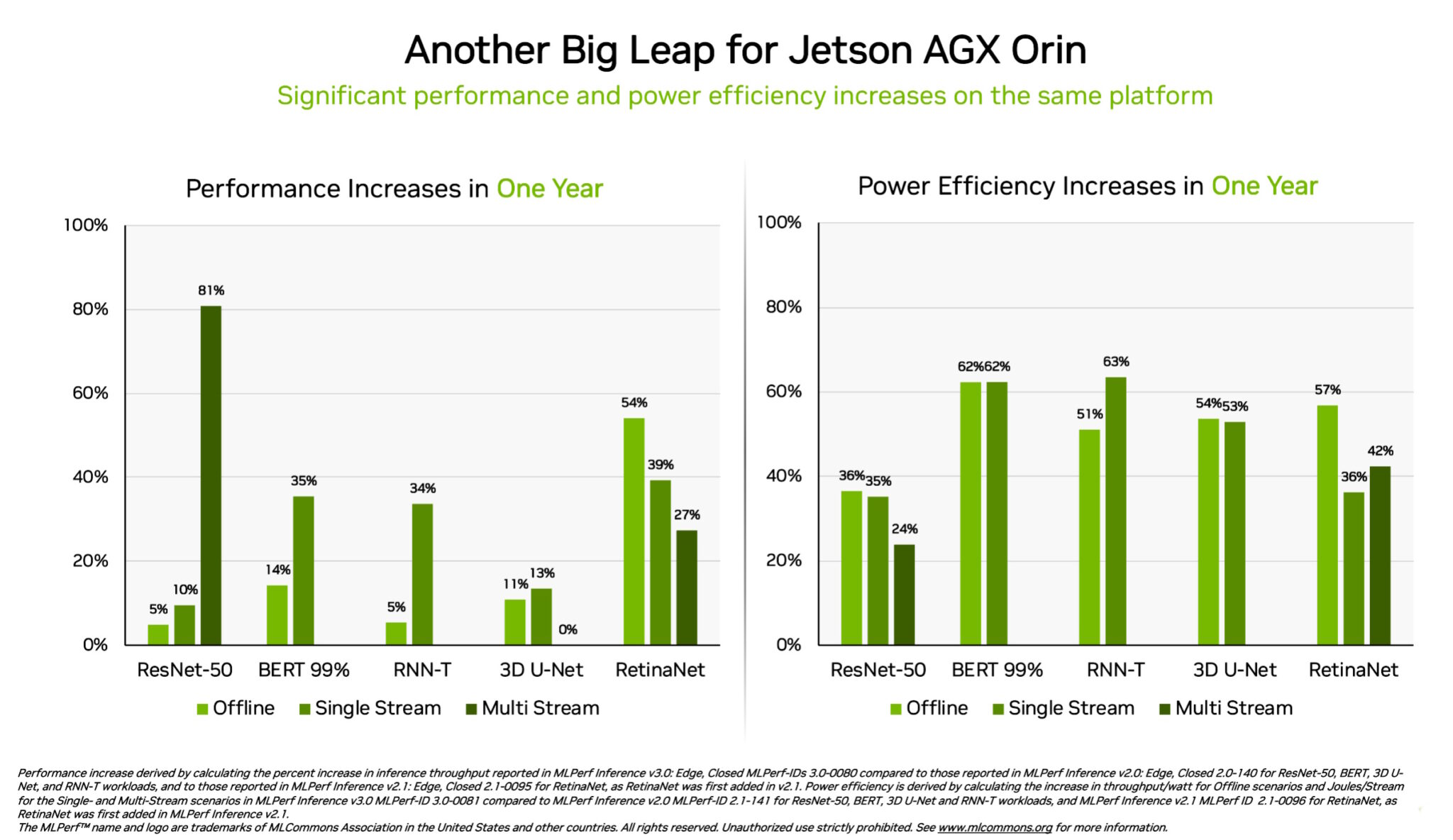
Separadamente, o sistema em módulo NVIDIA Jetson AGX Orin apresentou ganhos de até 63% em eficiência energética e 81% em desempenho em comparação com seus resultados do ano anterior. O Jetson AGX Orin fornece inferência quando a AI é necessária em espaços confinados com baixos níveis de energia, inclusive em sistemas alimentados por baterias.
Para aplicações que precisam de módulos ainda menores consumindo menos energia, o Jetson Orin NX 16G brilhou em sua estreia nos benchmarks. Ele forneceu até 3,2x o desempenho do processador Jetson Xavier NX da geração anterior.
Um amplo ecossistema de AI da NVIDIA
Os resultados do MLPerf mostram que a NVIDIA AI é apoiada pelo ecossistema mais amplo do setor em machine learning.
Dez empresas apresentaram resultados na plataforma NVIDIA nesta rodada. Eles vieram do serviço de cloud Microsoft Azure e fabricantes de sistemas, incluindo ASUS, Dell Technologies , GIGABYTE, New H3C Information Technologies, Lenovo , Nettrix, Supermicro e xFusion.
O trabalho deles mostra que os usuários podem obter um ótimo desempenho com a NVIDIA AI tanto no cloud quanto em servidores executados em seus próprios data centers.
Os parceiros da NVIDIA participam do MLPerf porque sabem que é uma ferramenta valiosa para clientes que avaliam plataformas e fornecedores de AI. Os resultados da última rodada demonstram que o desempenho que eles oferecem hoje crescerá com a plataforma NVIDIA.
Os usuários precisam de desempenho versátil
A NVIDIA AI é a única plataforma para executar todos os workloads e cenários de inferência MLPerf em data center e computação no edge. Seu desempenho versátil e eficiência tornam os usuários os verdadeiros vencedores.
Aplicações do mundo real geralmente empregam muitas redes neurais de diferentes tipos que geralmente precisam fornecer respostas em tempo real.
Por exemplo, uma aplicação de AI pode precisar entender a solicitação falada de um usuário, classificar uma imagem, fazer uma recomendação e, em seguida, entregar uma resposta como uma mensagem falada em voz humana. Cada etapa requer um tipo diferente de modelo de AI.
Os benchmarks MLPerf abrangem esses e outros workloads populares de AI. É por isso que os testes garantem que os tomadores de decisão de TI obtenham um desempenho confiável e flexível para implantar.
Os usuários podem confiar nos resultados do MLPerf para tomar decisões de compra informadas, pois os testes são transparentes e objetivos. Os benchmarks contam com o apoio de um amplo grupo que inclui Arm, Baidu, Facebook AI, Google, Harvard, Intel, Microsoft, Stanford e a Universidade de Toronto.
Software que você pode usar
A camada de software da plataforma NVIDIA AI, NVIDIA AI Enterprise , garante que os usuários obtenham desempenho otimizado de seus investimentos em infraestrutura, bem como suporte, segurança e confiabilidade de nível empresarial necessários para executar AI no data center corporativo.
Todo o software usado para esses testes está disponível no repositório MLPerf , para que qualquer pessoa possa obter esses resultados de primeira classe.
As otimizações são continuamente agrupadas em contêineres disponíveis no NGC , o catálogo da NVIDIA para software acelerado por GPU. O catálogo hospeda o NVIDIA TensorRT , usado por todos os envios nesta rodada para otimizar a inferência de AI.
Leia este blog técnico para saber mais sobre as otimizações que impulsionam o desempenho e a eficiência do MLPerf da NVIDIA.